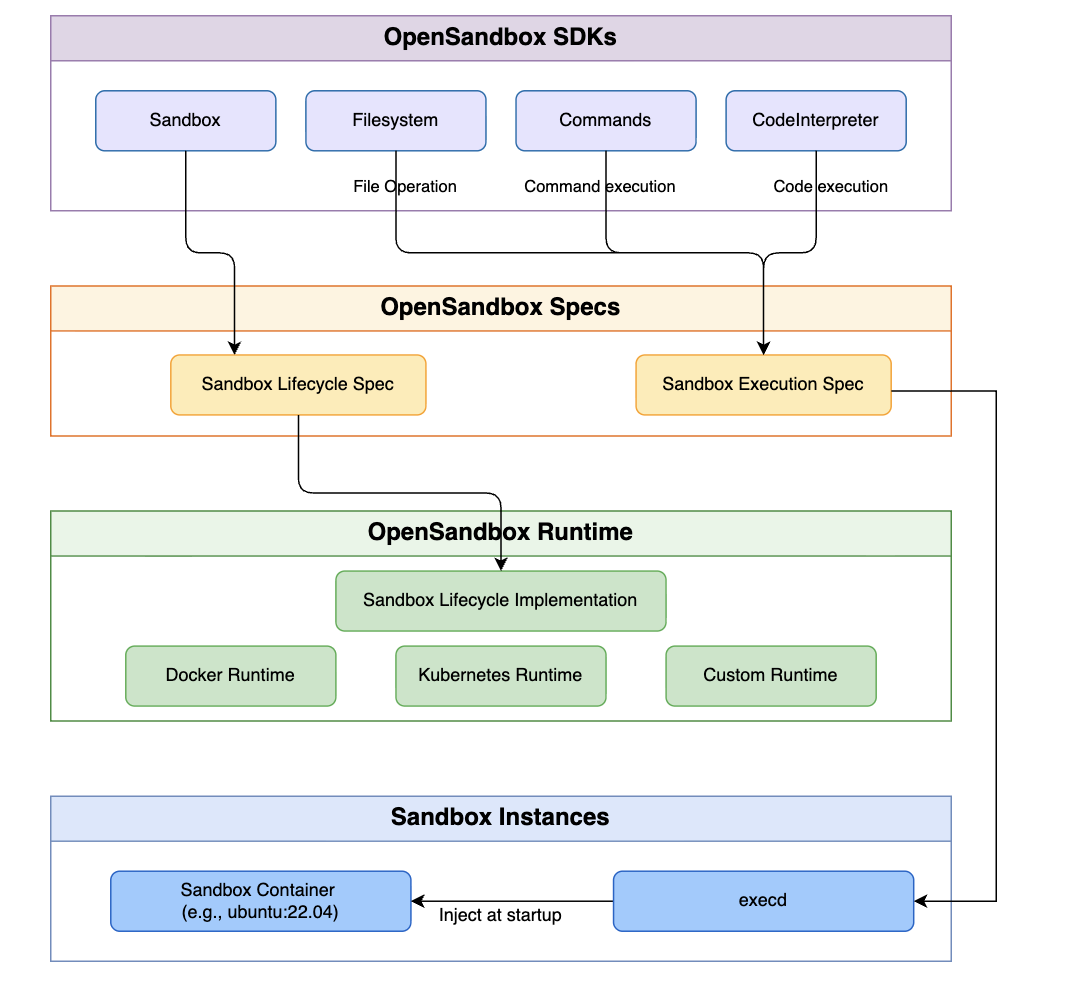
Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent ExecutionMarkTechPost Alibaba has released OpenSandbox, an open-source tool designed to provide AI agents with secure, isolated environments for code execution, web browsing, and model training. Released under the Apache 2.0 license, the proposed system targets to standardize the ‘execution layer’ of the AI agent stack, offering a unified API that functions across various programming languages and
The post Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent Execution appeared first on MarkTechPost.
Alibaba has released OpenSandbox, an open-source tool designed to provide AI agents with secure, isolated environments for code execution, web browsing, and model training. Released under the Apache 2.0 license, the proposed system targets to standardize the ‘execution layer’ of the AI agent stack, offering a unified API that functions across various programming languages and
The post Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent Execution appeared first on MarkTechPost. Read More

SkeleGuide: Explicit Skeleton Reasoning for Context-Aware Human-in-Place Image Synthesiscs.AI updates on arXiv.org arXiv:2603.01579v1 Announce Type: cross
Abstract: Generating realistic and structurally plausible human images into existing scenes remains a significant challenge for current generative models, which often produce artifacts like distorted limbs and unnatural poses. We attribute this systemic failure to an inability to perform explicit reasoning over human skeletal structure. To address this, we introduce SkeleGuide, a novel framework built upon explicit skeletal reasoning. Through joint training of its reasoning and rendering stages, SkeleGuide learns to produce an internal pose that acts as a strong structural prior, guiding the synthesis towards high structural integrity. For fine-grained user control, we introduce PoseInverter, a module that decodes this internal latent pose into an explicit and editable format. Extensive experiments demonstrate that SkeleGuide significantly outperforms both specialized and general-purpose models in generating high-fidelity, contextually-aware human images. Our work provides compelling evidence that explicitly modeling skeletal structure is a fundamental step towards robust and plausible human image synthesis.
arXiv:2603.01579v1 Announce Type: cross
Abstract: Generating realistic and structurally plausible human images into existing scenes remains a significant challenge for current generative models, which often produce artifacts like distorted limbs and unnatural poses. We attribute this systemic failure to an inability to perform explicit reasoning over human skeletal structure. To address this, we introduce SkeleGuide, a novel framework built upon explicit skeletal reasoning. Through joint training of its reasoning and rendering stages, SkeleGuide learns to produce an internal pose that acts as a strong structural prior, guiding the synthesis towards high structural integrity. For fine-grained user control, we introduce PoseInverter, a module that decodes this internal latent pose into an explicit and editable format. Extensive experiments demonstrate that SkeleGuide significantly outperforms both specialized and general-purpose models in generating high-fidelity, contextually-aware human images. Our work provides compelling evidence that explicitly modeling skeletal structure is a fundamental step towards robust and plausible human image synthesis. Read More

Build safe generative AI applications like a Pro: Best Practices with Amazon Bedrock GuardrailsArtificial Intelligence In this post, we will show you how to configure Amazon Bedrock Guardrails for efficient performance, implement best practices to protect your applications, and monitor your deployment effectively to maintain the right balance between safety and user experience.
In this post, we will show you how to configure Amazon Bedrock Guardrails for efficient performance, implement best practices to protect your applications, and monitor your deployment effectively to maintain the right balance between safety and user experience. Read More
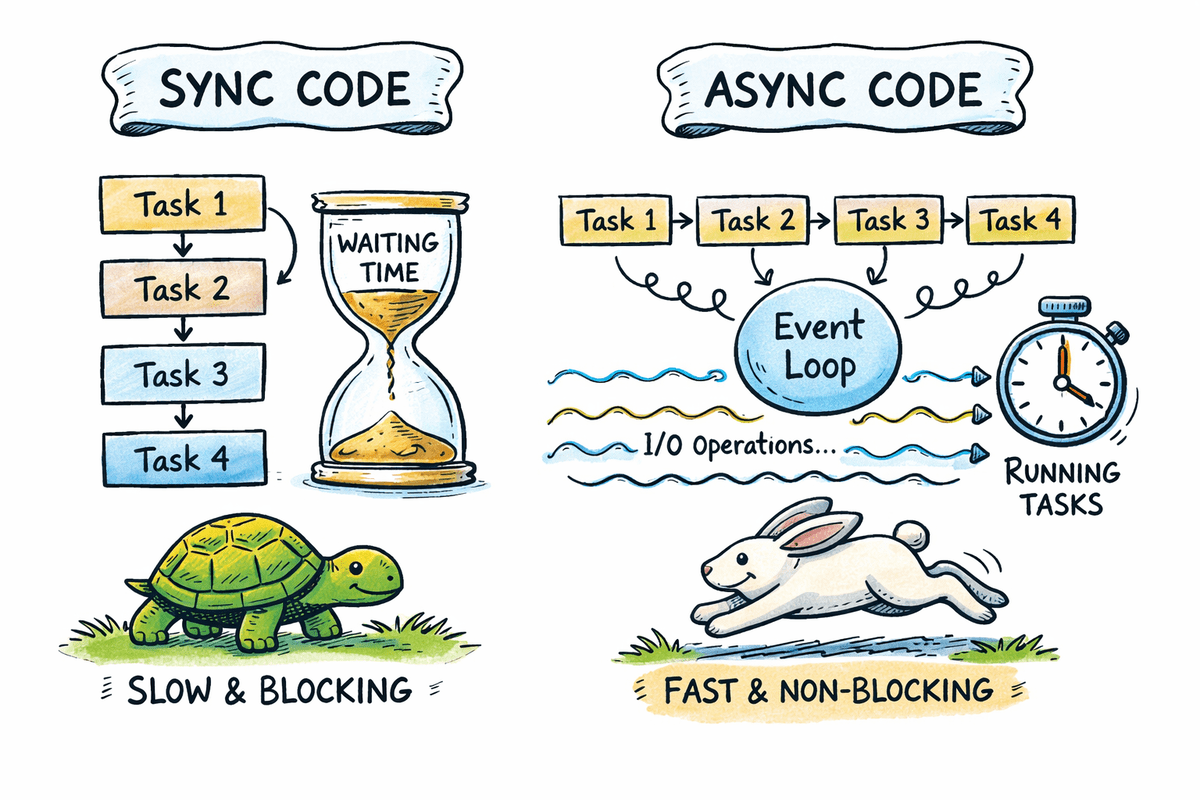
Getting Started with Python Async ProgrammingKDnuggets Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples.
Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples. Read More

Data Engineering for the LLM AgeKDnuggets Great LLMs need great data. Discover the pipelines, tools, and RAG architecture shaping the future of AI-ready data engineering
Great LLMs need great data. Discover the pipelines, tools, and RAG architecture shaping the future of AI-ready data engineering Read More
AI adoption in financial services has hit a point of no returnAI News AI adoption in financial services has effectively become universal–and the institutions still treating it as an experiment are now the outliers. According to Finastra’s Financial Services State of the Nation 2026 report, which surveyed 1,509 senior executives across 11 markets, only 2% of financial institutions globally report no use of AI whatsoever. The debate is
The post AI adoption in financial services has hit a point of no return appeared first on AI News.
AI adoption in financial services has effectively become universal–and the institutions still treating it as an experiment are now the outliers. According to Finastra’s Financial Services State of the Nation 2026 report, which surveyed 1,509 senior executives across 11 markets, only 2% of financial institutions globally report no use of AI whatsoever. The debate is
The post AI adoption in financial services has hit a point of no return appeared first on AI News. Read More
MWC 2026: SK Telecom lays out plan to rebuild its core around AIAI News At MWC 2026 in Barcelona, SK Telecom outlined how it is rebuilding itself around AI, from its network core to its customer service desks. The shift goes beyond adding new AI tools. It involves rewriting internal systems, expanding data centre capacity to the gigawatt scale, and upgrading its own large language model to more than
The post MWC 2026: SK Telecom lays out plan to rebuild its core around AI appeared first on AI News.
At MWC 2026 in Barcelona, SK Telecom outlined how it is rebuilding itself around AI, from its network core to its customer service desks. The shift goes beyond adding new AI tools. It involves rewriting internal systems, expanding data centre capacity to the gigawatt scale, and upgrading its own large language model to more than
The post MWC 2026: SK Telecom lays out plan to rebuild its core around AI appeared first on AI News. Read More
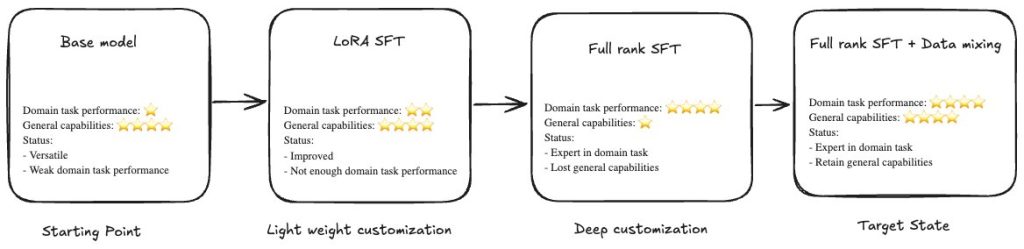
Building specialized AI without sacrificing intelligence: Nova Forge data mixing in actionArtificial Intelligence In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models.
In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models. Read More
Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two MillisecondsMarkTechPost In the current AI landscape, agentic frameworks typically rely on high-level managed languages like Python or Go. While these ecosystems offer extensive libraries, they introduce significant overhead through runtimes, virtual machines, and garbage collectors. NullClaw is a project that diverges from this trend, implementing a full-stack AI agent framework entirely in Raw Zig. By eliminating
The post Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two Milliseconds appeared first on MarkTechPost.
In the current AI landscape, agentic frameworks typically rely on high-level managed languages like Python or Go. While these ecosystems offer extensive libraries, they introduce significant overhead through runtimes, virtual machines, and garbage collectors. NullClaw is a project that diverges from this trend, implementing a full-stack AI agent framework entirely in Raw Zig. By eliminating
The post Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two Milliseconds appeared first on MarkTechPost. Read More
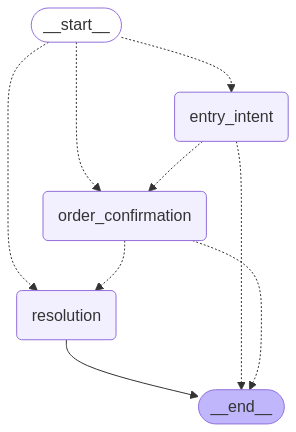
Build a serverless conversational AI agent using Claude with LangGraph and managed MLflow on Amazon SageMaker AIArtificial Intelligence This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.
This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI. Read More