
Memory, Benchmark & Robots: A Benchmark for Solving Complex Tasks with Reinforcement Learningcs.AI updates on arXiv.org arXiv:2502.10550v3 Announce Type: replace-cross
Abstract: Memory is crucial for enabling agents to tackle complex tasks with temporal and spatial dependencies. While many reinforcement learning (RL) algorithms incorporate memory, the field lacks a universal benchmark to assess an agent’s memory capabilities across diverse scenarios. This gap is particularly evident in tabletop robotic manipulation, where memory is essential for solving tasks with partial observability and ensuring robust performance, yet no standardized benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills Assessment Suite for Agents), a comprehensive benchmark for memory RL, with three key contributions: (1) we propose a comprehensive classification framework for memory-intensive RL tasks, (2) we collect MIKASA-Base — a unified benchmark that enables systematic evaluation of memory-enhanced agents across diverse scenarios, and (3) we develop MIKASA-Robo (pip install mikasa-robo-suite) — a novel benchmark of 32 carefully designed memory-intensive tasks that assess memory capabilities in tabletop robotic manipulation. Our work introduces a unified framework to advance memory RL research, enabling more robust systems for real-world use. MIKASA is available at https://tinyurl.com/membenchrobots.
arXiv:2502.10550v3 Announce Type: replace-cross
Abstract: Memory is crucial for enabling agents to tackle complex tasks with temporal and spatial dependencies. While many reinforcement learning (RL) algorithms incorporate memory, the field lacks a universal benchmark to assess an agent’s memory capabilities across diverse scenarios. This gap is particularly evident in tabletop robotic manipulation, where memory is essential for solving tasks with partial observability and ensuring robust performance, yet no standardized benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills Assessment Suite for Agents), a comprehensive benchmark for memory RL, with three key contributions: (1) we propose a comprehensive classification framework for memory-intensive RL tasks, (2) we collect MIKASA-Base — a unified benchmark that enables systematic evaluation of memory-enhanced agents across diverse scenarios, and (3) we develop MIKASA-Robo (pip install mikasa-robo-suite) — a novel benchmark of 32 carefully designed memory-intensive tasks that assess memory capabilities in tabletop robotic manipulation. Our work introduces a unified framework to advance memory RL research, enabling more robust systems for real-world use. MIKASA is available at https://tinyurl.com/membenchrobots. Read More
How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory ConsolidationMarkTechPost In this tutorial, we build an EverMem-style persistent agent OS. We combine short-term conversational context (STM) with long-term vector memory using FAISS so the agent can recall relevant past information before generating each response. Alongside semantic memory, we also store structured records in SQLite to persist metadata like timestamps, importance scores, and memory signals (preference,
The post How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory Consolidation appeared first on MarkTechPost.
In this tutorial, we build an EverMem-style persistent agent OS. We combine short-term conversational context (STM) with long-term vector memory using FAISS so the agent can recall relevant past information before generating each response. Alongside semantic memory, we also store structured records in SQLite to persist metadata like timestamps, importance scores, and memory signals (preference,
The post How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory Consolidation appeared first on MarkTechPost. Read More
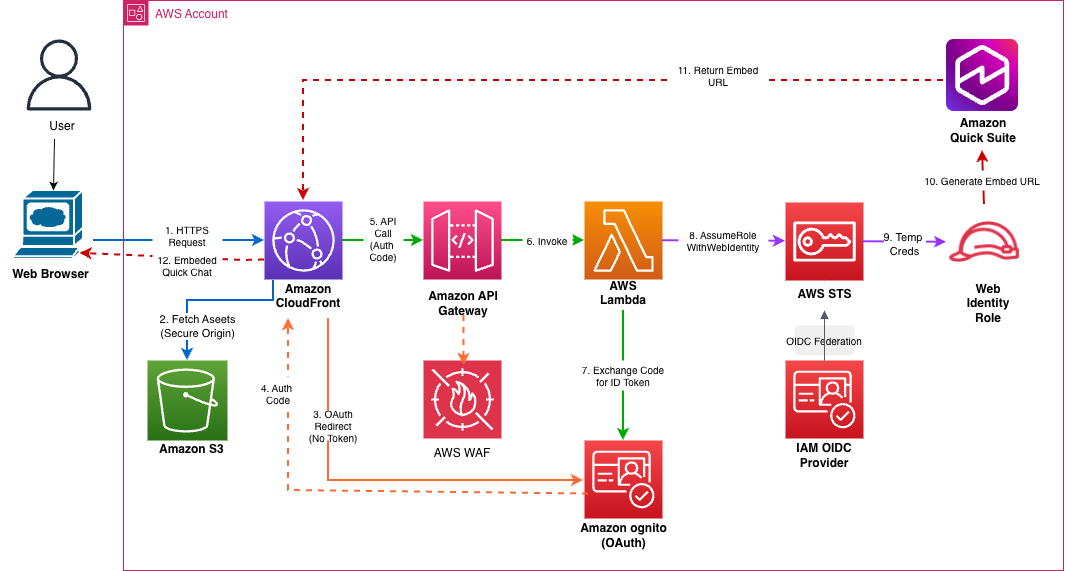
Embed Amazon Quick Suite chat agents in enterprise applicationsArtificial Intelligence Organizations find it challenging to implement a secure embedded chat in their applications and can require weeks of development to build authentication, token validation, domain security, and global distribution infrastructure. In this post, we show you how to solve this with a one-click deployment solution to embed the chat agents using the Quick Suite Embedding SDK in enterprise portals.
Organizations find it challenging to implement a secure embedded chat in their applications and can require weeks of development to build authentication, token validation, domain security, and global distribution infrastructure. In this post, we show you how to solve this with a one-click deployment solution to embed the chat agents using the Quick Suite Embedding SDK in enterprise portals. Read More
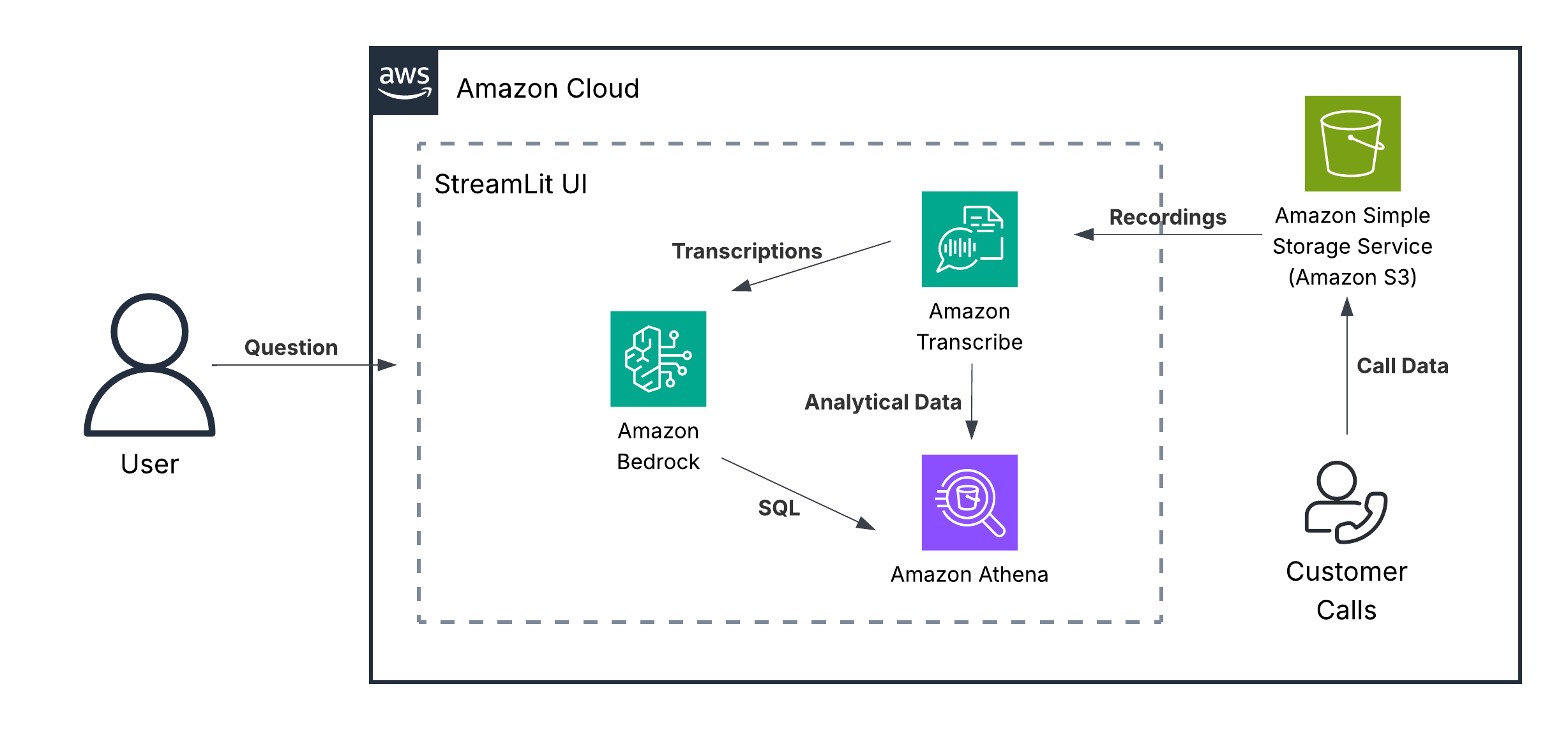
Unlock powerful call center analytics with Amazon Nova foundation modelsArtificial Intelligence In this post, we discuss how Amazon Nova demonstrates capabilities in conversational analytics, call classification, and other use cases often relevant to contact center solutions. We examine these capabilities for both single-call and multi-call analytics use cases.
In this post, we discuss how Amazon Nova demonstrates capabilities in conversational analytics, call classification, and other use cases often relevant to contact center solutions. We examine these capabilities for both single-call and multi-call analytics use cases. Read More

How Ricoh built a scalable intelligent document processing solution on AWSArtificial Intelligence This post explores how Ricoh built a standardized, multi-tenant solution for automated document classification and extraction using the AWS GenAI IDP Accelerator as a foundation, transforming their document processing from a custom-engineering bottleneck into a scalable, repeatable service.
This post explores how Ricoh built a standardized, multi-tenant solution for automated document classification and extraction using the AWS GenAI IDP Accelerator as a foundation, transforming their document processing from a custom-engineering bottleneck into a scalable, repeatable service. Read More
LangWatch Open Sources the Missing Evaluation Layer for AI Agents to Enable End-to-End Tracing, Simulation, and Systematic TestingMarkTechPost As AI development shifts from simple chat interfaces to complex, multi-step autonomous agents, the industry has encountered a significant bottleneck: non-determinism. Unlike traditional software where code follows a predictable path, agents built on LLMs introduce a high degree of variance. LangWatch is an open-source platform designed to address this by providing a standardized layer for
The post LangWatch Open Sources the Missing Evaluation Layer for AI Agents to Enable End-to-End Tracing, Simulation, and Systematic Testing appeared first on MarkTechPost.
As AI development shifts from simple chat interfaces to complex, multi-step autonomous agents, the industry has encountered a significant bottleneck: non-determinism. Unlike traditional software where code follows a predictable path, agents built on LLMs introduce a high degree of variance. LangWatch is an open-source platform designed to address this by providing a standardized layer for
The post LangWatch Open Sources the Missing Evaluation Layer for AI Agents to Enable End-to-End Tracing, Simulation, and Systematic Testing appeared first on MarkTechPost. Read More

A Guide to Kedro: Your Production-Ready Data Science ToolboxKDnuggets This article introduces and explores Kedro’s main features, guiding you through its core concepts for a better understanding before diving deeper into this framework for addressing real data science projects.
This article introduces and explores Kedro’s main features, guiding you through its core concepts for a better understanding before diving deeper into this framework for addressing real data science projects. Read More
Escaping the Prototype Mirage: Why Enterprise AI StallsTowards Data Science Too many prototypes, too few products
The post Escaping the Prototype Mirage: Why Enterprise AI Stalls appeared first on Towards Data Science.
Too many prototypes, too few products
The post Escaping the Prototype Mirage: Why Enterprise AI Stalls appeared first on Towards Data Science. Read More

5 Useful Python Scripts to Automate Exploratory Data AnalysisKDnuggets Spending hours cleaning, summarizing, and visualizing your data manually? Automate your exploratory data analysis workflow with these 5 ready-to-use Python scripts.
Spending hours cleaning, summarizing, and visualizing your data manually? Automate your exploratory data analysis workflow with these 5 ready-to-use Python scripts. Read More
RAG with Hybrid Search: How Does Keyword Search Work?Towards Data Science Understanding keyword search, TF-IDF, and BM25
The post RAG with Hybrid Search: How Does Keyword Search Work? appeared first on Towards Data Science.
Understanding keyword search, TF-IDF, and BM25
The post RAG with Hybrid Search: How Does Keyword Search Work? appeared first on Towards Data Science. Read More