
AI agents prefer Bitcoin shaping new finance architectureAI News AI agents prefer Bitcoin for digital wealth storage, forcing finance chiefs to adapt their architecture for machine autonomy. When AI systems gain economic autonomy, their internal logic dictates how corporate capital flows. Non-partisan research by the Bitcoin Policy Institute evaluated how these frontier models would transact if operating as independent economic actors. The study tested
The post AI agents prefer Bitcoin shaping new finance architecture appeared first on AI News.
AI agents prefer Bitcoin for digital wealth storage, forcing finance chiefs to adapt their architecture for machine autonomy. When AI systems gain economic autonomy, their internal logic dictates how corporate capital flows. Non-partisan research by the Bitcoin Policy Institute evaluated how these frontier models would transact if operating as independent economic actors. The study tested
The post AI agents prefer Bitcoin shaping new finance architecture appeared first on AI News. Read More

Theory of Code Space: Do Code Agents Understand Software Architecture?cs.AI updates on arXiv.org arXiv:2603.00601v2 Announce Type: cross
Abstract: AI code agents excel at isolated tasks yet struggle with complex, multi-file software engineering requiring understanding of how dozens of modules relate. We hypothesize these failures stem from inability to construct, maintain, and update coherent architectural beliefs during codebase exploration. We introduce Theory of Code Space (ToCS), a benchmark that evaluates this capability by placing agents in procedurally generated codebases under partial observability, requiring them to build structured belief states over module dependencies, cross-cutting invariants, and design intent. The framework features: (1) a procedural codebase generator producing medium-complexity Python projects with four typed edge categories reflecting different discovery methods — from syntactic imports to config-driven dynamic wiring — with planted architectural constraints and verified ground truth; (2) a partial observability harness where agents explore under a budget; and (3) periodic belief probing via structured JSON, producing a time-series of architectural understanding. We decompose the Active-Passive Gap from spatial reasoning benchmarks into selection and decision components, and introduce Architectural Constraint Discovery as a code-specific evaluation dimension. Preliminary experiments with four rule-based baselines and five frontier LLM agents from three providers validate discriminative power: methods span a wide performance range (F1 from 0.129 to 0.646), LLM agents discover semantic edge types invisible to all baselines, yet weaker models score below simple heuristics — revealing that belief externalization, faithfully serializing internal understanding into structured JSON, is itself a non-trivial capability and a first-order confounder in belief-probing benchmarks. Open-source toolkit: https://github.com/che-shr-cat/tocs
arXiv:2603.00601v2 Announce Type: cross
Abstract: AI code agents excel at isolated tasks yet struggle with complex, multi-file software engineering requiring understanding of how dozens of modules relate. We hypothesize these failures stem from inability to construct, maintain, and update coherent architectural beliefs during codebase exploration. We introduce Theory of Code Space (ToCS), a benchmark that evaluates this capability by placing agents in procedurally generated codebases under partial observability, requiring them to build structured belief states over module dependencies, cross-cutting invariants, and design intent. The framework features: (1) a procedural codebase generator producing medium-complexity Python projects with four typed edge categories reflecting different discovery methods — from syntactic imports to config-driven dynamic wiring — with planted architectural constraints and verified ground truth; (2) a partial observability harness where agents explore under a budget; and (3) periodic belief probing via structured JSON, producing a time-series of architectural understanding. We decompose the Active-Passive Gap from spatial reasoning benchmarks into selection and decision components, and introduce Architectural Constraint Discovery as a code-specific evaluation dimension. Preliminary experiments with four rule-based baselines and five frontier LLM agents from three providers validate discriminative power: methods span a wide performance range (F1 from 0.129 to 0.646), LLM agents discover semantic edge types invisible to all baselines, yet weaker models score below simple heuristics — revealing that belief externalization, faithfully serializing internal understanding into structured JSON, is itself a non-trivial capability and a first-order confounder in belief-probing benchmarks. Open-source toolkit: https://github.com/che-shr-cat/tocs Read More
Confusion-Aware Rubric Optimization for LLM-based Automated Gradingcs.AI updates on arXiv.org arXiv:2603.00451v1 Announce Type: new
Abstract: Accurate and unambiguous guidelines are critical for large language model (LLM) based graders, yet manually crafting these prompts is often sub-optimal as LLMs can misinterpret expert guidelines or lack necessary domain specificity. Consequently, the field has moved toward automated prompt optimization to refine grading guidelines without the burden of manual trial and error. However, existing frameworks typically aggregate independent and unstructured error samples into a single update step, resulting in “rule dilution” where conflicting constraints weaken the model’s grading logic. To address these limitations, we introduce Confusion-Aware Rubric Optimization (CARO), a novel framework that enhances accuracy and computational efficiency by structurally separating error signals. CARO leverages the confusion matrix to decompose monolithic error signals into distinct modes, allowing for the diagnosis and repair of specific misclassification patterns individually. By synthesizing targeted “fixing patches” for dominant error modes and employing a diversity-aware selection mechanism, the framework prevents guidance conflict and eliminates the need for resource-heavy nested refinement loops. Empirical evaluations on teacher education and STEM datasets demonstrate that CARO significantly outperforms existing SOTA methods. These results suggest that replacing mixed-error aggregation with surgical, mode-specific repair yields robust improvements in automated assessment scalability and precision.
arXiv:2603.00451v1 Announce Type: new
Abstract: Accurate and unambiguous guidelines are critical for large language model (LLM) based graders, yet manually crafting these prompts is often sub-optimal as LLMs can misinterpret expert guidelines or lack necessary domain specificity. Consequently, the field has moved toward automated prompt optimization to refine grading guidelines without the burden of manual trial and error. However, existing frameworks typically aggregate independent and unstructured error samples into a single update step, resulting in “rule dilution” where conflicting constraints weaken the model’s grading logic. To address these limitations, we introduce Confusion-Aware Rubric Optimization (CARO), a novel framework that enhances accuracy and computational efficiency by structurally separating error signals. CARO leverages the confusion matrix to decompose monolithic error signals into distinct modes, allowing for the diagnosis and repair of specific misclassification patterns individually. By synthesizing targeted “fixing patches” for dominant error modes and employing a diversity-aware selection mechanism, the framework prevents guidance conflict and eliminates the need for resource-heavy nested refinement loops. Empirical evaluations on teacher education and STEM datasets demonstrate that CARO significantly outperforms existing SOTA methods. These results suggest that replacing mixed-error aggregation with surgical, mode-specific repair yields robust improvements in automated assessment scalability and precision. Read More
Monotropic Artificial Intelligence: Toward a Cognitive Taxonomy of Domain-Specialized Language Modelscs.AI updates on arXiv.org arXiv:2603.00350v1 Announce Type: new
Abstract: The prevailing paradigm in artificial intelligence research equates progress with scale: larger models trained on broader datasets are presumed to yield superior capabilities. This assumption, while empirically productive for general-purpose applications, obscures a fundamental epistemological tension between breadth and depth of knowledge. We introduce the concept of emph{Monotropic Artificial Intelligence} — language models that deliberately sacrifice generality to achieve extraordinary precision within narrowly circumscribed domains. Drawing on the cognitive theory of monotropism developed to understand autistic cognition, we argue that intense specialization represents not a limitation but an alternative cognitive architecture with distinct advantages for safety-critical applications. We formalize the defining characteristics of monotropic models, contrast them with conventional polytropic architectures, and demonstrate their viability through Mini-Enedina, a 37.5-million-parameter model that achieves near-perfect performance on Timoshenko beam analysis while remaining deliberately incompetent outside its domain. Our framework challenges the implicit assumption that artificial general intelligence constitutes the sole legitimate aspiration of AI research, proposing instead a cognitive ecology in which specialized and generalist systems coexist complementarily.
arXiv:2603.00350v1 Announce Type: new
Abstract: The prevailing paradigm in artificial intelligence research equates progress with scale: larger models trained on broader datasets are presumed to yield superior capabilities. This assumption, while empirically productive for general-purpose applications, obscures a fundamental epistemological tension between breadth and depth of knowledge. We introduce the concept of emph{Monotropic Artificial Intelligence} — language models that deliberately sacrifice generality to achieve extraordinary precision within narrowly circumscribed domains. Drawing on the cognitive theory of monotropism developed to understand autistic cognition, we argue that intense specialization represents not a limitation but an alternative cognitive architecture with distinct advantages for safety-critical applications. We formalize the defining characteristics of monotropic models, contrast them with conventional polytropic architectures, and demonstrate their viability through Mini-Enedina, a 37.5-million-parameter model that achieves near-perfect performance on Timoshenko beam analysis while remaining deliberately incompetent outside its domain. Our framework challenges the implicit assumption that artificial general intelligence constitutes the sole legitimate aspiration of AI research, proposing instead a cognitive ecology in which specialized and generalist systems coexist complementarily. Read More
Retrieval, Refinement, and Ranking for Text-to-Video Generation via Prompt Optimization and Test-Time Scalingcs.AI updates on arXiv.org arXiv:2603.01509v1 Announce Type: cross
Abstract: While large-scale datasets have driven significant progress in Text-to-Video (T2V) generative models, these models remain highly sensitive to input prompts, demonstrating that prompt design is critical to generation quality. Current methods for improving video output often fall short: they either depend on complex, post-editing models, risking the introduction of artifacts, or require expensive fine-tuning of the core generator, which severely limits both scalability and accessibility. In this work, we introduce 3R, a novel RAG based prompt optimization framework. 3R utilizes the power of current state-of-the-art T2V diffusion model and vision language model. It can be used with any T2V model without any kind of model training. The framework leverages three key strategies: RAG-based modifiers extraction for enriched contextual grounding, diffusion-based Preference Optimization for aligning outputs with human preferences, and temporal frame interpolation for producing temporally consistent visual contents. Together, these components enable more accurate, efficient, and contextually aligned text-to-video generation. Experimental results demonstrate the efficacy of 3R in enhancing the static fidelity and dynamic coherence of generated videos, underscoring the importance of optimizing user prompts.
arXiv:2603.01509v1 Announce Type: cross
Abstract: While large-scale datasets have driven significant progress in Text-to-Video (T2V) generative models, these models remain highly sensitive to input prompts, demonstrating that prompt design is critical to generation quality. Current methods for improving video output often fall short: they either depend on complex, post-editing models, risking the introduction of artifacts, or require expensive fine-tuning of the core generator, which severely limits both scalability and accessibility. In this work, we introduce 3R, a novel RAG based prompt optimization framework. 3R utilizes the power of current state-of-the-art T2V diffusion model and vision language model. It can be used with any T2V model without any kind of model training. The framework leverages three key strategies: RAG-based modifiers extraction for enriched contextual grounding, diffusion-based Preference Optimization for aligning outputs with human preferences, and temporal frame interpolation for producing temporally consistent visual contents. Together, these components enable more accurate, efficient, and contextually aligned text-to-video generation. Experimental results demonstrate the efficacy of 3R in enhancing the static fidelity and dynamic coherence of generated videos, underscoring the importance of optimizing user prompts. Read More
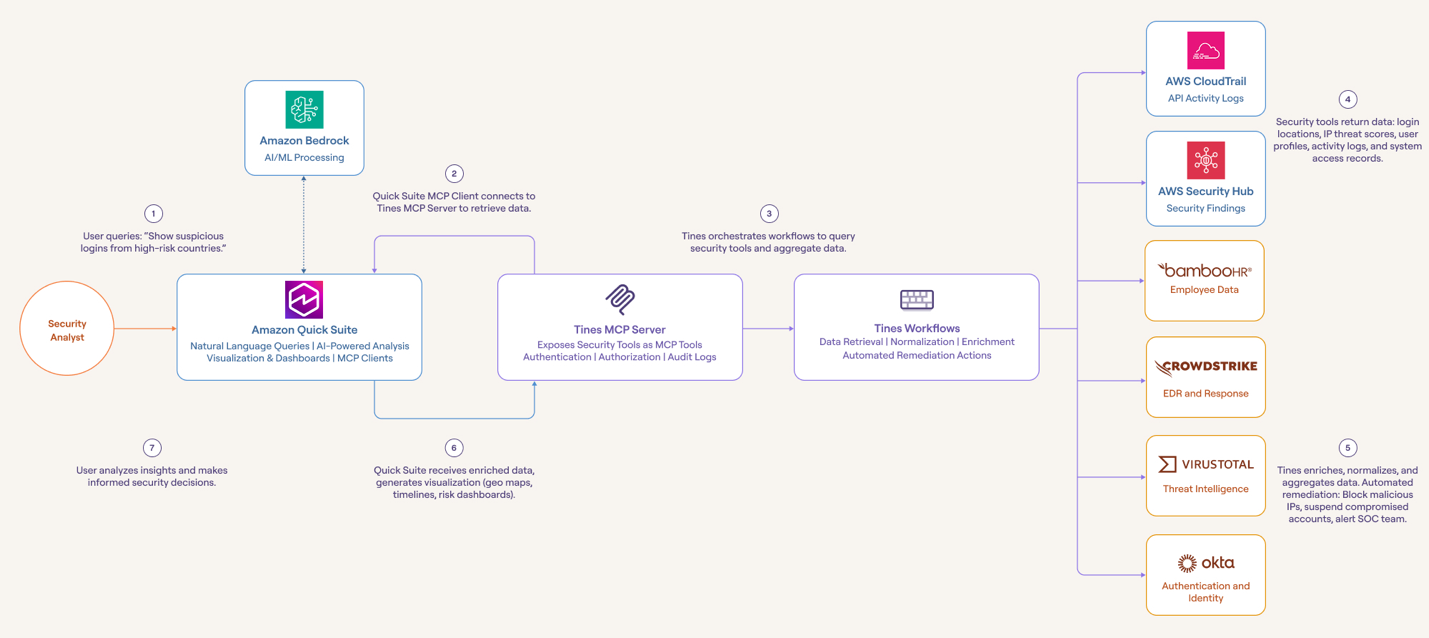
How Tines enhances security analysis with Amazon Quick SuiteArtificial Intelligence In this post, we show you how to connect Quick Suite with Tines to securely retrieve, analyze, and visualize enterprise data from any security or IT system. We walk through an example that uses a MCP server in Tines to retrieve data from various tools, such as AWS CloudTrail, Okta, and VirusTotal, to remediate security events using Quick Suite.
In this post, we show you how to connect Quick Suite with Tines to securely retrieve, analyze, and visualize enterprise data from any security or IT system. We walk through an example that uses a MCP server in Tines to retrieve data from various tools, such as AWS CloudTrail, Okta, and VirusTotal, to remediate security events using Quick Suite. Read More

From PRD to Functioning Software with Google AntigravityKDnuggets This article guide you through an example use case to turn a PRD into a functioning software prototype using Google Antigravity.
This article guide you through an example use case to turn a PRD into a functioning software prototype using Google Antigravity. Read More
Why You Should Stop Writing Loops in Pandas Towards Data Science How to think in columns, write faster code, and finally use Pandas like a professional
The post Why You Should Stop Writing Loops in Pandas appeared first on Towards Data Science.
How to think in columns, write faster code, and finally use Pandas like a professional
The post Why You Should Stop Writing Loops in Pandas appeared first on Towards Data Science. Read More

Best AI security solutions 2026: Top enterprise platforms comparedAI News Artificial intelligence is no longer just powering defensive cybersecurity tools, it is reshaping the entire threat landscape. AI is accelerating reconnaissance, improving the realism of phishing, automating malware mutation, and enabling adaptive attack techniques. At the same time, enterprises are embedding AI agents, copilots, and generative AI tools into everyday workflows. That dual dynamic has
The post Best AI security solutions 2026: Top enterprise platforms compared appeared first on AI News.
Artificial intelligence is no longer just powering defensive cybersecurity tools, it is reshaping the entire threat landscape. AI is accelerating reconnaissance, improving the realism of phishing, automating malware mutation, and enabling adaptive attack techniques. At the same time, enterprises are embedding AI agents, copilots, and generative AI tools into everyday workflows. That dual dynamic has
The post Best AI security solutions 2026: Top enterprise platforms compared appeared first on AI News. Read More
The integration of AI in modern forex automationAI News Try to think of just one area where artificial intelligence is not leaving a mark, and you’ll realise there’s almost none. And in the forex world, things have not been any different. It’s a big part of why Fortune Business Insights values the global AI market size at $375.93 billion. Looking ahead, the sector could
The post The integration of AI in modern forex automation appeared first on AI News.
Try to think of just one area where artificial intelligence is not leaving a mark, and you’ll realise there’s almost none. And in the forex world, things have not been any different. It’s a big part of why Fortune Business Insights values the global AI market size at $375.93 billion. Looking ahead, the sector could
The post The integration of AI in modern forex automation appeared first on AI News. Read More