
Learning to Compose for Cross-domain Agentic Workflow Generationcs.AI updates on arXiv.org arXiv:2602.11114v1 Announce Type: cross
Abstract: Automatically generating agentic workflows — executable operator graphs or codes that orchestrate reasoning, verification, and repair — has become a practical way to solve complex tasks beyond what single-pass LLM generation can reliably handle. Yet what constitutes a good workflow depends heavily on the task distribution and the available operators. Under domain shift, current systems typically rely on iterative workflow refinement to discover a feasible workflow from a large workflow space, incurring high iteration costs and yielding unstable, domain-specific behavior. In response, we internalize a decompose-recompose-decide mechanism into an open-source LLM for cross-domain workflow generation. To decompose, we learn a compact set of reusable workflow capabilities across diverse domains. To recompose, we map each input task to a sparse composition over these bases to generate a task-specific workflow in a single pass. To decide, we attribute the success or failure of workflow generation to counterfactual contributions from learned capabilities, thereby capturing which capabilities actually drive success by their marginal effects. Across stringent multi-domain, cross-domain, and unseen-domain evaluations, our 1-pass generator surpasses SOTA refinement baselines that consume 20 iterations, while substantially reducing generation latency and cost.
arXiv:2602.11114v1 Announce Type: cross
Abstract: Automatically generating agentic workflows — executable operator graphs or codes that orchestrate reasoning, verification, and repair — has become a practical way to solve complex tasks beyond what single-pass LLM generation can reliably handle. Yet what constitutes a good workflow depends heavily on the task distribution and the available operators. Under domain shift, current systems typically rely on iterative workflow refinement to discover a feasible workflow from a large workflow space, incurring high iteration costs and yielding unstable, domain-specific behavior. In response, we internalize a decompose-recompose-decide mechanism into an open-source LLM for cross-domain workflow generation. To decompose, we learn a compact set of reusable workflow capabilities across diverse domains. To recompose, we map each input task to a sparse composition over these bases to generate a task-specific workflow in a single pass. To decide, we attribute the success or failure of workflow generation to counterfactual contributions from learned capabilities, thereby capturing which capabilities actually drive success by their marginal effects. Across stringent multi-domain, cross-domain, and unseen-domain evaluations, our 1-pass generator surpasses SOTA refinement baselines that consume 20 iterations, while substantially reducing generation latency and cost. Read More
Found-RL: foundation model-enhanced reinforcement learning for autonomous drivingcs.AI updates on arXiv.org arXiv:2602.10458v1 Announce Type: new
Abstract: Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP’s dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
arXiv:2602.10458v1 Announce Type: new
Abstract: Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP’s dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl. Read More
NVIDIA Nemotron 3 Nano 30B MoE model is now available in Amazon SageMaker JumpStartArtificial Intelligence Today we’re excited to announce that the NVIDIA Nemotron 3 Nano 30B model with 3B active parameters is now generally available in the Amazon SageMaker JumpStart model catalog. You can accelerate innovation and deliver tangible business value with Nemotron 3 Nano on Amazon Web Services (AWS) without having to manage model deployment complexities. You can power your generative AI applications with Nemotron capabilities using the managed deployment capabilities offered by SageMaker JumpStart.
Today we’re excited to announce that the NVIDIA Nemotron 3 Nano 30B model with 3B active parameters is now generally available in the Amazon SageMaker JumpStart model catalog. You can accelerate innovation and deliver tangible business value with Nemotron 3 Nano on Amazon Web Services (AWS) without having to manage model deployment complexities. You can power your generative AI applications with Nemotron capabilities using the managed deployment capabilities offered by SageMaker JumpStart. Read More

Red Hat unifies AI and tactical edge deployment for UK MODAI News The UK Ministry of Defence (MOD) has selected Red Hat to architect a unified AI and hybrid cloud backbone across its entire estate. Announced today, the agreement is designed to break down data silos and accelerate the deployment of AI models from the data centre to the tactical edge. For CIOs, it’s part of a
The post Red Hat unifies AI and tactical edge deployment for UK MOD appeared first on AI News.
The UK Ministry of Defence (MOD) has selected Red Hat to architect a unified AI and hybrid cloud backbone across its entire estate. Announced today, the agreement is designed to break down data silos and accelerate the deployment of AI models from the data centre to the tactical edge. For CIOs, it’s part of a
The post Red Hat unifies AI and tactical edge deployment for UK MOD appeared first on AI News. Read More
MACD: Model-Aware Contrastive Decoding via Counterfactual Datacs.AI updates on arXiv.org arXiv:2602.01740v2 Announce Type: replace
Abstract: Video language models (Video-LLMs) are prone to hallucinations, often generating plausible but ungrounded content when visual evidence is weak, ambiguous, or biased. Existing decoding methods, such as contrastive decoding (CD), rely on random perturbations to construct contrastive data for mitigating hallucination patterns. However, such a way is hard to control the visual cues that drive hallucination or well align with model weaknesses. We propose Model-aware Counterfactual Data based Contrastive Decoding (MACD), a new inference strategy that combines model-guided counterfactual construction with decoding. Our approach uses the Video-LLM’s own feedback to identify object regions most responsible for hallucination, generating targeted counterfactual inputs at the object level rather than arbitrary frame or temporal modifications. These model-aware counterfactual data is then integrated into CD to enforce evidence-grounded token selection during decoding. Experiments on EventHallusion, MVBench, Perception-test and Video-MME show that MACD consistently reduces hallucination while maintaining or improving task accuracy across diverse Video-LLMs, including Qwen and InternVL families. The method is especially effective in challenging scenarios involving small, occluded, or co-occurring objects. Our code and data will be publicly released.
arXiv:2602.01740v2 Announce Type: replace
Abstract: Video language models (Video-LLMs) are prone to hallucinations, often generating plausible but ungrounded content when visual evidence is weak, ambiguous, or biased. Existing decoding methods, such as contrastive decoding (CD), rely on random perturbations to construct contrastive data for mitigating hallucination patterns. However, such a way is hard to control the visual cues that drive hallucination or well align with model weaknesses. We propose Model-aware Counterfactual Data based Contrastive Decoding (MACD), a new inference strategy that combines model-guided counterfactual construction with decoding. Our approach uses the Video-LLM’s own feedback to identify object regions most responsible for hallucination, generating targeted counterfactual inputs at the object level rather than arbitrary frame or temporal modifications. These model-aware counterfactual data is then integrated into CD to enforce evidence-grounded token selection during decoding. Experiments on EventHallusion, MVBench, Perception-test and Video-MME show that MACD consistently reduces hallucination while maintaining or improving task accuracy across diverse Video-LLMs, including Qwen and InternVL families. The method is especially effective in challenging scenarios involving small, occluded, or co-occurring objects. Our code and data will be publicly released. Read More
How to Build an Atomic-Agents RAG Pipeline with Typed Schemas, Dynamic Context Injection, and Agent ChainingMarkTechPost In this tutorial, we build an advanced, end-to-end learning pipeline around Atomic-Agents by wiring together typed agent interfaces, structured prompting, and a compact retrieval layer that grounds outputs in real project documentation. Also, we demonstrate how to plan retrieval, retrieve relevant context, inject it dynamically into an answering agent, and run an interactive loop that
The post How to Build an Atomic-Agents RAG Pipeline with Typed Schemas, Dynamic Context Injection, and Agent Chaining appeared first on MarkTechPost.
In this tutorial, we build an advanced, end-to-end learning pipeline around Atomic-Agents by wiring together typed agent interfaces, structured prompting, and a compact retrieval layer that grounds outputs in real project documentation. Also, we demonstrate how to plan retrieval, retrieve relevant context, inject it dynamically into an answering agent, and run an interactive loop that
The post How to Build an Atomic-Agents RAG Pipeline with Typed Schemas, Dynamic Context Injection, and Agent Chaining appeared first on MarkTechPost. Read More

Why Most People Misuse SMOTE, And How to Do It RightKDnuggets Keys for oversampling your data for addressing class imbalance issues, the right way.
Keys for oversampling your data for addressing class imbalance issues, the right way. Read More

Mastering Amazon Bedrock throttling and service availability: A comprehensive guideArtificial Intelligence This post shows you how to implement robust error handling strategies that can help improve application reliability and user experience when using Amazon Bedrock. We’ll dive deep into strategies for optimizing performances for the application with these errors. Whether this is for a fairly new application or matured AI application, in this post you will be able to find the practical guidelines to operate with on these errors.
This post shows you how to implement robust error handling strategies that can help improve application reliability and user experience when using Amazon Bedrock. We’ll dive deep into strategies for optimizing performances for the application with these errors. Whether this is for a fairly new application or matured AI application, in this post you will be able to find the practical guidelines to operate with on these errors. Read More
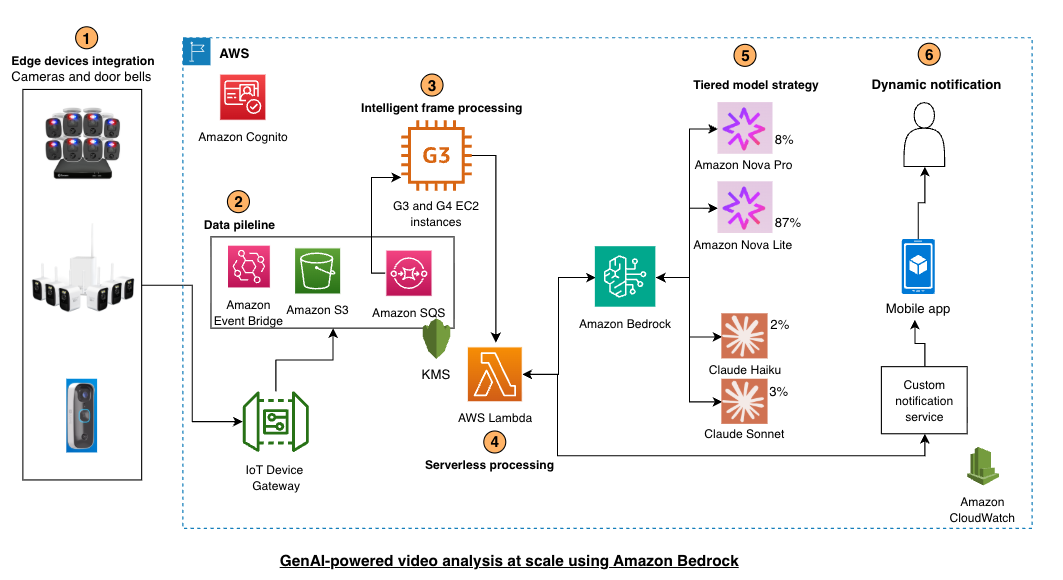
Swann provides Generative AI to millions of IoT Devices using Amazon Bedrock Artificial Intelligence
Swann provides Generative AI to millions of IoT Devices using Amazon BedrockArtificial Intelligence This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You’ll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices.
This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You’ll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices. Read More
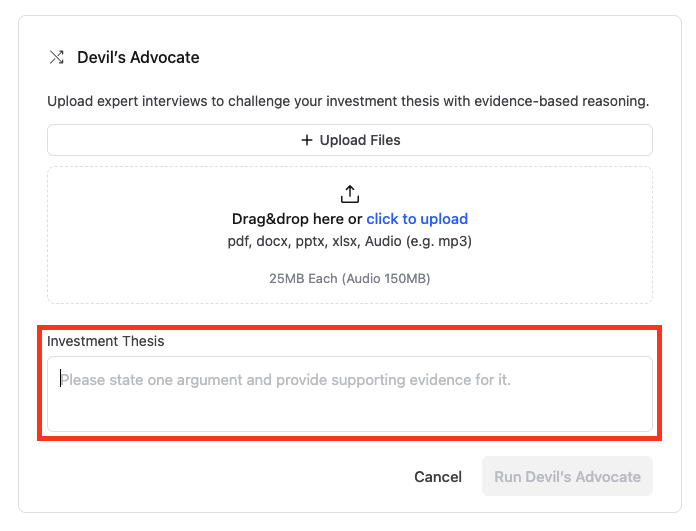
How LinqAlpha assesses investment theses using Devil’s Advocate on Amazon BedrockArtificial Intelligence LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate.
LinqAlpha is a Boston-based multi-agent AI system built specifically for institutional investors. The system supports and streamlines agentic workflows across company screening, primer generation, stock price catalyst mapping, and now, pressure-testing investment ideas through a new AI agent called Devil’s Advocate. In this post, we share how LinqAlpha uses Amazon Bedrock to build and scale Devil’s Advocate. Read More