
Mathematical Analysis of Hallucination Dynamics in Large Language Models: Uncertainty Quantification, Advanced Decoding, and Principled Mitigationcs.AI updates on arXiv.org arXiv:2511.15005v1 Announce Type: cross
Abstract: Large Language Models (LLMs) are powerful linguistic engines but remain susceptible to hallucinations: plausible-sounding outputs that are factually incorrect or unsupported. In this work, we present a mathematically grounded framework to understand, measure, and mitigate these hallucinations. Drawing on probabilistic modeling, information theory, trigonometric signal analysis, and Bayesian uncertainty estimation, we analyze how errors compound autoregressively, propose refined uncertainty metrics, including semantic and phase-aware variants, and develop principled mitigation strategies such as contrastive decoding, retrieval-augmented grounding, factual alignment, and abstention. This unified lens connects recent advances in calibration, retrieval, and alignment to support safer and more reliable LLMs.
arXiv:2511.15005v1 Announce Type: cross
Abstract: Large Language Models (LLMs) are powerful linguistic engines but remain susceptible to hallucinations: plausible-sounding outputs that are factually incorrect or unsupported. In this work, we present a mathematically grounded framework to understand, measure, and mitigate these hallucinations. Drawing on probabilistic modeling, information theory, trigonometric signal analysis, and Bayesian uncertainty estimation, we analyze how errors compound autoregressively, propose refined uncertainty metrics, including semantic and phase-aware variants, and develop principled mitigation strategies such as contrastive decoding, retrieval-augmented grounding, factual alignment, and abstention. This unified lens connects recent advances in calibration, retrieval, and alignment to support safer and more reliable LLMs. Read More
STREAM-VAE: Dual-Path Routing for Slow and Fast Dynamics in Vehicle Telemetry Anomaly Detectioncs.AI updates on arXiv.org arXiv:2511.15339v1 Announce Type: cross
Abstract: Automotive telemetry data exhibits slow drifts and fast spikes, often within the same sequence, making reliable anomaly detection challenging. Standard reconstruction-based methods, including sequence variational autoencoders (VAEs), use a single latent process and therefore mix heterogeneous time scales, which can smooth out spikes or inflate variances and weaken anomaly separation.
In this paper, we present STREAM-VAE, a variational autoencoder for anomaly detection in automotive telemetry time-series data. Our model uses a dual-path encoder to separate slow drift and fast spike signal dynamics, and a decoder that represents transient deviations separately from the normal operating pattern. STREAM-VAE is designed for deployment, producing stable anomaly scores across operating modes for both in-vehicle monitors and backend fleet analytics.
Experiments on an automotive telemetry dataset and the public SMD benchmark show that explicitly separating drift and spike dynamics improves robustness compared to strong forecasting, attention, graph, and VAE baselines.
arXiv:2511.15339v1 Announce Type: cross
Abstract: Automotive telemetry data exhibits slow drifts and fast spikes, often within the same sequence, making reliable anomaly detection challenging. Standard reconstruction-based methods, including sequence variational autoencoders (VAEs), use a single latent process and therefore mix heterogeneous time scales, which can smooth out spikes or inflate variances and weaken anomaly separation.
In this paper, we present STREAM-VAE, a variational autoencoder for anomaly detection in automotive telemetry time-series data. Our model uses a dual-path encoder to separate slow drift and fast spike signal dynamics, and a decoder that represents transient deviations separately from the normal operating pattern. STREAM-VAE is designed for deployment, producing stable anomaly scores across operating modes for both in-vehicle monitors and backend fleet analytics.
Experiments on an automotive telemetry dataset and the public SMD benchmark show that explicitly separating drift and spike dynamics improves robustness compared to strong forecasting, attention, graph, and VAE baselines. Read More
Enabling MoE on the Edge via Importance-Driven Expert Schedulingcs.AI updates on arXiv.org arXiv:2508.18983v2 Announce Type: replace
Abstract: The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy.
arXiv:2508.18983v2 Announce Type: replace
Abstract: The Mixture of Experts (MoE) architecture has emerged as a key technique for scaling Large Language Models by activating only a subset of experts per query. Deploying MoE on consumer-grade edge hardware, however, is constrained by limited device memory, making dynamic expert offloading essential. Unlike prior work that treats offloading purely as a scheduling problem, we leverage expert importance to guide decisions, substituting low-importance activated experts with functionally similar ones already cached in GPU memory, thereby preserving accuracy. As a result, this design reduces memory usage and data transfer, while largely eliminating PCIe overhead. In addition, we introduce a scheduling policy that maximizes the reuse ratio of GPU-cached experts, further boosting efficiency. Extensive evaluations show that our approach delivers 48% lower decoding latency with over 60% expert cache hit rate, while maintaining nearly lossless accuracy. Read More
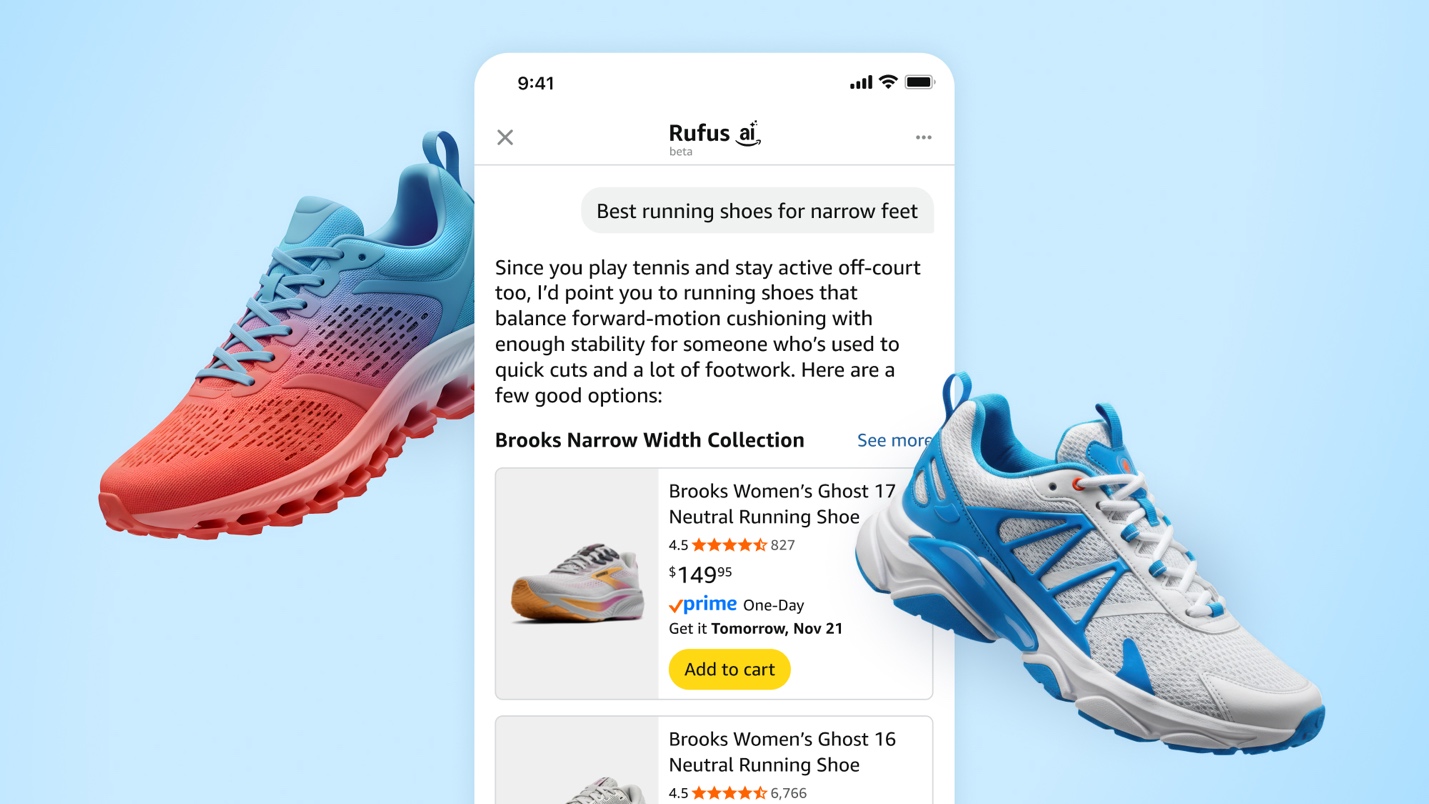
How Rufus scales conversational shopping experiences to millions of Amazon customers with Amazon BedrockArtificial Intelligence Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers. More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping journey are 60% more likely to
Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers. More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping journey are 60% more likely to Read More

How Data Engineering Can Power Manufacturing Industry TransformationKDnuggets Turning scattered information across production-line machines and systems into meaningful insights that help teams drive efficiency and competitiveness without increasing overhead costs.
Turning scattered information across production-line machines and systems into meaningful insights that help teams drive efficiency and competitiveness without increasing overhead costs. Read More

Top SQL Patterns from FAANG Data Science Interviews (with Code)KDnuggets Here are the top 5 SQL patterns tested in FAANG data science interviews.
Here are the top 5 SQL patterns tested in FAANG data science interviews. Read More
How to Use Gemini 3 Pro EfficientlyTowards Data Science Learn the pros and cons of Gemini 3 Pro, from testing with both coding and console usage
The post How to Use Gemini 3 Pro Efficiently appeared first on Towards Data Science.
Learn the pros and cons of Gemini 3 Pro, from testing with both coding and console usage
The post How to Use Gemini 3 Pro Efficiently appeared first on Towards Data Science. Read More

Data Cleaning at the Command Line for Beginner Data ScientistsKDnuggets Data cleaning doesn’t always require Python or Excel. Learn how simple command-line tools can help you clean datasets faster and more efficiently.
Data cleaning doesn’t always require Python or Excel. Learn how simple command-line tools can help you clean datasets faster and more efficiently. Read More
How to choose the best thermal binoculars for long-range detection in 2026AI News Choosing the right thermal binoculars is essential for security professionals and outdoor specialists who need reliable long-range detection. Many users who previously relied on the market’s best night vision binoculars now seek advanced thermal imaging for superior clarity, extended range, and weather-independent performance. In 2026, ATN continues to lead the market with cutting-edge thermal binoculars
The post How to choose the best thermal binoculars for long-range detection in 2026 appeared first on AI News.
Choosing the right thermal binoculars is essential for security professionals and outdoor specialists who need reliable long-range detection. Many users who previously relied on the market’s best night vision binoculars now seek advanced thermal imaging for superior clarity, extended range, and weather-independent performance. In 2026, ATN continues to lead the market with cutting-edge thermal binoculars
The post How to choose the best thermal binoculars for long-range detection in 2026 appeared first on AI News. Read More
How Relevance Models Foreshadowed Transformers for NLPTowards Data Science Tracing the history of LLM attention: standing on the shoulders of giants
The post How Relevance Models Foreshadowed Transformers for NLP appeared first on Towards Data Science.
Tracing the history of LLM attention: standing on the shoulders of giants
The post How Relevance Models Foreshadowed Transformers for NLP appeared first on Towards Data Science. Read More