
From ‘Dataslows’ to Dataflows: The Gen2 Performance Revolution in Microsoft FabricTowards Data Science Dataflows were (rightly?) considered “the slowest and least performant option” for ingesting data into Power BI/Microsoft Fabric. However, things are changing rapidly and the latest Dataflow enhancements changes how we play the game
The post From ‘Dataslows’ to Dataflows: The Gen2 Performance Revolution in Microsoft Fabric appeared first on Towards Data Science.
Dataflows were (rightly?) considered “the slowest and least performant option” for ingesting data into Power BI/Microsoft Fabric. However, things are changing rapidly and the latest Dataflow enhancements changes how we play the game
The post From ‘Dataslows’ to Dataflows: The Gen2 Performance Revolution in Microsoft Fabric appeared first on Towards Data Science. Read More
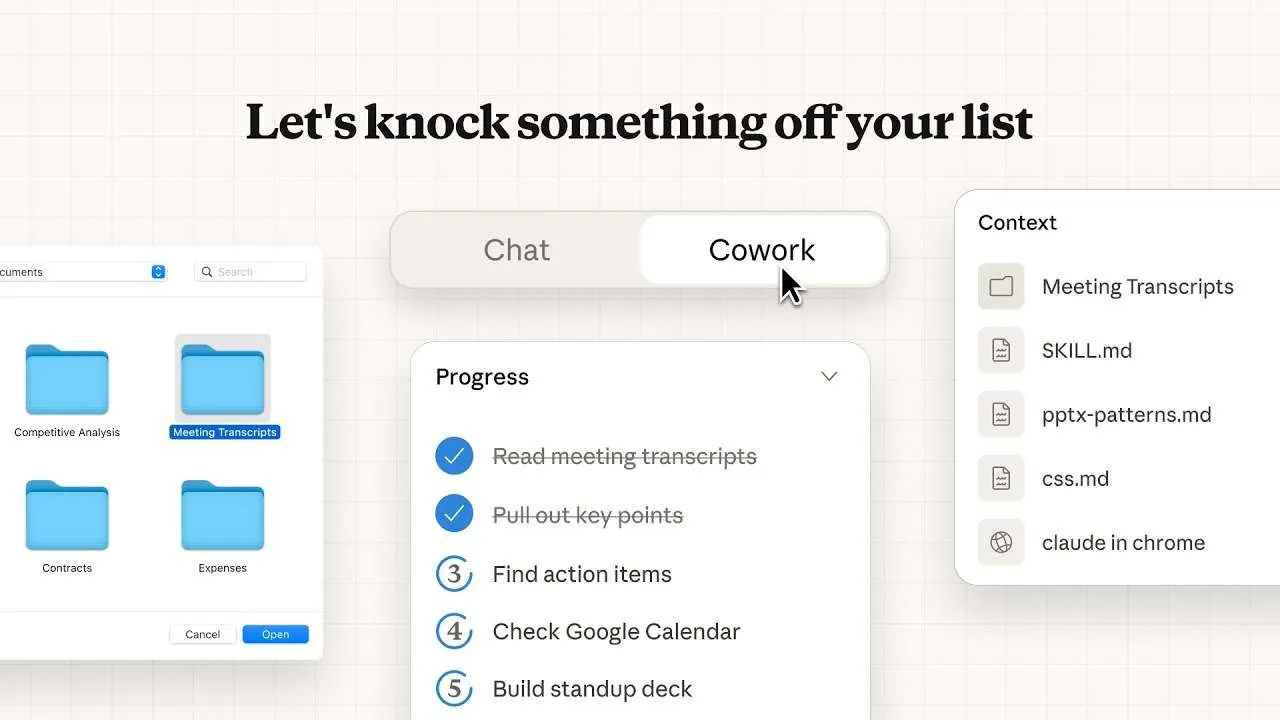
Anthropic Releases Cowork As Claude’s Local File System Agent For Everyday WorkMarkTechPost Anthropic has released Cowork, a new feature that runs agentic workflows on local files for non coding tasks currently available in research preview inside the Claude macOS desktop app. What Cowork Does At The File System Level Cowork currently runs as a dedicated mode in the Claude desktop app. When you start a Cowork session,
The post Anthropic Releases Cowork As Claude’s Local File System Agent For Everyday Work appeared first on MarkTechPost.
Anthropic has released Cowork, a new feature that runs agentic workflows on local files for non coding tasks currently available in research preview inside the Claude macOS desktop app. What Cowork Does At The File System Level Cowork currently runs as a dedicated mode in the Claude desktop app. When you start a Cowork session,
The post Anthropic Releases Cowork As Claude’s Local File System Agent For Everyday Work appeared first on MarkTechPost. Read More
CSV vs. Parquet vs. Arrow: Storage Formats ExplainedKDnuggets Same data, different formats, very different performance.
Same data, different formats, very different performance. Read More
Under the Uzès Sun: When Historical Data Reveals the Climate ChangeTowards Data Science Longer summers, milder winters: analysis of temperature trends in Uzès, France, year after year.
The post Under the Uzès Sun: When Historical Data Reveals the Climate Change appeared first on Towards Data Science.
Longer summers, milder winters: analysis of temperature trends in Uzès, France, year after year.
The post Under the Uzès Sun: When Historical Data Reveals the Climate Change appeared first on Towards Data Science. Read More

Understanding the Layers of AI Observability in the Age of LLMsMarkTechPost Artificial intelligence (AI) observability refers to the ability to understand, monitor, and evaluate AI systems by tracking their unique metrics—such as token usage, response quality, latency, and model drift. Unlike traditional software, large language models (LLMs) and other generative AI applications are probabilistic in nature. They do not follow fixed, transparent execution paths, which makes
The post Understanding the Layers of AI Observability in the Age of LLMs appeared first on MarkTechPost.
Artificial intelligence (AI) observability refers to the ability to understand, monitor, and evaluate AI systems by tracking their unique metrics—such as token usage, response quality, latency, and model drift. Unlike traditional software, large language models (LLMs) and other generative AI applications are probabilistic in nature. They do not follow fixed, transparent execution paths, which makes
The post Understanding the Layers of AI Observability in the Age of LLMs appeared first on MarkTechPost. Read More
How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using GarakMarkTechPost In this tutorial, we build an advanced, multi-turn crescendo-style red-teaming harness using Garak to evaluate how large language models behave under gradual conversational pressure. We implement a custom iterative probe and a lightweight detector to simulate realistic escalation patterns in which benign prompts slowly pivot toward sensitive requests, and we assess whether the model maintains
The post How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using Garak appeared first on MarkTechPost.
In this tutorial, we build an advanced, multi-turn crescendo-style red-teaming harness using Garak to evaluate how large language models behave under gradual conversational pressure. We implement a custom iterative probe and a lightweight detector to simulate realistic escalation patterns in which benign prompts slowly pivot toward sensitive requests, and we assess whether the model maintains
The post How to Build a Multi-Turn Crescendo Red-Teaming Pipeline to Evaluate and Stress-Test LLM Safety Using Garak appeared first on MarkTechPost. Read More
This AI spots dangerous blood cells doctors often missArtificial Intelligence News — ScienceDaily A generative AI system can now analyze blood cells with greater accuracy and confidence than human experts, detecting subtle signs of diseases like leukemia. It not only spots rare abnormalities but also recognizes its own uncertainty, making it a powerful support tool for clinicians.
A generative AI system can now analyze blood cells with greater accuracy and confidence than human experts, detecting subtle signs of diseases like leukemia. It not only spots rare abnormalities but also recognizes its own uncertainty, making it a powerful support tool for clinicians. Read More

Allister Frost: Tackling workforce anxiety for AI integration successAI News Navigating workforce anxiety remains a primary challenge for leaders as AI integration defines modern enterprise success. For enterprise leaders, deploying AI is less a technical hurdle than a complex exercise in change management. The reality for many organisations is that, while algorithms offer efficiency, the human element dictates the speed of adoption. Data from the
The post Allister Frost: Tackling workforce anxiety for AI integration success appeared first on AI News.
Navigating workforce anxiety remains a primary challenge for leaders as AI integration defines modern enterprise success. For enterprise leaders, deploying AI is less a technical hurdle than a complex exercise in change management. The reality for many organisations is that, while algorithms offer efficiency, the human element dictates the speed of adoption. Data from the
The post Allister Frost: Tackling workforce anxiety for AI integration success appeared first on AI News. Read More
Why Your ML Model Works in Training But Fails in ProductionTowards Data Science Hard lessons from building production ML systems where data leaks, defaults lie, populations shift, and time does not behave the way we expect.
The post Why Your ML Model Works in Training But Fails in Production appeared first on Towards Data Science.
Hard lessons from building production ML systems where data leaks, defaults lie, populations shift, and time does not behave the way we expect.
The post Why Your ML Model Works in Training But Fails in Production appeared first on Towards Data Science. Read More

5 Useful Python Scripts for Effective Feature EngineeringKDnuggets Feature engineering doesn’t have to be complex. These 5 Python scripts help you create meaningful features that improve model performance.
Feature engineering doesn’t have to be complex. These 5 Python scripts help you create meaningful features that improve model performance. Read More