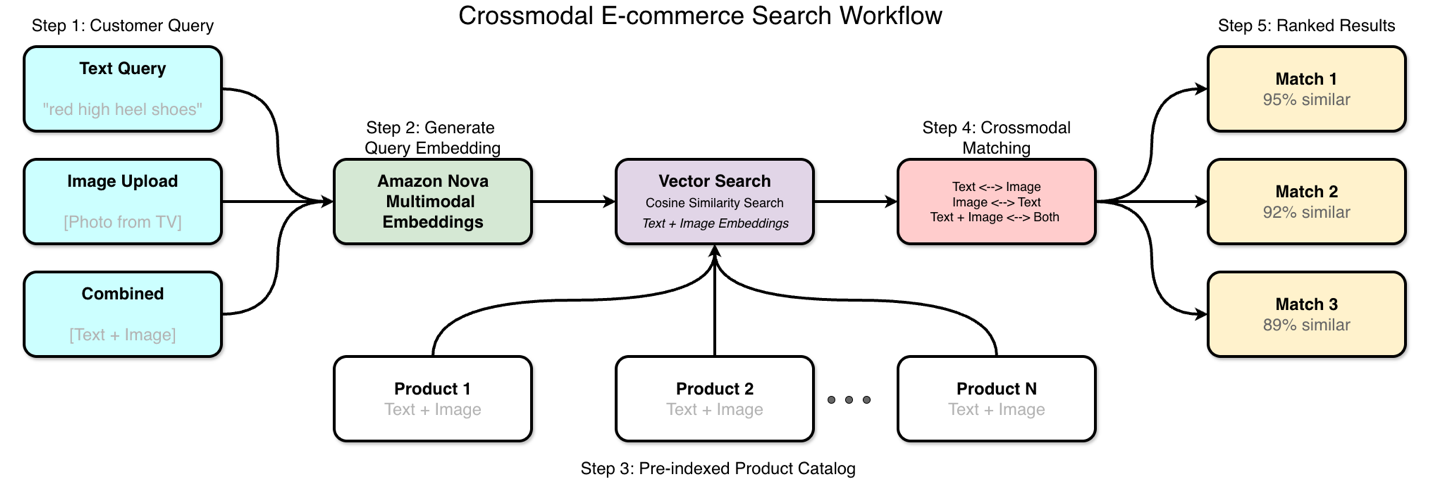
Crossmodal search with Amazon Nova Multimodal EmbeddingsArtificial Intelligence In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications.
In this post, we explore how Amazon Nova Multimodal Embeddings addresses the challenges of crossmodal search through a practical ecommerce use case. We examine the technical limitations of traditional approaches and demonstrate how Amazon Nova Multimodal Embeddings enables retrieval across text, images, and other modalities. You learn how to implement a crossmodal search system by generating embeddings, handling queries, and measuring performance. We provide working code examples and share how to add these capabilities to your applications. Read More
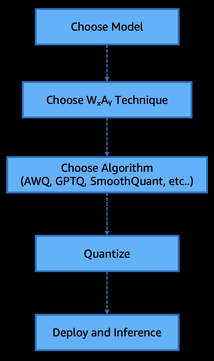
Accelerating LLM inference with post-training weight and activation using AWQ and GPTQ on Amazon SageMaker AIArtificial Intelligence Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker.
Quantized models can be seamlessly deployed on Amazon SageMaker AI using a few lines of code. In this post, we explore why quantization matters—how it enables lower-cost inference, supports deployment on resource-constrained hardware, and reduces both the financial and environmental impact of modern LLMs, while preserving most of their original performance. We also take a deep dive into the principles behind PTQ and demonstrate how to quantize the model of your choice and deploy it on Amazon SageMaker. Read More

Datadog: How AI code reviews slash incident riskAI News Integrating AI into code review workflows allows engineering leaders to detect systemic risks that often evade human detection at scale. For engineering leaders managing distributed systems, the trade-off between deployment speed and operational stability often defines the success of their platform. Datadog, a company responsible for the observability of complex infrastructures worldwide, operates under intense
The post Datadog: How AI code reviews slash incident risk appeared first on AI News.
Integrating AI into code review workflows allows engineering leaders to detect systemic risks that often evade human detection at scale. For engineering leaders managing distributed systems, the trade-off between deployment speed and operational stability often defines the success of their platform. Datadog, a company responsible for the observability of complex infrastructures worldwide, operates under intense
The post Datadog: How AI code reviews slash incident risk appeared first on AI News. Read More

How LLMs Handle Infinite Context With Finite MemoryTowards Data Science Achieving infinite context with 114× less memory
The post How LLMs Handle Infinite Context With Finite Memory appeared first on Towards Data Science.
Achieving infinite context with 114× less memory
The post How LLMs Handle Infinite Context With Finite Memory appeared first on Towards Data Science. Read More

How Beekeeper optimized user personalization with Amazon BedrockArtificial Intelligence Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models.
Beekeeper’s automated leaderboard approach and human feedback loop system for dynamic LLM and prompt pair selection addresses the key challenges organizations face in navigating the rapidly evolving landscape of language models. Read More
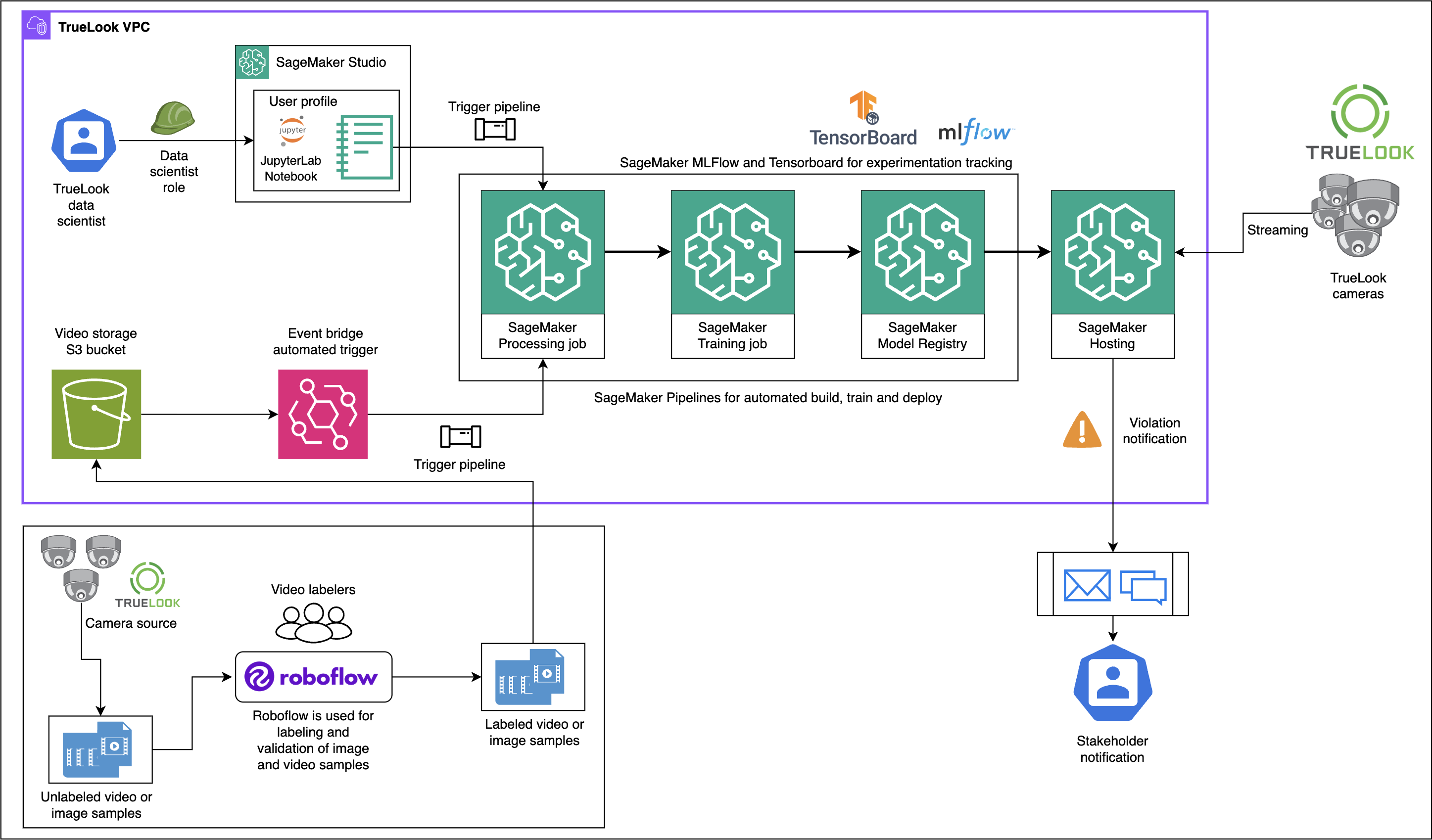
Architecting TrueLook’s AI-powered construction safety system on Amazon SageMaker AIArtificial Intelligence This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference.
This post provides a detailed architectural overview of how TrueLook built its AI-powered safety monitoring system using SageMaker AI, highlighting key technical decisions, pipeline design patterns, and MLOps best practices. You will gain valuable insights into designing scalable computer vision solutions on AWS, particularly around model training workflows, automated pipeline creation, and production deployment strategies for real-time inference. Read More
Autonomy without accountability: The real AI riskAI News If you have ever taken a self-driving Uber through downtown LA, you might recognise the strange sense of uncertainty that settles in when there is no driver and no conversation, just a quiet car making assumptions about the world around it. The journey feels fine until the car misreads a shadow or slows abruptly for
The post Autonomy without accountability: The real AI risk appeared first on AI News.
If you have ever taken a self-driving Uber through downtown LA, you might recognise the strange sense of uncertainty that settles in when there is no driver and no conversation, just a quiet car making assumptions about the world around it. The journey feels fine until the car misreads a shadow or slows abruptly for
The post Autonomy without accountability: The real AI risk appeared first on AI News. Read More
Mastering Non-Linear Data: A Guide to Scikit-Learn’s SplineTransformerTowards Data Science Forget stiff lines and wild polynomials. Discover why Splines are the “Goldilocks” of feature engineering, offering the perfect balance of flexibility and discipline for non-linear data using Scikit-Learn’s SplineTransformer.
The post Mastering Non-Linear Data: A Guide to Scikit-Learn’s SplineTransformer appeared first on Towards Data Science.
Forget stiff lines and wild polynomials. Discover why Splines are the “Goldilocks” of feature engineering, offering the perfect balance of flexibility and discipline for non-linear data using Scikit-Learn’s SplineTransformer.
The post Mastering Non-Linear Data: A Guide to Scikit-Learn’s SplineTransformer appeared first on Towards Data Science. Read More

From cloud to factory – humanoid robots coming to workplacesAI News The Microsoft-Hexagon partnerships may mark a turning point in the acceptance of humanoid robots in the workplace, as prototypes become operational realities.
The post From cloud to factory – humanoid robots coming to workplaces appeared first on AI News.
The Microsoft-Hexagon partnerships may mark a turning point in the acceptance of humanoid robots in the workplace, as prototypes become operational realities.
The post From cloud to factory – humanoid robots coming to workplaces appeared first on AI News. Read More

5 Useful Python Scripts to Automate Data CleaningKDnuggets Tired of repetitive data cleaning tasks? This article covers five Python scripts that handle common data cleaning tasks efficiently and reliably.
Tired of repetitive data cleaning tasks? This article covers five Python scripts that handle common data cleaning tasks efficiently and reliably. Read More