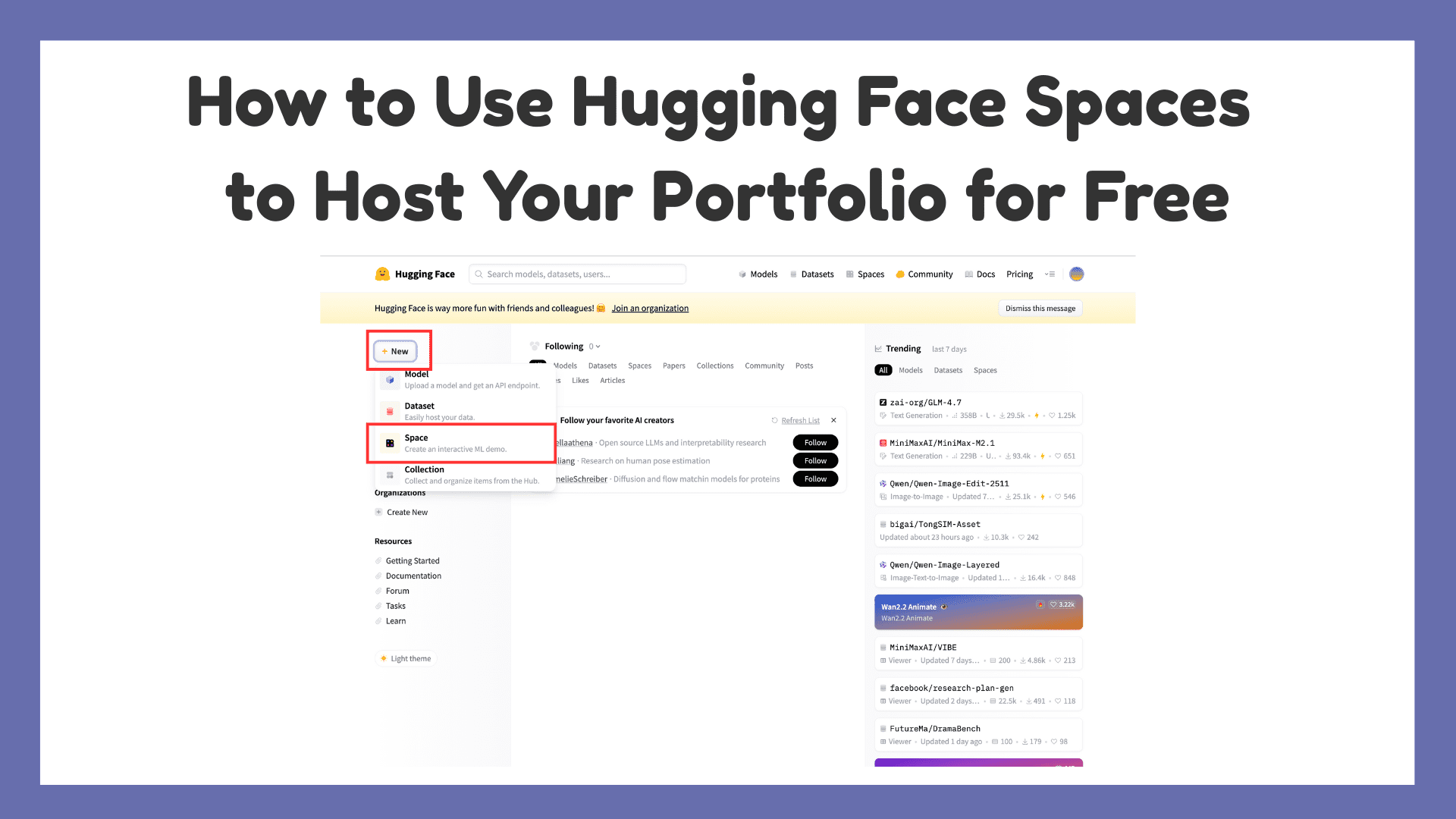
How to Use Hugging Face Spaces to Host Your Portfolio for FreeKDnuggets Hugging Face Spaces is a free way to host a portfolio with live demos, and this article walks through setting one up step by step.
Hugging Face Spaces is a free way to host a portfolio with live demos, and this article walks through setting one up step by step. Read More

RoPE, Clearly ExplainedTowards Data Science Going beyond the math to build intuition
The post RoPE, Clearly Explained appeared first on Towards Data Science.
Going beyond the math to build intuition
The post RoPE, Clearly Explained appeared first on Towards Data Science. Read More
7 Scikit-learn Tricks for Hyperparameter TuningKDnuggets Ready to learn these 7 Scikit-learn tricks that will take your machine learning models’ hyperparameter tuning skills to the next level?
Ready to learn these 7 Scikit-learn tricks that will take your machine learning models’ hyperparameter tuning skills to the next level? Read More

Insurers betting big on AI: AccentureAI News New research from Accenture has discovered insurance executives are planning on increased investment into AI during 2026 despite a widening skills gap in insurance organisations. Surveying 3,650 C-suite leaders over 20 industries and 20 countries, the Pulse of Change poll revealed 90% of the 218 senior insurance executives intend to spend more on AI over
The post Insurers betting big on AI: Accenture appeared first on AI News.
New research from Accenture has discovered insurance executives are planning on increased investment into AI during 2026 despite a widening skills gap in insurance organisations. Surveying 3,650 C-suite leaders over 20 industries and 20 countries, the Pulse of Change poll revealed 90% of the 218 senior insurance executives intend to spend more on AI over
The post Insurers betting big on AI: Accenture appeared first on AI News. Read More
Optimizing Vector Search: Why You Should Flatten Structured Data Towards Data Science An analysis of how flattening structured data can boost precision and recall by up to 20%
The post Optimizing Vector Search: Why You Should Flatten Structured Data appeared first on Towards Data Science.
An analysis of how flattening structured data can boost precision and recall by up to 20%
The post Optimizing Vector Search: Why You Should Flatten Structured Data appeared first on Towards Data Science. Read More

Beyond the Chatbox: Generative UI, AG-UI, and the Stack Behind Agent-Driven InterfacesMarkTechPost Most AI applications still showcase the model as a chat box. That interface is simple, but it hides what agents are actually doing, such as planning steps, calling tools, and updating state. Generative UI is about letting the agent drive real interface elements, for example tables, charts, forms, and progress indicators, so the experience feels
The post Beyond the Chatbox: Generative UI, AG-UI, and the Stack Behind Agent-Driven Interfaces appeared first on MarkTechPost.
Most AI applications still showcase the model as a chat box. That interface is simple, but it hides what agents are actually doing, such as planning steps, calling tools, and updating state. Generative UI is about letting the agent drive real interface elements, for example tables, charts, forms, and progress indicators, so the experience feels
The post Beyond the Chatbox: Generative UI, AG-UI, and the Stack Behind Agent-Driven Interfaces appeared first on MarkTechPost. Read More
Project Genie: Experimenting with infinite, interactive worldsGoogle DeepMind News Google AI Ultra subscribers in the U.S. can try out Project Genie, an experimental research prototype that lets you create and explore worlds.
Google AI Ultra subscribers in the U.S. can try out Project Genie, an experimental research prototype that lets you create and explore worlds. Read More
Google DeepMind Unveils AlphaGenome: A Unified Sequence-to-Function Model Using Hybrid Transformers and U-Nets to Decode the Human GenomeMarkTechPost Google DeepMind is expanding its biological toolkit beyond the world of protein folding. After the success of AlphaFold, the Google’s research team has introduced AlphaGenome. This is a unified deep learning model designed for sequence to function genomics. This represents a major shift in how we model the human genome. AlphaGenome does not treat DNA
The post Google DeepMind Unveils AlphaGenome: A Unified Sequence-to-Function Model Using Hybrid Transformers and U-Nets to Decode the Human Genome appeared first on MarkTechPost.
Google DeepMind is expanding its biological toolkit beyond the world of protein folding. After the success of AlphaFold, the Google’s research team has introduced AlphaGenome. This is a unified deep learning model designed for sequence to function genomics. This represents a major shift in how we model the human genome. AlphaGenome does not treat DNA
The post Google DeepMind Unveils AlphaGenome: A Unified Sequence-to-Function Model Using Hybrid Transformers and U-Nets to Decode the Human Genome appeared first on MarkTechPost. Read More
Understanding Post-Training Structural Changes in Large Language Modelscs.AI updates on arXiv.org arXiv:2509.17866v3 Announce Type: replace-cross
Abstract: Post-training fundamentally alters the behavior of large language models (LLMs), yet its impact on the internal parameter space remains poorly understood. In this work, we conduct a systematic singular value decomposition (SVD) analysis of principal linear layers in pretrained LLMs, focusing on two widely adopted post-training methods: instruction tuning and long-chain-of-thought (Long-CoT) distillation. Our analysis reveals two unexpected and robust structural changes: (1) a near-uniform geometric scaling of singular values across layers; and (2) highly consistent orthogonal transformations are applied to the left and right singular vectors of each matrix. Based on these findings, We propose a simple yet effective framework to describe the coordinated dynamics of parameters in LLMs, which elucidates why post-training inherently relies on the foundational capabilities developed during pre-training. Further experiments demonstrate that singular value scaling underpins the temperature-controlled regulatory mechanisms of post-training, while the coordinated rotation of singular vectors encodes the essential semantic alignment. These results challenge the prevailing view of the parameter space in large models as a black box, uncovering the first clear regularities in how parameters evolve during training, and providing a new perspective for deeper investigation into model parameter changes.
arXiv:2509.17866v3 Announce Type: replace-cross
Abstract: Post-training fundamentally alters the behavior of large language models (LLMs), yet its impact on the internal parameter space remains poorly understood. In this work, we conduct a systematic singular value decomposition (SVD) analysis of principal linear layers in pretrained LLMs, focusing on two widely adopted post-training methods: instruction tuning and long-chain-of-thought (Long-CoT) distillation. Our analysis reveals two unexpected and robust structural changes: (1) a near-uniform geometric scaling of singular values across layers; and (2) highly consistent orthogonal transformations are applied to the left and right singular vectors of each matrix. Based on these findings, We propose a simple yet effective framework to describe the coordinated dynamics of parameters in LLMs, which elucidates why post-training inherently relies on the foundational capabilities developed during pre-training. Further experiments demonstrate that singular value scaling underpins the temperature-controlled regulatory mechanisms of post-training, while the coordinated rotation of singular vectors encodes the essential semantic alignment. These results challenge the prevailing view of the parameter space in large models as a black box, uncovering the first clear regularities in how parameters evolve during training, and providing a new perspective for deeper investigation into model parameter changes. Read More
DeepBooTS: Dual-Stream Residual Boosting for Drift-Resilient Time-Series Forecastingcs.AI updates on arXiv.org arXiv:2511.06893v2 Announce Type: replace-cross
Abstract: Time-Series (TS) exhibits pronounced non-stationarity. Consequently, most forecasting methods display compromised robustness to concept drift, despite the prevalent application of instance normalization. We tackle this challenge by first analysing concept drift through a bias-variance lens and proving that weighted ensemble reduces variance without increasing bias. These insights motivate DeepBooTS, a novel end-to-end dual-stream residual-decreasing boosting method that progressively reconstructs the intrinsic signal. In our design, each block of a deep model becomes an ensemble of learners with an auxiliary output branch forming a highway to the final prediction. The block-wise outputs correct the residuals of previous blocks, leading to a learning-driven decomposition of both inputs and targets. This method enhances versatility and interpretability while substantially improving robustness to concept drift. Extensive experiments, including those on large-scale datasets, show that the proposed method outperforms existing methods by a large margin, yielding an average performance improvement of 15.8% across various datasets, establishing a new benchmark for TS forecasting.
arXiv:2511.06893v2 Announce Type: replace-cross
Abstract: Time-Series (TS) exhibits pronounced non-stationarity. Consequently, most forecasting methods display compromised robustness to concept drift, despite the prevalent application of instance normalization. We tackle this challenge by first analysing concept drift through a bias-variance lens and proving that weighted ensemble reduces variance without increasing bias. These insights motivate DeepBooTS, a novel end-to-end dual-stream residual-decreasing boosting method that progressively reconstructs the intrinsic signal. In our design, each block of a deep model becomes an ensemble of learners with an auxiliary output branch forming a highway to the final prediction. The block-wise outputs correct the residuals of previous blocks, leading to a learning-driven decomposition of both inputs and targets. This method enhances versatility and interpretability while substantially improving robustness to concept drift. Extensive experiments, including those on large-scale datasets, show that the proposed method outperforms existing methods by a large margin, yielding an average performance improvement of 15.8% across various datasets, establishing a new benchmark for TS forecasting. Read More