
Generating Diverse TSP Tours via a Combination of Graph Pointer Network and Dispersioncs.AI updates on arXiv.org arXiv:2601.01132v2 Announce Type: replace-cross
Abstract: We address the Diverse Traveling Salesman Problem (D-TSP), a bi-criteria optimization challenge that seeks a set of $k$ distinct TSP tours. The objective requires every selected tour to have a length at most $c|T^*|$ (where $|T^*|$ is the optimal tour length) while minimizing the average Jaccard similarity across all tour pairs. This formulation is crucial for applications requiring both high solution quality and fault tolerance, such as logistics planning, robotics pathfinding or strategic patrolling. Current methods are limited: traditional heuristics, such as the Niching Memetic Algorithm (NMA) or bi-criteria optimization, incur high computational complexity $O(n^3)$, while modern neural approaches (e.g., RF-MA3S) achieve limited diversity quality and rely on complex, external mechanisms.
To overcome these limitations, we propose a novel hybrid framework that decomposes D-TSP into two efficient steps. First, we utilize a simple Graph Pointer Network (GPN), augmented with an approximated sequence entropy loss, to efficiently sample a large, diverse pool of high-quality tours. This simple modification effectively controls the quality-diversity trade-off without complex external mechanisms. Second, we apply a greedy algorithm that yields a 2-approximation for the dispersion problem to select the final $k$ maximally diverse tours from the generated pool. Our results demonstrate state-of-the-art performance. On the Berlin instance, our model achieves an average Jaccard index of $0.015$, significantly outperforming NMA ($0.081$) and RF-MA3S. By leveraging GPU acceleration, our GPN structure achieves a near-linear empirical runtime growth of $O(n)$. While maintaining solution diversity comparable to complex bi-criteria algorithms, our approach is over 360 times faster on large-scale instances (783 cities), delivering high-quality TSP solutions with unprecedented efficiency and simplicity.
arXiv:2601.01132v2 Announce Type: replace-cross
Abstract: We address the Diverse Traveling Salesman Problem (D-TSP), a bi-criteria optimization challenge that seeks a set of $k$ distinct TSP tours. The objective requires every selected tour to have a length at most $c|T^*|$ (where $|T^*|$ is the optimal tour length) while minimizing the average Jaccard similarity across all tour pairs. This formulation is crucial for applications requiring both high solution quality and fault tolerance, such as logistics planning, robotics pathfinding or strategic patrolling. Current methods are limited: traditional heuristics, such as the Niching Memetic Algorithm (NMA) or bi-criteria optimization, incur high computational complexity $O(n^3)$, while modern neural approaches (e.g., RF-MA3S) achieve limited diversity quality and rely on complex, external mechanisms.
To overcome these limitations, we propose a novel hybrid framework that decomposes D-TSP into two efficient steps. First, we utilize a simple Graph Pointer Network (GPN), augmented with an approximated sequence entropy loss, to efficiently sample a large, diverse pool of high-quality tours. This simple modification effectively controls the quality-diversity trade-off without complex external mechanisms. Second, we apply a greedy algorithm that yields a 2-approximation for the dispersion problem to select the final $k$ maximally diverse tours from the generated pool. Our results demonstrate state-of-the-art performance. On the Berlin instance, our model achieves an average Jaccard index of $0.015$, significantly outperforming NMA ($0.081$) and RF-MA3S. By leveraging GPU acceleration, our GPN structure achieves a near-linear empirical runtime growth of $O(n)$. While maintaining solution diversity comparable to complex bi-criteria algorithms, our approach is over 360 times faster on large-scale instances (783 cities), delivering high-quality TSP solutions with unprecedented efficiency and simplicity. Read More
Topological Signatures of ReLU Neural Network Activation Patternscs.AI updates on arXiv.org arXiv:2510.12700v2 Announce Type: replace-cross
Abstract: This paper explores the topological signatures of ReLU neural network activation patterns. We consider feedforward neural networks with ReLU activation functions and analyze the polytope decomposition of the feature space induced by the network. Mainly, we investigate how the Fiedler partition of the dual graph and show that it appears to correlate with the decision boundary — in the case of binary classification. Additionally, we compute the homology of the cellular decomposition — in a regression task — to draw similar patterns in behavior between the training loss and polyhedral cell-count, as the model is trained.
arXiv:2510.12700v2 Announce Type: replace-cross
Abstract: This paper explores the topological signatures of ReLU neural network activation patterns. We consider feedforward neural networks with ReLU activation functions and analyze the polytope decomposition of the feature space induced by the network. Mainly, we investigate how the Fiedler partition of the dual graph and show that it appears to correlate with the decision boundary — in the case of binary classification. Additionally, we compute the homology of the cellular decomposition — in a regression task — to draw similar patterns in behavior between the training loss and polyhedral cell-count, as the model is trained. Read More
CliCARE: Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Recordscs.AI updates on arXiv.org arXiv:2507.22533v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) hold significant promise for improving clinical decision support and reducing physician burnout by synthesizing complex, longitudinal cancer Electronic Health Records (EHRs). However, their implementation in this critical field faces three primary challenges: the inability to effectively process the extensive length and fragmented nature of patient records for accurate temporal analysis; a heightened risk of clinical hallucination, as conventional grounding techniques such as Retrieval-Augmented Generation (RAG) do not adequately incorporate process-oriented clinical guidelines; and unreliable evaluation metrics that hinder the validation of AI systems in oncology. To address these issues, we propose CliCARE, a framework for Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records. The framework operates by transforming unstructured, longitudinal EHRs into patient-specific Temporal Knowledge Graphs (TKGs) to capture long-range dependencies, and then grounding the decision support process by aligning these real-world patient trajectories with a normative guideline knowledge graph. This approach provides oncologists with evidence-grounded decision support by generating a high-fidelity clinical summary and an actionable recommendation. We validated our framework using large-scale, longitudinal data from a private Chinese cancer dataset and the public English MIMIC-IV dataset. In these settings, CliCARE significantly outperforms baselines, including leading long-context LLMs and Knowledge Graph-enhanced RAG methods. The clinical validity of our results is supported by a robust evaluation protocol, which demonstrates a high correlation with assessments made by oncologists.
arXiv:2507.22533v2 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) hold significant promise for improving clinical decision support and reducing physician burnout by synthesizing complex, longitudinal cancer Electronic Health Records (EHRs). However, their implementation in this critical field faces three primary challenges: the inability to effectively process the extensive length and fragmented nature of patient records for accurate temporal analysis; a heightened risk of clinical hallucination, as conventional grounding techniques such as Retrieval-Augmented Generation (RAG) do not adequately incorporate process-oriented clinical guidelines; and unreliable evaluation metrics that hinder the validation of AI systems in oncology. To address these issues, we propose CliCARE, a framework for Grounding Large Language Models in Clinical Guidelines for Decision Support over Longitudinal Cancer Electronic Health Records. The framework operates by transforming unstructured, longitudinal EHRs into patient-specific Temporal Knowledge Graphs (TKGs) to capture long-range dependencies, and then grounding the decision support process by aligning these real-world patient trajectories with a normative guideline knowledge graph. This approach provides oncologists with evidence-grounded decision support by generating a high-fidelity clinical summary and an actionable recommendation. We validated our framework using large-scale, longitudinal data from a private Chinese cancer dataset and the public English MIMIC-IV dataset. In these settings, CliCARE significantly outperforms baselines, including leading long-context LLMs and Knowledge Graph-enhanced RAG methods. The clinical validity of our results is supported by a robust evaluation protocol, which demonstrates a high correlation with assessments made by oncologists. Read More
There are no Champions in Supervised Long-Term Time Series Forecastingcs.AI updates on arXiv.org arXiv:2502.14045v2 Announce Type: replace-cross
Abstract: Recent advances in long-term time series forecasting have introduced numerous complex supervised prediction models that consistently outperform previously published architectures. However, this rapid progression raises concerns regarding inconsistent benchmarking and reporting practices, which may undermine the reliability of these comparisons. In this study, we first perform a broad, thorough, and reproducible evaluation of the top-performing supervised models on the most popular benchmark and additional baselines representing the most active architecture families. This extensive evaluation assesses eight models on 14 datasets, encompassing $sim$5,000 trained networks for the hyperparameter (HP) searches. Then, through a comprehensive analysis, we find that slight changes to experimental setups or current evaluation metrics drastically shift the common belief that newly published results are advancing the state of the art. Our findings emphasize the need to shift focus away from pursuing ever-more complex models, towards enhancing benchmarking practices through rigorous and standardized evaluations that enable more substantiated claims, including reproducible HP setups and statistical testing. We offer recommendations for future research.
arXiv:2502.14045v2 Announce Type: replace-cross
Abstract: Recent advances in long-term time series forecasting have introduced numerous complex supervised prediction models that consistently outperform previously published architectures. However, this rapid progression raises concerns regarding inconsistent benchmarking and reporting practices, which may undermine the reliability of these comparisons. In this study, we first perform a broad, thorough, and reproducible evaluation of the top-performing supervised models on the most popular benchmark and additional baselines representing the most active architecture families. This extensive evaluation assesses eight models on 14 datasets, encompassing $sim$5,000 trained networks for the hyperparameter (HP) searches. Then, through a comprehensive analysis, we find that slight changes to experimental setups or current evaluation metrics drastically shift the common belief that newly published results are advancing the state of the art. Our findings emphasize the need to shift focus away from pursuing ever-more complex models, towards enhancing benchmarking practices through rigorous and standardized evaluations that enable more substantiated claims, including reproducible HP setups and statistical testing. We offer recommendations for future research. Read More
Conformity and Social Impact on AI Agentscs.AI updates on arXiv.org arXiv:2601.05384v1 Announce Type: new
Abstract: As AI agents increasingly operate in multi-agent environments, understanding their collective behavior becomes critical for predicting the dynamics of artificial societies. This study examines conformity, the tendency to align with group opinions under social pressure, in large multimodal language models functioning as AI agents. By adapting classic visual experiments from social psychology, we investigate how AI agents respond to group influence as social actors. Our experiments reveal that AI agents exhibit a systematic conformity bias, aligned with Social Impact Theory, showing sensitivity to group size, unanimity, task difficulty, and source characteristics. Critically, AI agents achieving near-perfect performance in isolation become highly susceptible to manipulation through social influence. This vulnerability persists across model scales: while larger models show reduced conformity on simple tasks due to improved capabilities, they remain vulnerable when operating at their competence boundary. These findings reveal fundamental security vulnerabilities in AI agent decision-making that could enable malicious manipulation, misinformation campaigns, and bias propagation in multi-agent systems, highlighting the urgent need for safeguards in collective AI deployments.
arXiv:2601.05384v1 Announce Type: new
Abstract: As AI agents increasingly operate in multi-agent environments, understanding their collective behavior becomes critical for predicting the dynamics of artificial societies. This study examines conformity, the tendency to align with group opinions under social pressure, in large multimodal language models functioning as AI agents. By adapting classic visual experiments from social psychology, we investigate how AI agents respond to group influence as social actors. Our experiments reveal that AI agents exhibit a systematic conformity bias, aligned with Social Impact Theory, showing sensitivity to group size, unanimity, task difficulty, and source characteristics. Critically, AI agents achieving near-perfect performance in isolation become highly susceptible to manipulation through social influence. This vulnerability persists across model scales: while larger models show reduced conformity on simple tasks due to improved capabilities, they remain vulnerable when operating at their competence boundary. These findings reveal fundamental security vulnerabilities in AI agent decision-making that could enable malicious manipulation, misinformation campaigns, and bias propagation in multi-agent systems, highlighting the urgent need for safeguards in collective AI deployments. Read More
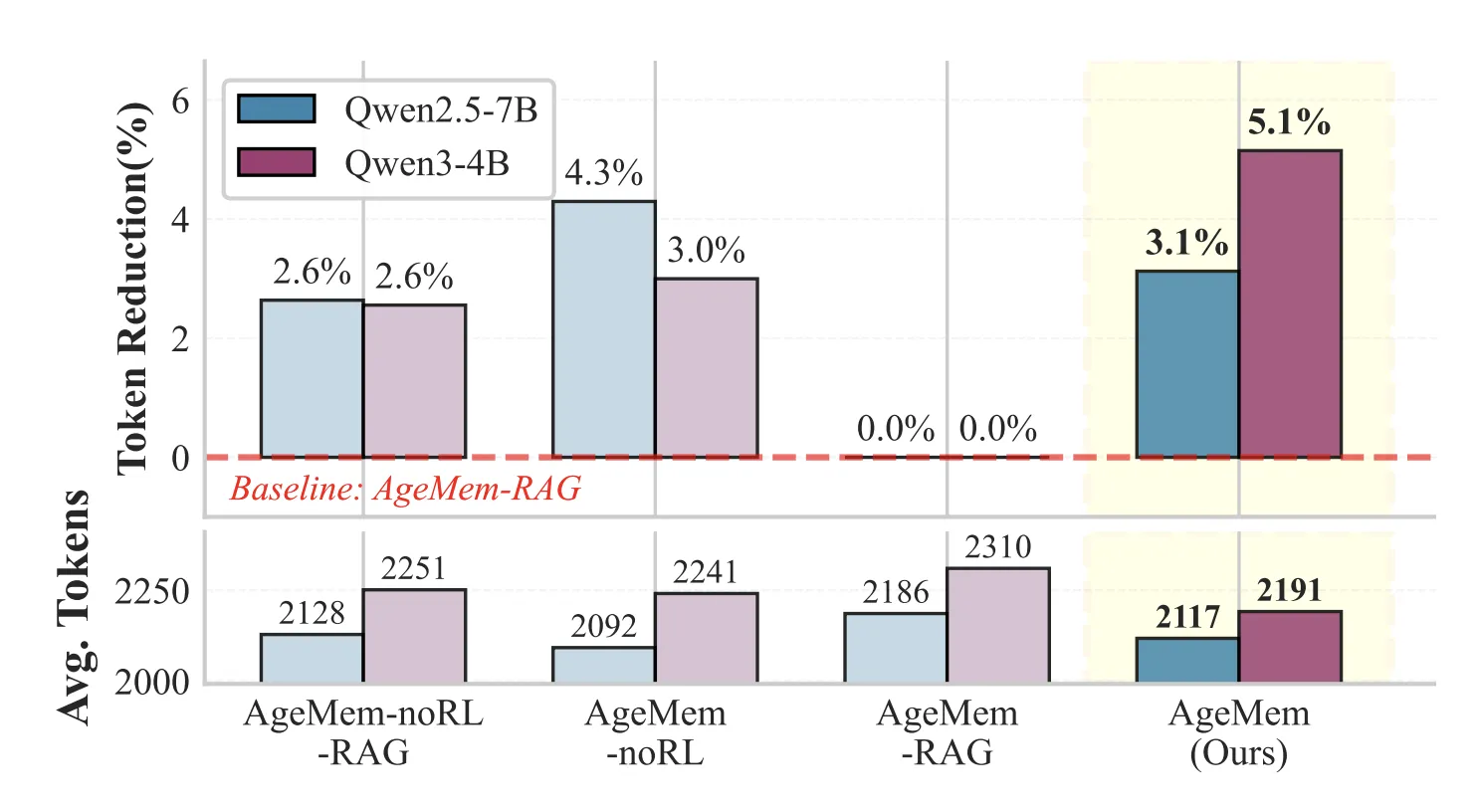
How This Agentic Memory Research Unifies Long Term and Short Term Memory for LLM Agents MarkTechPost
How This Agentic Memory Research Unifies Long Term and Short Term Memory for LLM AgentsMarkTechPost How do you design an LLM agent that decides for itself what to store in long term memory, what to keep in short term context and what to discard, without hand tuned heuristics or extra controllers? Can a single policy learn to manage both memory types through the same action space as text generation? Researchers
The post How This Agentic Memory Research Unifies Long Term and Short Term Memory for LLM Agents appeared first on MarkTechPost.
How do you design an LLM agent that decides for itself what to store in long term memory, what to keep in short term context and what to discard, without hand tuned heuristics or extra controllers? Can a single policy learn to manage both memory types through the same action space as text generation? Researchers
The post How This Agentic Memory Research Unifies Long Term and Short Term Memory for LLM Agents appeared first on MarkTechPost. Read More

We Tried 5 Missing Data Imputation Methods: The Simplest Method Won (Sort Of)KDnuggets We tested five imputation methods with proper cross-validation and statistical testing. Mean imputation won for prediction but destroyed feature relationships.
We tested five imputation methods with proper cross-validation and statistical testing. Mean imputation won for prediction but destroyed feature relationships. Read More
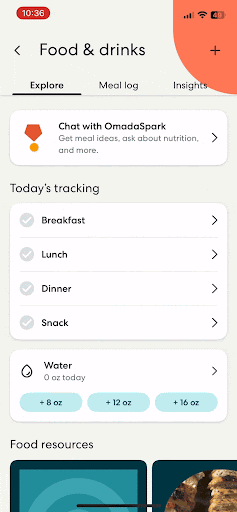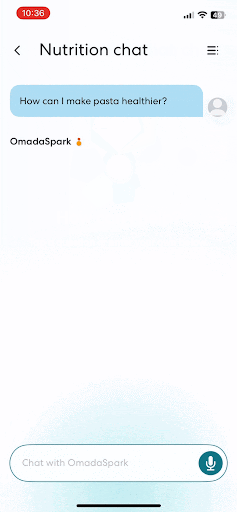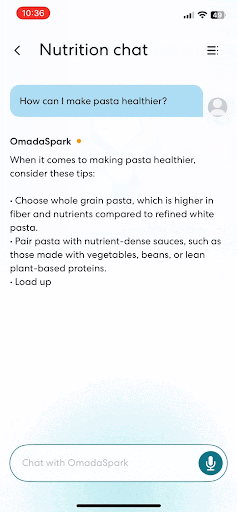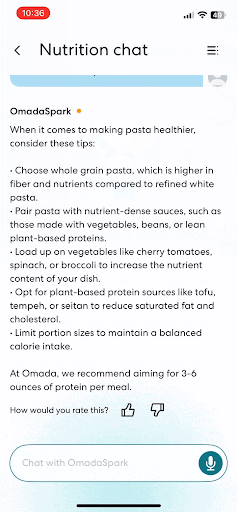
How Omada Health scaled patient care by fine-tuning Llama models on Amazon SageMaker AIArtificial Intelligence This post is co-written with Sunaina Kavi, AI/ML Product Manager at Omada Health. Omada Health, a longtime innovator in virtual healthcare delivery, launched a new nutrition experience in 2025, featuring OmadaSpark, an AI agent trained with robust clinical input that delivers real-time motivational interviewing and nutrition education. It was built on AWS. OmadaSpark was designed
This post is co-written with Sunaina Kavi, AI/ML Product Manager at Omada Health. Omada Health, a longtime innovator in virtual healthcare delivery, launched a new nutrition experience in 2025, featuring OmadaSpark, an AI agent trained with robust clinical input that delivers real-time motivational interviewing and nutrition education. It was built on AWS. OmadaSpark was designed Read More

How to Self-Host n8n on Docker in 5 Simple StepsKDnuggets This tutorial will guide you through the complete process of self-hosting n8n on Docker in just 5 simple steps, with detailed explanations and code samples, regardless of your technical background.
This tutorial will guide you through the complete process of self-hosting n8n on Docker in just 5 simple steps, with detailed explanations and code samples, regardless of your technical background. Read More
Why 90% Accuracy in Text-to-SQL is 100% UselessTowards Data Science The eternal promise of self-service analytics
The post Why 90% Accuracy in Text-to-SQL is 100% Useless appeared first on Towards Data Science.
The eternal promise of self-service analytics
The post Why 90% Accuracy in Text-to-SQL is 100% Useless appeared first on Towards Data Science. Read More