
Integrating Knowledge Distillation Methods: A Sequential Multi-Stage Frameworkcs.AI updates on arXiv.org arXiv:2601.15657v1 Announce Type: cross
Abstract: Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness.
This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration.
By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods.
arXiv:2601.15657v1 Announce Type: cross
Abstract: Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness.
This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration.
By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods. Read More
FlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Designcs.AI updates on arXiv.org arXiv:2601.15710v1 Announce Type: cross
Abstract: We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$times$ end-to-end speedup, 1.64$times$ higher decode throughput, and 3.14$times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$times$, 6.55$times$, and 4.13$times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$times$ and extends the context window by 64$times$, delivering 1.10$times$/4.86$times$ lower end-to-end latency and 5.21$times$/6.27$times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
arXiv:2601.15710v1 Announce Type: cross
Abstract: We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$times$ end-to-end speedup, 1.64$times$ higher decode throughput, and 3.14$times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$times$, 6.55$times$, and 4.13$times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$times$ and extends the context window by 64$times$, delivering 1.10$times$/4.86$times$ lower end-to-end latency and 5.21$times$/6.27$times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort. Read More
PromptHelper: A Prompt Recommender System for Encouraging Creativity in AI Chatbot Interactionscs.AI updates on arXiv.org arXiv:2601.15575v1 Announce Type: cross
Abstract: Prompting is central to interaction with AI systems, yet many users struggle to explore alternative directions, articulate creative intent, or understand how variations in prompts shape model outputs. We introduce prompt recommender systems (PRS) as an interaction approach that supports exploration, suggesting contextually relevant follow-up prompts. We present PromptHelper, a PRS prototype integrated into an AI chatbot that surfaces semantically diverse prompt suggestions while users work on real writing tasks. We evaluate PromptHelper in a 2×2 fully within-subjects study (N=32) across creative and academic writing tasks. Results show that PromptHelper significantly increases users’ perceived exploration and expressiveness without increasing cognitive workload. Qualitative findings illustrate how prompt recommendations help users branch into new directions, overcome uncertainty about what to ask next, and better articulate their intent. We discuss implications for designing AI interfaces that scaffold exploratory interaction while preserving user agency, and release open-source resources to support research on prompt recommendation.
arXiv:2601.15575v1 Announce Type: cross
Abstract: Prompting is central to interaction with AI systems, yet many users struggle to explore alternative directions, articulate creative intent, or understand how variations in prompts shape model outputs. We introduce prompt recommender systems (PRS) as an interaction approach that supports exploration, suggesting contextually relevant follow-up prompts. We present PromptHelper, a PRS prototype integrated into an AI chatbot that surfaces semantically diverse prompt suggestions while users work on real writing tasks. We evaluate PromptHelper in a 2×2 fully within-subjects study (N=32) across creative and academic writing tasks. Results show that PromptHelper significantly increases users’ perceived exploration and expressiveness without increasing cognitive workload. Qualitative findings illustrate how prompt recommendations help users branch into new directions, overcome uncertainty about what to ask next, and better articulate their intent. We discuss implications for designing AI interfaces that scaffold exploratory interaction while preserving user agency, and release open-source resources to support research on prompt recommendation. Read More
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generationcs.AI updates on arXiv.org arXiv:2601.15369v1 Announce Type: cross
Abstract: This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
arXiv:2601.15369v1 Announce Type: cross
Abstract: This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling. Read More
Chunking, Retrieval, and Re-ranking: An Empirical Evaluation of RAG Architectures for Policy Document Question Answeringcs.AI updates on arXiv.org arXiv:2601.15457v1 Announce Type: cross
Abstract: The integration of Large Language Models (LLMs) into the public health policy sector offers a transformative approach to navigating the vast repositories of regulatory guidance maintained by agencies such as the Centers for Disease Control and Prevention (CDC). However, the propensity for LLMs to generate hallucinations, defined as plausible but factually incorrect assertions, presents a critical barrier to the adoption of these technologies in high-stakes environments where information integrity is non-negotiable. This empirical evaluation explores the effectiveness of Retrieval-Augmented Generation (RAG) architectures in mitigating these risks by grounding generative outputs in authoritative document context. Specifically, this study compares a baseline Vanilla LLM against Basic RAG and Advanced RAG pipelines utilizing cross-encoder re-ranking. The experimental framework employs a Mistral-7B-Instruct-v0.2 model and an all-MiniLM-L6-v2 embedding model to process a corpus of official CDC policy analytical frameworks and guidance documents. The analysis measures the impact of two distinct chunking strategies, recursive character-based and token-based semantic splitting, on system accuracy, measured through faithfulness and relevance scores across a curated set of complex policy scenarios. Quantitative findings indicate that while Basic RAG architectures provide a substantial improvement in faithfulness (0.621) over Vanilla baselines (0.347), the Advanced RAG configuration achieves a superior faithfulness average of 0.797. These results demonstrate that two-stage retrieval mechanisms are essential for achieving the precision required for domain-specific policy question answering, though structural constraints in document segmentation remain a significant bottleneck for multi-step reasoning tasks.
arXiv:2601.15457v1 Announce Type: cross
Abstract: The integration of Large Language Models (LLMs) into the public health policy sector offers a transformative approach to navigating the vast repositories of regulatory guidance maintained by agencies such as the Centers for Disease Control and Prevention (CDC). However, the propensity for LLMs to generate hallucinations, defined as plausible but factually incorrect assertions, presents a critical barrier to the adoption of these technologies in high-stakes environments where information integrity is non-negotiable. This empirical evaluation explores the effectiveness of Retrieval-Augmented Generation (RAG) architectures in mitigating these risks by grounding generative outputs in authoritative document context. Specifically, this study compares a baseline Vanilla LLM against Basic RAG and Advanced RAG pipelines utilizing cross-encoder re-ranking. The experimental framework employs a Mistral-7B-Instruct-v0.2 model and an all-MiniLM-L6-v2 embedding model to process a corpus of official CDC policy analytical frameworks and guidance documents. The analysis measures the impact of two distinct chunking strategies, recursive character-based and token-based semantic splitting, on system accuracy, measured through faithfulness and relevance scores across a curated set of complex policy scenarios. Quantitative findings indicate that while Basic RAG architectures provide a substantial improvement in faithfulness (0.621) over Vanilla baselines (0.347), the Advanced RAG configuration achieves a superior faithfulness average of 0.797. These results demonstrate that two-stage retrieval mechanisms are essential for achieving the precision required for domain-specific policy question answering, though structural constraints in document segmentation remain a significant bottleneck for multi-step reasoning tasks. Read More
Why the Sophistication of Your Prompt Correlates Almost Perfectly with the Sophistication of the Response, as Research by Anthropic FoundTowards Data Science How prompt engineering has evolved, examined scientifically; and implications for the future of conversational AI tools
The post Why the Sophistication of Your Prompt Correlates Almost Perfectly with the Sophistication of the Response, as Research by Anthropic Found appeared first on Towards Data Science.
How prompt engineering has evolved, examined scientifically; and implications for the future of conversational AI tools
The post Why the Sophistication of Your Prompt Correlates Almost Perfectly with the Sophistication of the Response, as Research by Anthropic Found appeared first on Towards Data Science. Read More
Delayed Assignments in Online Non-Centroid Clustering with Stochastic Arrivalscs.AI updates on arXiv.org arXiv:2601.16091v1 Announce Type: cross
Abstract: Clustering is a fundamental problem, aiming to partition a set of elements, like agents or data points, into clusters such that elements in the same cluster are closer to each other than to those in other clusters. In this paper, we present a new framework for studying online non-centroid clustering with delays, where elements, that arrive one at a time as points in a finite metric space, should be assigned to clusters, but assignments need not be immediate. Specifically, upon arrival, each point’s location is revealed, and an online algorithm has to irrevocably assign it to an existing cluster or create a new one containing, at this moment, only this point. However, we allow decisions to be postponed at a delay cost, instead of following the more common assumption of immediate decisions upon arrival. This poses a critical challenge: the goal is to minimize both the total distance costs between points in each cluster and the overall delay costs incurred by postponing assignments. In the classic worst-case arrival model, where points arrive in an arbitrary order, no algorithm has a competitive ratio better than sublogarithmic in the number of points. To overcome this strong impossibility, we focus on a stochastic arrival model, where points’ locations are drawn independently across time from an unknown and fixed probability distribution over the finite metric space. We offer hope for beyond worst-case adversaries: we devise an algorithm that is constant competitive in the sense that, as the number of points grows, the ratio between the expected overall costs of the output clustering and an optimal offline clustering is bounded by a constant.
arXiv:2601.16091v1 Announce Type: cross
Abstract: Clustering is a fundamental problem, aiming to partition a set of elements, like agents or data points, into clusters such that elements in the same cluster are closer to each other than to those in other clusters. In this paper, we present a new framework for studying online non-centroid clustering with delays, where elements, that arrive one at a time as points in a finite metric space, should be assigned to clusters, but assignments need not be immediate. Specifically, upon arrival, each point’s location is revealed, and an online algorithm has to irrevocably assign it to an existing cluster or create a new one containing, at this moment, only this point. However, we allow decisions to be postponed at a delay cost, instead of following the more common assumption of immediate decisions upon arrival. This poses a critical challenge: the goal is to minimize both the total distance costs between points in each cluster and the overall delay costs incurred by postponing assignments. In the classic worst-case arrival model, where points arrive in an arbitrary order, no algorithm has a competitive ratio better than sublogarithmic in the number of points. To overcome this strong impossibility, we focus on a stochastic arrival model, where points’ locations are drawn independently across time from an unknown and fixed probability distribution over the finite metric space. We offer hope for beyond worst-case adversaries: we devise an algorithm that is constant competitive in the sense that, as the number of points grows, the ratio between the expected overall costs of the output clustering and an optimal offline clustering is bounded by a constant. Read More
Do You Feel Comfortable? Detecting Hidden Conversational Escalation in AI Chatbotscs.AI updates on arXiv.org arXiv:2512.06193v4 Announce Type: replace-cross
Abstract: Large Language Models (LLM) are increasingly integrated into everyday interactions, serving not only as information assistants but also as emotional companions. Even in the absence of explicit toxicity, repeated emotional reinforcement or affective drift can gradually escalate distress in a form of textit{implicit harm} that traditional toxicity filters fail to detect. Existing guardrail mechanisms often rely on external classifiers or clinical rubrics that may lag behind the nuanced, real-time dynamics of a developing conversation. To address this gap, we propose GAUGE (Guarding Affective Utterance Generation Escalation), logit-based framework for the real-time detection of hidden conversational escalation. GAUGE measures how an LLM’s output probabilistically shifts the affective state of a dialogue.
arXiv:2512.06193v4 Announce Type: replace-cross
Abstract: Large Language Models (LLM) are increasingly integrated into everyday interactions, serving not only as information assistants but also as emotional companions. Even in the absence of explicit toxicity, repeated emotional reinforcement or affective drift can gradually escalate distress in a form of textit{implicit harm} that traditional toxicity filters fail to detect. Existing guardrail mechanisms often rely on external classifiers or clinical rubrics that may lag behind the nuanced, real-time dynamics of a developing conversation. To address this gap, we propose GAUGE (Guarding Affective Utterance Generation Escalation), logit-based framework for the real-time detection of hidden conversational escalation. GAUGE measures how an LLM’s output probabilistically shifts the affective state of a dialogue. Read More
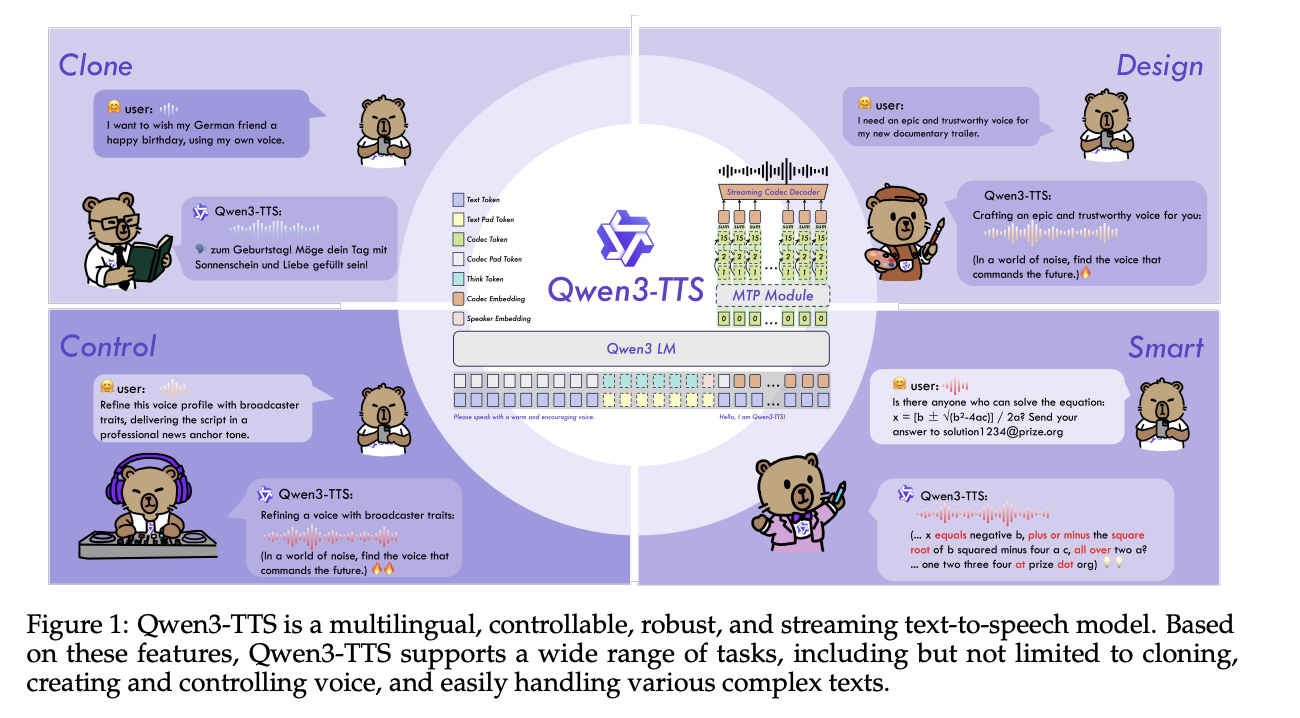
Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice ControlMarkTechPost Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost.
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost. Read More
Knowing When to Abstain: Medical LLMs Under Clinical Uncertaintycs.AI updates on arXiv.org arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications.
arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications. Read More