
Delayed Assignments in Online Non-Centroid Clustering with Stochastic Arrivalscs.AI updates on arXiv.org arXiv:2601.16091v1 Announce Type: cross
Abstract: Clustering is a fundamental problem, aiming to partition a set of elements, like agents or data points, into clusters such that elements in the same cluster are closer to each other than to those in other clusters. In this paper, we present a new framework for studying online non-centroid clustering with delays, where elements, that arrive one at a time as points in a finite metric space, should be assigned to clusters, but assignments need not be immediate. Specifically, upon arrival, each point’s location is revealed, and an online algorithm has to irrevocably assign it to an existing cluster or create a new one containing, at this moment, only this point. However, we allow decisions to be postponed at a delay cost, instead of following the more common assumption of immediate decisions upon arrival. This poses a critical challenge: the goal is to minimize both the total distance costs between points in each cluster and the overall delay costs incurred by postponing assignments. In the classic worst-case arrival model, where points arrive in an arbitrary order, no algorithm has a competitive ratio better than sublogarithmic in the number of points. To overcome this strong impossibility, we focus on a stochastic arrival model, where points’ locations are drawn independently across time from an unknown and fixed probability distribution over the finite metric space. We offer hope for beyond worst-case adversaries: we devise an algorithm that is constant competitive in the sense that, as the number of points grows, the ratio between the expected overall costs of the output clustering and an optimal offline clustering is bounded by a constant.
arXiv:2601.16091v1 Announce Type: cross
Abstract: Clustering is a fundamental problem, aiming to partition a set of elements, like agents or data points, into clusters such that elements in the same cluster are closer to each other than to those in other clusters. In this paper, we present a new framework for studying online non-centroid clustering with delays, where elements, that arrive one at a time as points in a finite metric space, should be assigned to clusters, but assignments need not be immediate. Specifically, upon arrival, each point’s location is revealed, and an online algorithm has to irrevocably assign it to an existing cluster or create a new one containing, at this moment, only this point. However, we allow decisions to be postponed at a delay cost, instead of following the more common assumption of immediate decisions upon arrival. This poses a critical challenge: the goal is to minimize both the total distance costs between points in each cluster and the overall delay costs incurred by postponing assignments. In the classic worst-case arrival model, where points arrive in an arbitrary order, no algorithm has a competitive ratio better than sublogarithmic in the number of points. To overcome this strong impossibility, we focus on a stochastic arrival model, where points’ locations are drawn independently across time from an unknown and fixed probability distribution over the finite metric space. We offer hope for beyond worst-case adversaries: we devise an algorithm that is constant competitive in the sense that, as the number of points grows, the ratio between the expected overall costs of the output clustering and an optimal offline clustering is bounded by a constant. Read More
Do You Feel Comfortable? Detecting Hidden Conversational Escalation in AI Chatbotscs.AI updates on arXiv.org arXiv:2512.06193v4 Announce Type: replace-cross
Abstract: Large Language Models (LLM) are increasingly integrated into everyday interactions, serving not only as information assistants but also as emotional companions. Even in the absence of explicit toxicity, repeated emotional reinforcement or affective drift can gradually escalate distress in a form of textit{implicit harm} that traditional toxicity filters fail to detect. Existing guardrail mechanisms often rely on external classifiers or clinical rubrics that may lag behind the nuanced, real-time dynamics of a developing conversation. To address this gap, we propose GAUGE (Guarding Affective Utterance Generation Escalation), logit-based framework for the real-time detection of hidden conversational escalation. GAUGE measures how an LLM’s output probabilistically shifts the affective state of a dialogue.
arXiv:2512.06193v4 Announce Type: replace-cross
Abstract: Large Language Models (LLM) are increasingly integrated into everyday interactions, serving not only as information assistants but also as emotional companions. Even in the absence of explicit toxicity, repeated emotional reinforcement or affective drift can gradually escalate distress in a form of textit{implicit harm} that traditional toxicity filters fail to detect. Existing guardrail mechanisms often rely on external classifiers or clinical rubrics that may lag behind the nuanced, real-time dynamics of a developing conversation. To address this gap, we propose GAUGE (Guarding Affective Utterance Generation Escalation), logit-based framework for the real-time detection of hidden conversational escalation. GAUGE measures how an LLM’s output probabilistically shifts the affective state of a dialogue. Read More
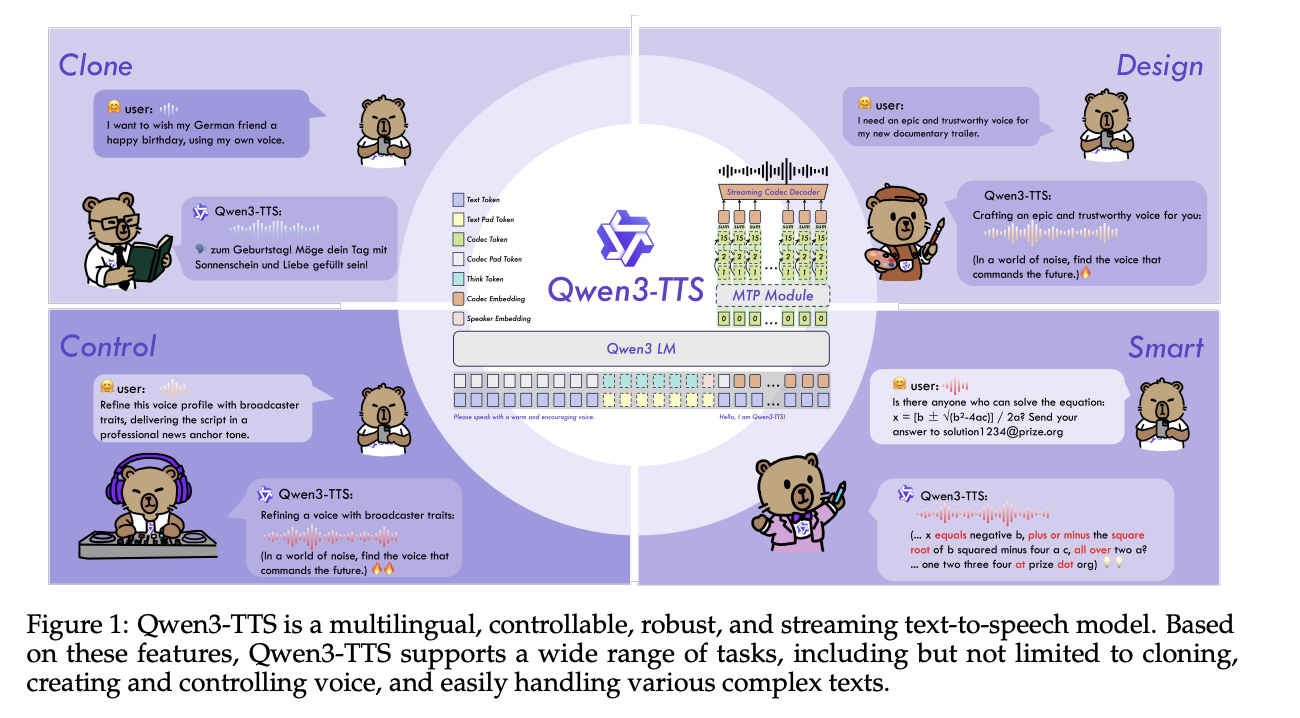
Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice ControlMarkTechPost Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost.
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The open
The post Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control appeared first on MarkTechPost. Read More
Knowing When to Abstain: Medical LLMs Under Clinical Uncertaintycs.AI updates on arXiv.org arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications.
arXiv:2601.12471v2 Announce Type: replace-cross
Abstract: Current evaluation of large language models (LLMs) overwhelmingly prioritizes accuracy; however, in real-world and safety-critical applications, the ability to abstain when uncertain is equally vital for trustworthy deployment. We introduce MedAbstain, a unified benchmark and evaluation protocol for abstention in medical multiple-choice question answering (MCQA) — a discrete-choice setting that generalizes to agentic action selection — integrating conformal prediction, adversarial question perturbations, and explicit abstention options. Our systematic evaluation of both open- and closed-source LLMs reveals that even state-of-the-art, high-accuracy models often fail to abstain with uncertain. Notably, providing explicit abstention options consistently increases model uncertainty and safer abstention, far more than input perturbations, while scaling model size or advanced prompting brings little improvement. These findings highlight the central role of abstention mechanisms for trustworthy LLM deployment and offer practical guidance for improving safety in high-stakes applications. Read More
Scaling PostgreSQL to power 800 million ChatGPT usersOpenAI News An inside look at how OpenAI scaled PostgreSQL to millions of queries per second using replicas, caching, rate limiting, and workload isolation.
An inside look at how OpenAI scaled PostgreSQL to millions of queries per second using replicas, caching, rate limiting, and workload isolation. Read More
Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural MetricsTowards Data Science How to evaluate goal-oriented content designed to build engagement and deliver business results, and why structure matters.
The post Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural Metrics appeared first on Towards Data Science.
How to evaluate goal-oriented content designed to build engagement and deliver business results, and why structure matters.
The post Evaluating Multi-Step LLM-Generated Content: Why Customer Journeys Require Structural Metrics appeared first on Towards Data Science. Read More

Open Notebook: A True Open Source Private NotebookLM Alternative?KDnuggets Open Notebook is an open-source, AI-powered platform designed to help users take, organize, and interact with notes while keeping full control over their data.
Open Notebook is an open-source, AI-powered platform designed to help users take, organize, and interact with notes while keeping full control over their data. Read More
Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026Towards Data Science How I use analytics, automation, and AI to build better SaaS
The post Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026 appeared first on Towards Data Science.
How I use analytics, automation, and AI to build better SaaS
The post Why SaaS Product Management Is the Best Domain for Data-Driven Professionals in 2026 appeared first on Towards Data Science. Read More
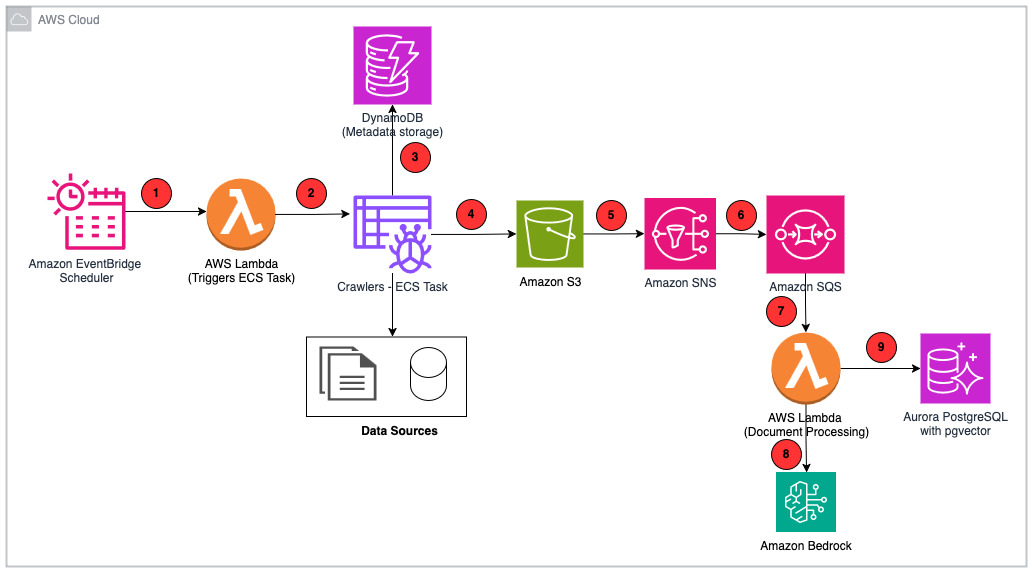
How PDI built an enterprise-grade RAG system for AI applications with AWSArtificial Intelligence PDI Technologies is a global leader in the convenience retail and petroleum wholesale industries. In this post, we walk through the PDI Intelligence Query (PDIQ) process flow and architecture, focusing on the implementation details and the business outcomes it has helped PDI achieve.
PDI Technologies is a global leader in the convenience retail and petroleum wholesale industries. In this post, we walk through the PDI Intelligence Query (PDIQ) process flow and architecture, focusing on the implementation details and the business outcomes it has helped PDI achieve. Read More
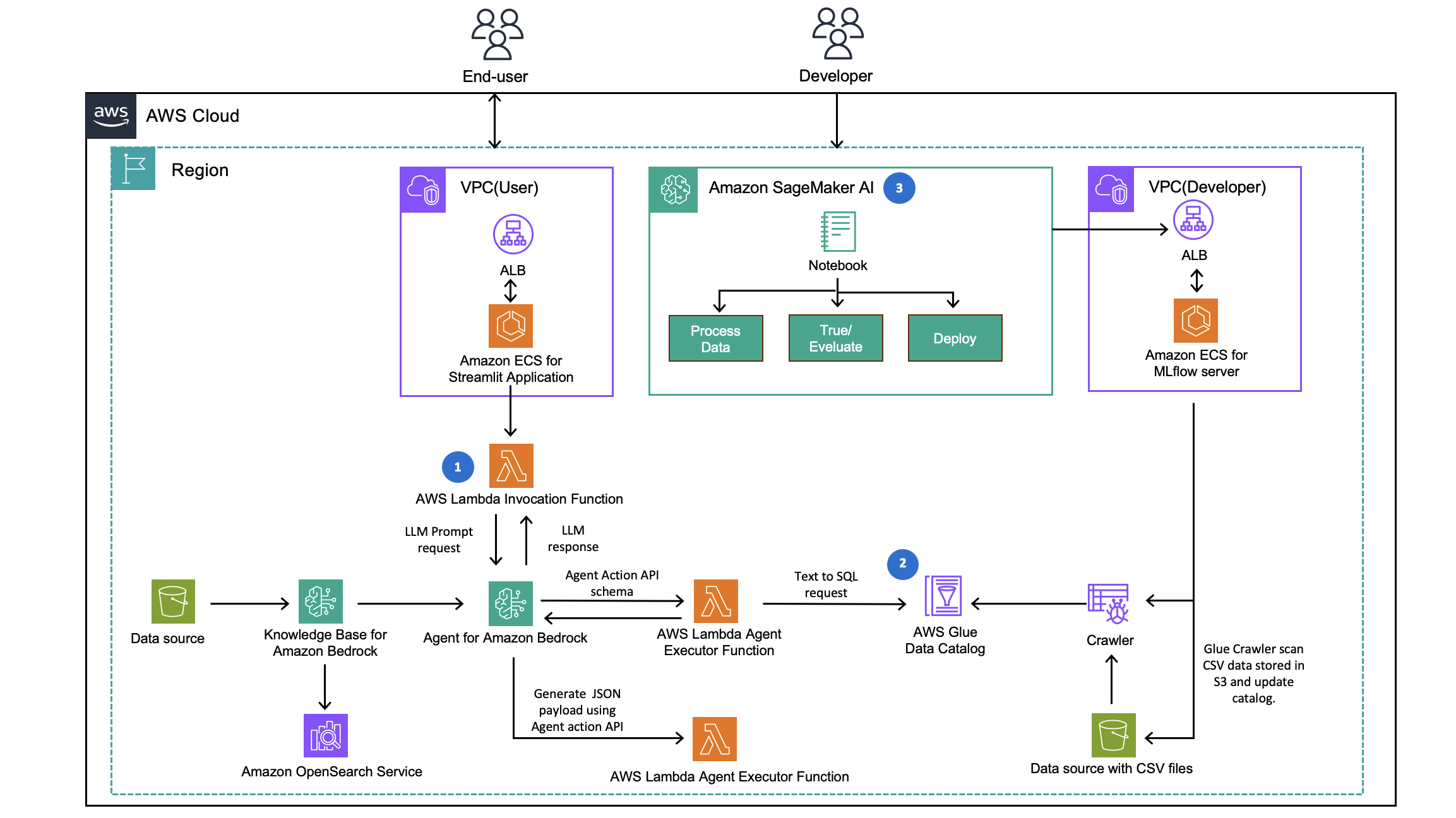
How CLICKFORCE accelerates data-driven advertising with Amazon Bedrock AgentsArtificial Intelligence In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process.
In this post, we demonstrate how CLICKFORCE used AWS services to build Lumos and transform advertising industry analysis from weeks-long manual work into an automated, one-hour process. Read More