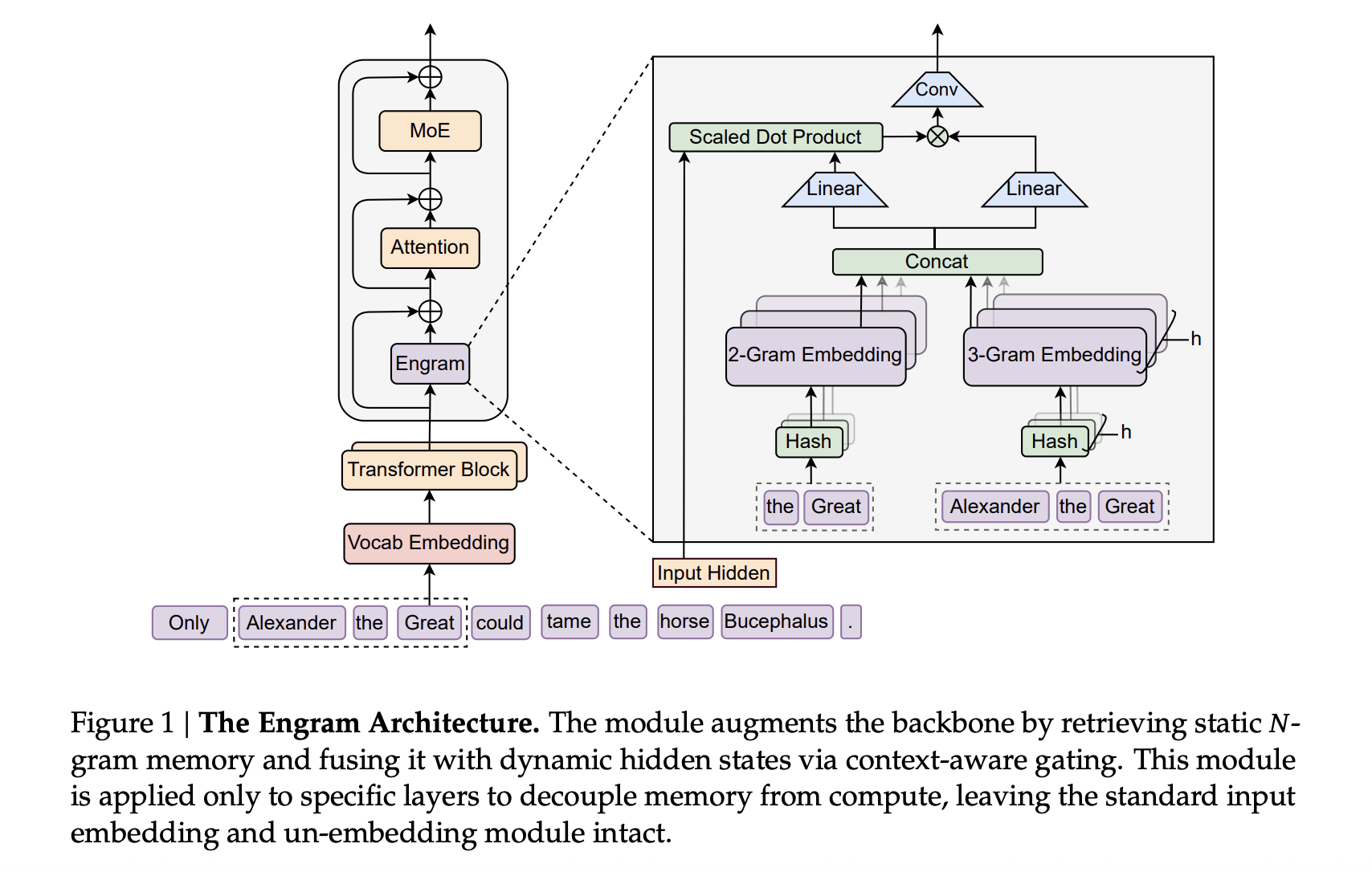
DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMsMarkTechPost Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost.
Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost. Read More

Feed-Forward Optimization With Delayed Feedback for Neural Network Trainingcs.AI updates on arXiv.org arXiv:2304.13372v2 Announce Type: replace-cross
Abstract: Backpropagation has long been criticized for being biologically implausible due to its reliance on concepts that are not viable in natural learning processes. Two core issues are the weight transport and update locking problems caused by the forward-backward dependencies, which limit biological plausibility, computational efficiency, and parallelization. Although several alternatives have been proposed to increase biological plausibility, they often come at the cost of reduced predictive performance. This paper proposes an alternative approach to training feed-forward neural networks addressing these issues by using approximate gradient information. We introduce Feed-Forward with delayed Feedback (F$^3$), which approximates gradients using fixed random feedback paths and delayed error information from the previous epoch to balance biological plausibility with predictive performance. We evaluate F$^3$ across multiple tasks and architectures, including both fully-connected and Transformer networks. Our results demonstrate that, compared to similarly plausible approaches, F$^3$ significantly improves predictive performance, narrowing the gap to backpropagation by up to 56% for classification and 96% for regression. This work is a step towards more biologically plausible learning algorithms while opening up new avenues for energy-efficient and parallelizable neural network training.
arXiv:2304.13372v2 Announce Type: replace-cross
Abstract: Backpropagation has long been criticized for being biologically implausible due to its reliance on concepts that are not viable in natural learning processes. Two core issues are the weight transport and update locking problems caused by the forward-backward dependencies, which limit biological plausibility, computational efficiency, and parallelization. Although several alternatives have been proposed to increase biological plausibility, they often come at the cost of reduced predictive performance. This paper proposes an alternative approach to training feed-forward neural networks addressing these issues by using approximate gradient information. We introduce Feed-Forward with delayed Feedback (F$^3$), which approximates gradients using fixed random feedback paths and delayed error information from the previous epoch to balance biological plausibility with predictive performance. We evaluate F$^3$ across multiple tasks and architectures, including both fully-connected and Transformer networks. Our results demonstrate that, compared to similarly plausible approaches, F$^3$ significantly improves predictive performance, narrowing the gap to backpropagation by up to 56% for classification and 96% for regression. This work is a step towards more biologically plausible learning algorithms while opening up new avenues for energy-efficient and parallelizable neural network training. Read More
Multiplex Thinking: Reasoning via Token-wise Branch-and-Mergecs.AI updates on arXiv.org arXiv:2601.08808v1 Announce Type: cross
Abstract: Large language models often solve complex reasoning tasks more effectively with Chain-of-Thought (CoT), but at the cost of long, low-bandwidth token sequences. Humans, by contrast, often reason softly by maintaining a distribution over plausible next steps. Motivated by this, we propose Multiplex Thinking, a stochastic soft reasoning mechanism that, at each thinking step, samples K candidate tokens and aggregates their embeddings into a single continuous multiplex token. This preserves the vocabulary embedding prior and the sampling dynamics of standard discrete generation, while inducing a tractable probability distribution over multiplex rollouts. Consequently, multiplex trajectories can be directly optimized with on-policy reinforcement learning (RL). Importantly, Multiplex Thinking is self-adaptive: when the model is confident, the multiplex token is nearly discrete and behaves like standard CoT; when it is uncertain, it compactly represents multiple plausible next steps without increasing sequence length. Across challenging math reasoning benchmarks, Multiplex Thinking consistently outperforms strong discrete CoT and RL baselines from Pass@1 through Pass@1024, while producing shorter sequences. The code and checkpoints are available at https://github.com/GMLR-Penn/Multiplex-Thinking.
arXiv:2601.08808v1 Announce Type: cross
Abstract: Large language models often solve complex reasoning tasks more effectively with Chain-of-Thought (CoT), but at the cost of long, low-bandwidth token sequences. Humans, by contrast, often reason softly by maintaining a distribution over plausible next steps. Motivated by this, we propose Multiplex Thinking, a stochastic soft reasoning mechanism that, at each thinking step, samples K candidate tokens and aggregates their embeddings into a single continuous multiplex token. This preserves the vocabulary embedding prior and the sampling dynamics of standard discrete generation, while inducing a tractable probability distribution over multiplex rollouts. Consequently, multiplex trajectories can be directly optimized with on-policy reinforcement learning (RL). Importantly, Multiplex Thinking is self-adaptive: when the model is confident, the multiplex token is nearly discrete and behaves like standard CoT; when it is uncertain, it compactly represents multiple plausible next steps without increasing sequence length. Across challenging math reasoning benchmarks, Multiplex Thinking consistently outperforms strong discrete CoT and RL baselines from Pass@1 through Pass@1024, while producing shorter sequences. The code and checkpoints are available at https://github.com/GMLR-Penn/Multiplex-Thinking. Read More
5 Code Sandbox for your AI AgentsKDnuggets A quick guide to the best code sandboxes for AI agents, so your LLM can build, test, and debug safely without touching your production infrastructure.
A quick guide to the best code sandboxes for AI agents, so your LLM can build, test, and debug safely without touching your production infrastructure. Read More
Topic Modeling Techniques for 2026: Seeded Modeling, LLM Integration, and Data SummariesTowards Data Science Seeded topic modeling, integration with LLMs, and training on summarized data are the fresh parts of the NLP toolkit.
The post Topic Modeling Techniques for 2026: Seeded Modeling, LLM Integration, and Data Summaries appeared first on Towards Data Science.
Seeded topic modeling, integration with LLMs, and training on summarized data are the fresh parts of the NLP toolkit.
The post Topic Modeling Techniques for 2026: Seeded Modeling, LLM Integration, and Data Summaries appeared first on Towards Data Science. Read More
SAC: A Framework for Measuring and Inducing Personality Traits in LLMs with Dynamic Intensity Controlcs.AI updates on arXiv.org arXiv:2506.20993v2 Announce Type: replace-cross
Abstract: Large language models (LLMs) have gained significant traction across a wide range of fields in recent years. There is also a growing expectation for them to display human-like personalities during interactions. To meet this expectation, numerous studies have proposed methods for modelling LLM personalities through psychometric evaluations. However, most existing models face two major limitations: they rely on the Big Five (OCEAN) framework, which only provides coarse personality dimensions, and they lack mechanisms for controlling trait intensity. In this paper, we address this gap by extending the Machine Personality Inventory (MPI), which originally used the Big Five model, to incorporate the 16 Personality Factor (16PF) model, allowing expressive control over sixteen distinct traits. We also developed a structured framework known as Specific Attribute Control (SAC) for evaluating and dynamically inducing trait intensity in LLMs. Our method introduces adjective-based semantic anchoring to guide trait intensity expression and leverages behavioural questions across five intensity factors: textit{Frequency}, textit{Depth}, textit{Threshold}, textit{Effort}, and textit{Willingness}. Through experimentation, we find that modelling intensity as a continuous spectrum yields substantially more consistent and controllable personality expression compared to binary trait toggling. Moreover, we observe that changes in target trait intensity systematically influence closely related traits in psychologically coherent directions, suggesting that LLMs internalize multi-dimensional personality structures rather than treating traits in isolation. Our work opens new pathways for controlled and nuanced human-machine interactions in domains such as healthcare, education, and interviewing processes, bringing us one step closer to truly human-like social machines.
arXiv:2506.20993v2 Announce Type: replace-cross
Abstract: Large language models (LLMs) have gained significant traction across a wide range of fields in recent years. There is also a growing expectation for them to display human-like personalities during interactions. To meet this expectation, numerous studies have proposed methods for modelling LLM personalities through psychometric evaluations. However, most existing models face two major limitations: they rely on the Big Five (OCEAN) framework, which only provides coarse personality dimensions, and they lack mechanisms for controlling trait intensity. In this paper, we address this gap by extending the Machine Personality Inventory (MPI), which originally used the Big Five model, to incorporate the 16 Personality Factor (16PF) model, allowing expressive control over sixteen distinct traits. We also developed a structured framework known as Specific Attribute Control (SAC) for evaluating and dynamically inducing trait intensity in LLMs. Our method introduces adjective-based semantic anchoring to guide trait intensity expression and leverages behavioural questions across five intensity factors: textit{Frequency}, textit{Depth}, textit{Threshold}, textit{Effort}, and textit{Willingness}. Through experimentation, we find that modelling intensity as a continuous spectrum yields substantially more consistent and controllable personality expression compared to binary trait toggling. Moreover, we observe that changes in target trait intensity systematically influence closely related traits in psychologically coherent directions, suggesting that LLMs internalize multi-dimensional personality structures rather than treating traits in isolation. Our work opens new pathways for controlled and nuanced human-machine interactions in domains such as healthcare, education, and interviewing processes, bringing us one step closer to truly human-like social machines. Read More
Structured Debate Improves Corporate Credit Reasoning in Financial AIcs.AI updates on arXiv.org arXiv:2510.17108v4 Announce Type: replace
Abstract: This study investigated LLM-based automation for analyzing non-financial data in corporate credit evaluation. Two systems were developed and compared: a Single-Agent System (SAS), in which one LLM agent infers favorable and adverse repayment signals, and a Popperian Multi-agent Debate System (PMADS), which structures the dual-perspective analysis as adversarial argumentation under the Karl Popper Debate protocol. Evaluation addressed three fronts: (i) work productivity compared with human experts; (ii) perceived report quality and usability, rated by credit risk professionals for system-generated reports; and (iii) reasoning characteristics quantified via reasoning-tree analysis. Both systems drastically reduced task completion time relative to human experts. Professionals rated SAS reports as adequate, while PMADS reports exceeded neutral benchmarks and scored significantly higher in explanatory adequacy, practical applicability, and usability. Reasoning-tree analysis showed PMADS produced deeper, more elaborated structures, whereas SAS yielded single-layered trees. These findings suggest that structured multi-agent debate enhances analytical rigor and perceived usefulness, though at the cost of longer computation time. Overall, the results demonstrate that reasoning-centered automation represents a promising approach for developing useful AI systems in decision-critical financial contexts.
arXiv:2510.17108v4 Announce Type: replace
Abstract: This study investigated LLM-based automation for analyzing non-financial data in corporate credit evaluation. Two systems were developed and compared: a Single-Agent System (SAS), in which one LLM agent infers favorable and adverse repayment signals, and a Popperian Multi-agent Debate System (PMADS), which structures the dual-perspective analysis as adversarial argumentation under the Karl Popper Debate protocol. Evaluation addressed three fronts: (i) work productivity compared with human experts; (ii) perceived report quality and usability, rated by credit risk professionals for system-generated reports; and (iii) reasoning characteristics quantified via reasoning-tree analysis. Both systems drastically reduced task completion time relative to human experts. Professionals rated SAS reports as adequate, while PMADS reports exceeded neutral benchmarks and scored significantly higher in explanatory adequacy, practical applicability, and usability. Reasoning-tree analysis showed PMADS produced deeper, more elaborated structures, whereas SAS yielded single-layered trees. These findings suggest that structured multi-agent debate enhances analytical rigor and perceived usefulness, though at the cost of longer computation time. Overall, the results demonstrate that reasoning-centered automation represents a promising approach for developing useful AI systems in decision-critical financial contexts. Read More
AutoContext: Instance-Level Context Learning for LLM Agentscs.AI updates on arXiv.org arXiv:2510.02369v3 Announce Type: replace-cross
Abstract: Current LLM agents typically lack instance-level context, which comprises concrete facts such as environment structure, system configurations, and local mechanics. Consequently, existing methods are forced to intertwine exploration with task execution. This coupling leads to redundant interactions and fragile decision-making, as agents must repeatedly rediscover the same information for every new task. To address this, we introduce AutoContext, a method that decouples exploration from task solving. AutoContext performs a systematic, one-off exploration to construct a reusable knowledge graph for each environment instance. This structured context allows off-the-shelf agents to access necessary facts directly, eliminating redundant exploration. Experiments across TextWorld, ALFWorld, Crafter, and InterCode-Bash demonstrate substantial gains: for example, the success rate of a ReAct agent on TextWorld improves from 37% to 95%, highlighting the critical role of structured instance context in efficient agentic systems.
arXiv:2510.02369v3 Announce Type: replace-cross
Abstract: Current LLM agents typically lack instance-level context, which comprises concrete facts such as environment structure, system configurations, and local mechanics. Consequently, existing methods are forced to intertwine exploration with task execution. This coupling leads to redundant interactions and fragile decision-making, as agents must repeatedly rediscover the same information for every new task. To address this, we introduce AutoContext, a method that decouples exploration from task solving. AutoContext performs a systematic, one-off exploration to construct a reusable knowledge graph for each environment instance. This structured context allows off-the-shelf agents to access necessary facts directly, eliminating redundant exploration. Experiments across TextWorld, ALFWorld, Crafter, and InterCode-Bash demonstrate substantial gains: for example, the success rate of a ReAct agent on TextWorld improves from 37% to 95%, highlighting the critical role of structured instance context in efficient agentic systems. Read More
Glitches in the Attention MatrixTowards Data Science A history of Transformer artifacts and the latest research on how to fix them
The post Glitches in the Attention Matrix appeared first on Towards Data Science.
A history of Transformer artifacts and the latest research on how to fix them
The post Glitches in the Attention Matrix appeared first on Towards Data Science. Read More

Research shows UK young adults would use AI for financial guidanceAI News Research from Cleo AI indicates that young adults are turning to artificial intelligence for financial advice to help them manage their money and develop more sustainable financial habits. The study surveyed 5,000 UK adults aged 28 to 40 and found that the majority are saving significantly less than they would like. In this context, interest
The post Research shows UK young adults would use AI for financial guidance appeared first on AI News.
Research from Cleo AI indicates that young adults are turning to artificial intelligence for financial advice to help them manage their money and develop more sustainable financial habits. The study surveyed 5,000 UK adults aged 28 to 40 and found that the majority are saving significantly less than they would like. In this context, interest
The post Research shows UK young adults would use AI for financial guidance appeared first on AI News. Read More