
Power and Limitations of Aggregation in Compound AI Systemscs.AI updates on arXiv.org arXiv:2602.21556v1 Announce Type: new
Abstract: When designing compound AI systems, a common approach is to query multiple copies of the same model and aggregate the responses to produce a synthesized output. Given the homogeneity of these models, this raises the question of whether aggregation unlocks access to a greater set of outputs than querying a single model. In this work, we investigate the power and limitations of aggregation within a stylized principal-agent framework. This framework models how the system designer can partially steer each agent’s output through its reward function specification, but still faces limitations due to prompt engineering ability and model capabilities. Our analysis uncovers three natural mechanisms — feasibility expansion, support expansion, and binding set contraction — through which aggregation expands the set of outputs that are elicitable by the system designer. We prove that any aggregation operation must implement one of these mechanisms in order to be elicitability-expanding, and that strengthened versions of these mechanisms provide necessary and sufficient conditions that fully characterize elicitability-expansion. Finally, we provide an empirical illustration of our findings for LLMs deployed in a toy reference-generation task. Altogether, our results take a step towards characterizing when compound AI systems can overcome limitations in model capabilities and in prompt engineering.
arXiv:2602.21556v1 Announce Type: new
Abstract: When designing compound AI systems, a common approach is to query multiple copies of the same model and aggregate the responses to produce a synthesized output. Given the homogeneity of these models, this raises the question of whether aggregation unlocks access to a greater set of outputs than querying a single model. In this work, we investigate the power and limitations of aggregation within a stylized principal-agent framework. This framework models how the system designer can partially steer each agent’s output through its reward function specification, but still faces limitations due to prompt engineering ability and model capabilities. Our analysis uncovers three natural mechanisms — feasibility expansion, support expansion, and binding set contraction — through which aggregation expands the set of outputs that are elicitable by the system designer. We prove that any aggregation operation must implement one of these mechanisms in order to be elicitability-expanding, and that strengthened versions of these mechanisms provide necessary and sufficient conditions that fully characterize elicitability-expansion. Finally, we provide an empirical illustration of our findings for LLMs deployed in a toy reference-generation task. Altogether, our results take a step towards characterizing when compound AI systems can overcome limitations in model capabilities and in prompt engineering. Read More
ARLArena: A Unified Framework for Stable Agentic Reinforcement Learningcs.AI updates on arXiv.org arXiv:2602.21534v1 Announce Type: new
Abstract: Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines.
arXiv:2602.21534v1 Announce Type: new
Abstract: Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines. Read More
OGD4All: A Framework for Accessible Interaction with Geospatial Open Government Data Based on Large Language Modelscs.AI updates on arXiv.org arXiv:2602.00012v2 Announce Type: replace-cross
Abstract: We present OGD4All, a transparent, auditable, and reproducible framework based on Large Language Models (LLMs) to enhance citizens’ interaction with geospatial Open Government Data (OGD). The system combines semantic data retrieval, agentic reasoning for iterative code generation, and secure sandboxed execution that produces verifiable multimodal outputs. Evaluated on a 199-question benchmark covering both factual and unanswerable questions, across 430 City-of-Zurich datasets and 11 LLMs, OGD4All reaches 98% analytical correctness and 94% recall while reliably rejecting questions unsupported by available data, which minimizes hallucination risks. Statistical robustness tests, as well as expert feedback, show reliability and social relevance. The proposed approach shows how LLMs can provide explainable, multimodal access to public data, advancing trustworthy AI for open governance.
arXiv:2602.00012v2 Announce Type: replace-cross
Abstract: We present OGD4All, a transparent, auditable, and reproducible framework based on Large Language Models (LLMs) to enhance citizens’ interaction with geospatial Open Government Data (OGD). The system combines semantic data retrieval, agentic reasoning for iterative code generation, and secure sandboxed execution that produces verifiable multimodal outputs. Evaluated on a 199-question benchmark covering both factual and unanswerable questions, across 430 City-of-Zurich datasets and 11 LLMs, OGD4All reaches 98% analytical correctness and 94% recall while reliably rejecting questions unsupported by available data, which minimizes hallucination risks. Statistical robustness tests, as well as expert feedback, show reliability and social relevance. The proposed approach shows how LLMs can provide explainable, multimodal access to public data, advancing trustworthy AI for open governance. Read More
MoMaGen: Generating Demonstrations under Soft and Hard Constraints for Multi-Step Bimanual Mobile Manipulationcs.AI updates on arXiv.org arXiv:2510.18316v4 Announce Type: replace-cross
Abstract: Imitation learning from large-scale, diverse human demonstrations has been shown to be effective for training robots, but collecting such data is costly and time-consuming. This challenge intensifies for multi-step bimanual mobile manipulation, where humans must teleoperate both the mobile base and two high-DoF arms. Prior X-Gen works have developed automated data generation frameworks for static (bimanual) manipulation tasks, augmenting a few human demos in simulation with novel scene configurations to synthesize large-scale datasets. However, prior works fall short for bimanual mobile manipulation tasks for two major reasons: 1) a mobile base introduces the problem of how to place the robot base to enable downstream manipulation (reachability) and 2) an active camera introduces the problem of how to position the camera to generate data for a visuomotor policy (visibility). To address these challenges, MoMaGen formulates data generation as a constrained optimization problem that satisfies hard constraints (e.g., reachability) while balancing soft constraints (e.g., visibility while navigation). This formulation generalizes across most existing automated data generation approaches and offers a principled foundation for developing future methods. We evaluate on four multi-step bimanual mobile manipulation tasks and find that MoMaGen enables the generation of much more diverse datasets than previous methods. As a result of the dataset diversity, we also show that the data generated by MoMaGen can be used to train successful imitation learning policies using a single source demo. Furthermore, the trained policy can be fine-tuned with a very small amount of real-world data (40 demos) to be succesfully deployed on real robotic hardware. More details are on our project page: momagen.github.io.
arXiv:2510.18316v4 Announce Type: replace-cross
Abstract: Imitation learning from large-scale, diverse human demonstrations has been shown to be effective for training robots, but collecting such data is costly and time-consuming. This challenge intensifies for multi-step bimanual mobile manipulation, where humans must teleoperate both the mobile base and two high-DoF arms. Prior X-Gen works have developed automated data generation frameworks for static (bimanual) manipulation tasks, augmenting a few human demos in simulation with novel scene configurations to synthesize large-scale datasets. However, prior works fall short for bimanual mobile manipulation tasks for two major reasons: 1) a mobile base introduces the problem of how to place the robot base to enable downstream manipulation (reachability) and 2) an active camera introduces the problem of how to position the camera to generate data for a visuomotor policy (visibility). To address these challenges, MoMaGen formulates data generation as a constrained optimization problem that satisfies hard constraints (e.g., reachability) while balancing soft constraints (e.g., visibility while navigation). This formulation generalizes across most existing automated data generation approaches and offers a principled foundation for developing future methods. We evaluate on four multi-step bimanual mobile manipulation tasks and find that MoMaGen enables the generation of much more diverse datasets than previous methods. As a result of the dataset diversity, we also show that the data generated by MoMaGen can be used to train successful imitation learning policies using a single source demo. Furthermore, the trained policy can be fine-tuned with a very small amount of real-world data (40 demos) to be succesfully deployed on real robotic hardware. More details are on our project page: momagen.github.io. Read More
Dual-Channel Attention Guidance for Training-Free Image Editing Control in Diffusion Transformerscs.AI updates on arXiv.org arXiv:2602.18022v2 Announce Type: replace-cross
Abstract: Training-free control over editing intensity is a critical requirement for diffusion-based image editing models built on the Diffusion Transformer (DiT) architecture. Existing attention manipulation methods focus exclusively on the Key space to modulate attention routing, leaving the Value space — which governs feature aggregation — entirely unexploited. In this paper, we first reveal that both Key and Value projections in DiT’s multi-modal attention layers exhibit a pronounced bias-delta structure, where token embeddings cluster tightly around a layer-specific bias vector. Building on this observation, we propose Dual-Channel Attention Guidance (DCAG), a training-free framework that simultaneously manipulates both the Key channel (controlling where to attend) and the Value channel (controlling what to aggregate). We provide a theoretical analysis showing that the Key channel operates through the nonlinear softmax function, acting as a coarse control knob, while the Value channel operates through linear weighted summation, serving as a fine-grained complement. Together, the two-dimensional parameter space $(delta_k, delta_v)$ enables more precise editing-fidelity trade-offs than any single-channel method. Extensive experiments on the PIE-Bench benchmark (700 images, 10 editing categories) demonstrate that DCAG consistently outperforms Key-only guidance across all fidelity metrics, with the most significant improvements observed in localized editing tasks such as object deletion (4.9% LPIPS reduction) and object addition (3.2% LPIPS reduction).
arXiv:2602.18022v2 Announce Type: replace-cross
Abstract: Training-free control over editing intensity is a critical requirement for diffusion-based image editing models built on the Diffusion Transformer (DiT) architecture. Existing attention manipulation methods focus exclusively on the Key space to modulate attention routing, leaving the Value space — which governs feature aggregation — entirely unexploited. In this paper, we first reveal that both Key and Value projections in DiT’s multi-modal attention layers exhibit a pronounced bias-delta structure, where token embeddings cluster tightly around a layer-specific bias vector. Building on this observation, we propose Dual-Channel Attention Guidance (DCAG), a training-free framework that simultaneously manipulates both the Key channel (controlling where to attend) and the Value channel (controlling what to aggregate). We provide a theoretical analysis showing that the Key channel operates through the nonlinear softmax function, acting as a coarse control knob, while the Value channel operates through linear weighted summation, serving as a fine-grained complement. Together, the two-dimensional parameter space $(delta_k, delta_v)$ enables more precise editing-fidelity trade-offs than any single-channel method. Extensive experiments on the PIE-Bench benchmark (700 images, 10 editing categories) demonstrate that DCAG consistently outperforms Key-only guidance across all fidelity metrics, with the most significant improvements observed in localized editing tasks such as object deletion (4.9% LPIPS reduction) and object addition (3.2% LPIPS reduction). Read More
Nous Research Releases ‘Hermes Agent’ to Fix AI Forgetfulness with Multi-Level Memory and Dedicated Remote Terminal Access SupportMarkTechPost In the current AI landscape, we’ve become accustomed to the ‘ephemeral agent’—a brilliant but forgetful assistant that restarts its cognitive clock with every new chat session. While LLMs have become master coders, they lack the persistent state required to function as true teammates. Nous Research team released Hermes Agent, an open-source autonomous system designed to
The post Nous Research Releases ‘Hermes Agent’ to Fix AI Forgetfulness with Multi-Level Memory and Dedicated Remote Terminal Access Support appeared first on MarkTechPost.
In the current AI landscape, we’ve become accustomed to the ‘ephemeral agent’—a brilliant but forgetful assistant that restarts its cognitive clock with every new chat session. While LLMs have become master coders, they lack the persistent state required to function as true teammates. Nous Research team released Hermes Agent, an open-source autonomous system designed to
The post Nous Research Releases ‘Hermes Agent’ to Fix AI Forgetfulness with Multi-Level Memory and Dedicated Remote Terminal Access Support appeared first on MarkTechPost. Read More
1-2-3 Check: Enhancing Contextual Privacy in LLM via Multi-Agent Reasoningcs.AI updates on arXiv.org arXiv:2508.07667v3 Announce Type: replace
Abstract: Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (textbf{18%} on ConfAIde and textbf{19%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs.
arXiv:2508.07667v3 Announce Type: replace
Abstract: Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (textbf{18%} on ConfAIde and textbf{19%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs. Read More
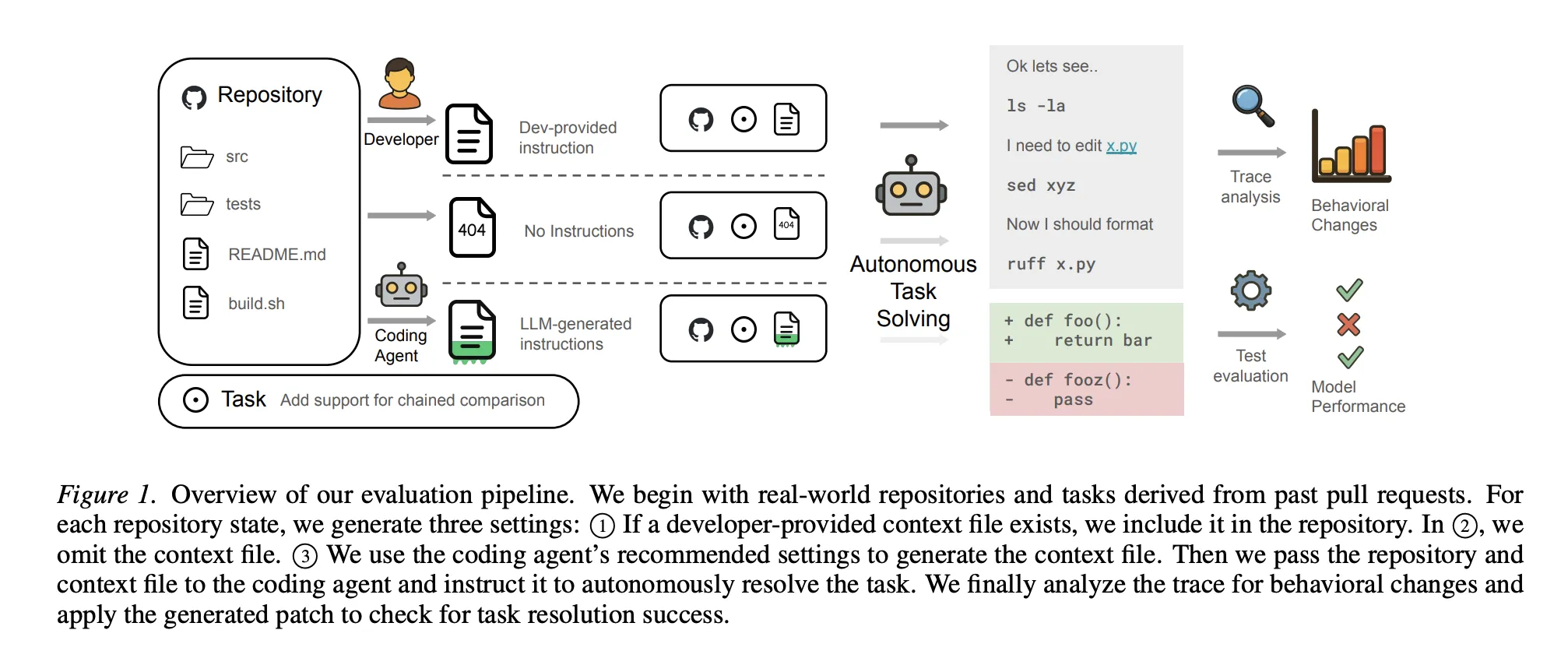
New ETH Zurich Study Proves Your AI Coding Agents are Failing Because Your AGENTS.md Files are too DetailedMarkTechPost In the high-stakes world of AI, ‘Context Engineering’ has emerged as the latest frontier for squeezing performance out of LLMs. Industry leaders have touted AGENTS.md (and its cousins like CLAUDE.md) as the ultimate configuration point for coding agents—a repository-level ‘North Star’ injected into every conversation to guide the AI through complex codebases. But a recent
The post New ETH Zurich Study Proves Your AI Coding Agents are Failing Because Your AGENTS.md Files are too Detailed appeared first on MarkTechPost.
In the high-stakes world of AI, ‘Context Engineering’ has emerged as the latest frontier for squeezing performance out of LLMs. Industry leaders have touted AGENTS.md (and its cousins like CLAUDE.md) as the ultimate configuration point for coding agents—a repository-level ‘North Star’ injected into every conversation to guide the AI through complex codebases. But a recent
The post New ETH Zurich Study Proves Your AI Coding Agents are Failing Because Your AGENTS.md Files are too Detailed appeared first on MarkTechPost. Read More
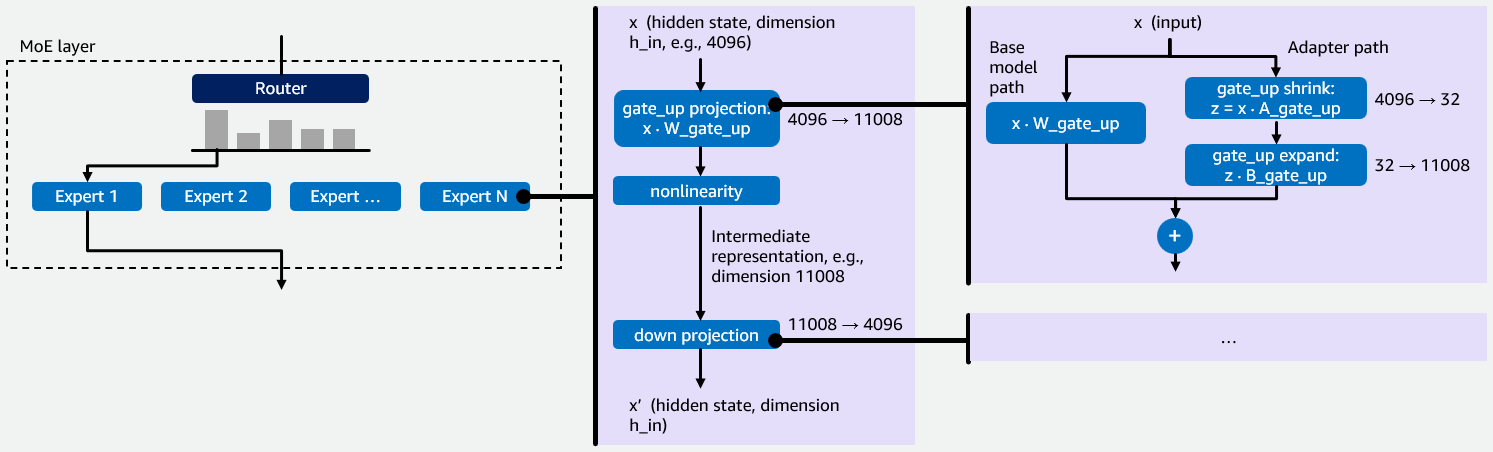
Efficiently serve dozens of fine-tuned models with vLLM on Amazon SageMaker AI and Amazon BedrockArtificial Intelligence In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post.
In this post, we explain how we implemented multi-LoRA inference for Mixture of Experts (MoE) models in vLLM, describe the kernel-level optimizations we performed, and show you how you can benefit from this work. We use GPT-OSS 20B as our primary example throughout this post. Read More
Scaling Feature Engineering Pipelines with Feast and RayTowards Data Science Utilizing feature stores like Feast and distributed compute frameworks like Ray in production machine learning systems
The post Scaling Feature Engineering Pipelines with Feast and Ray appeared first on Towards Data Science.
Utilizing feature stores like Feast and distributed compute frameworks like Ray in production machine learning systems
The post Scaling Feature Engineering Pipelines with Feast and Ray appeared first on Towards Data Science. Read More