
Introducing bidirectional streaming for real-time inference on Amazon SageMaker AIArtificial Intelligence We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference.
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional exchange into a continuous conversation. This post shows you how to build and deploy a container with bidirectional streaming capability to a SageMaker AI endpoint. We also demonstrate how you can bring your own container or use our partner Deepgram’s pre-built models and containers on SageMaker AI to enable bi-directional streaming feature for real-time inference. Read More

How to Implement Three Use Cases for the New Calendar-Based Time IntelligenceTowards Data Science Starting with the September 2025 Release of Power BI, Microsoft introduced the new Calendar-based Time Intelligence feature. Let’s see what can be done by implementing three use cases. The future looks very interesting with this new feature.
The post How to Implement Three Use Cases for the New Calendar-Based Time Intelligence appeared first on Towards Data Science.
Starting with the September 2025 Release of Power BI, Microsoft introduced the new Calendar-based Time Intelligence feature. Let’s see what can be done by implementing three use cases. The future looks very interesting with this new feature.
The post How to Implement Three Use Cases for the New Calendar-Based Time Intelligence appeared first on Towards Data Science. Read More
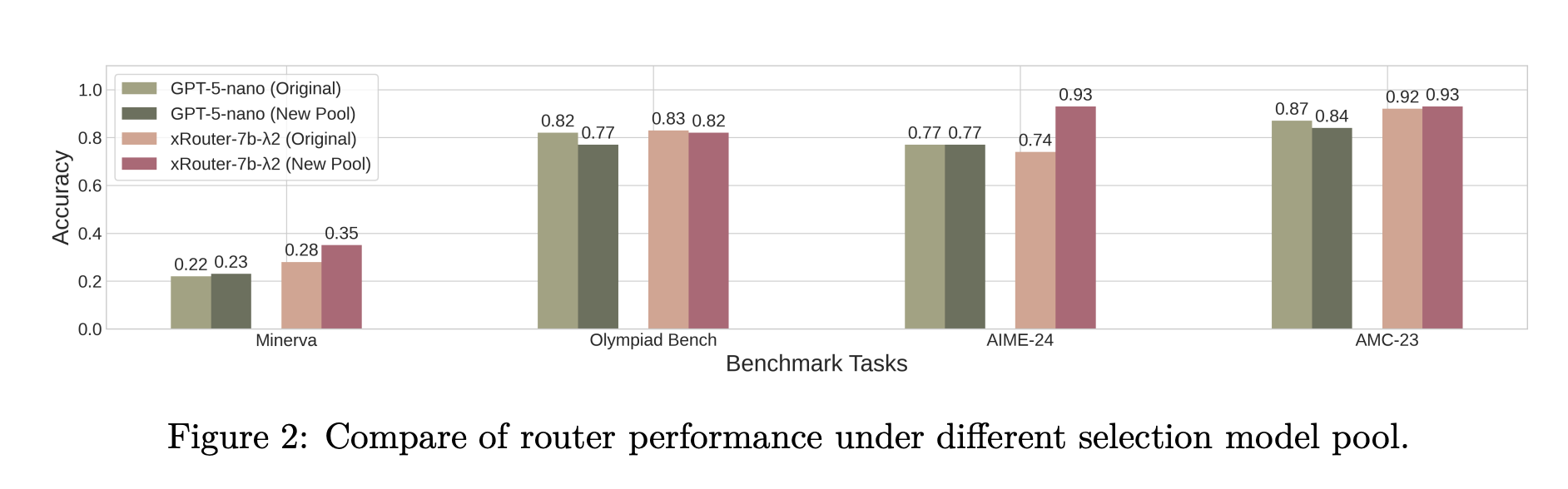
Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM OrchestrationMarkTechPost When your application can call many different LLMs with very different prices and capabilities, who should decide which one answers each request? Salesforce AI research team introduces ‘xRouter’, a tool-calling–based routing system that targets this gap with a reinforcement learning based router and learns when to answer locally and when to call external models, while
The post Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM Orchestration appeared first on MarkTechPost.
When your application can call many different LLMs with very different prices and capabilities, who should decide which one answers each request? Salesforce AI research team introduces ‘xRouter’, a tool-calling–based routing system that targets this gap with a reinforcement learning based router and learns when to answer locally and when to call external models, while
The post Salesforce AI Research Introduces xRouter: A Reinforcement Learning Router for Cost Aware LLM Orchestration appeared first on MarkTechPost. Read More

Train custom computer vision defect detection model using Amazon SageMakerArtificial Intelligence In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases. Read More

MIT scientists debut a generative AI model that could create molecules addressing hard-to-treat diseasesMIT News – Machine learning BoltzGen generates protein binders for any biological target from scratch, expanding AI’s reach from understanding biology toward engineering it.
BoltzGen generates protein binders for any biological target from scratch, expanding AI’s reach from understanding biology toward engineering it. Read More

Practical implementation considerations to close the AI value gapArtificial Intelligence The AWS Customer Success Center of Excellence (CS COE) helps customers get tangible value from their AWS investments. We’ve seen a pattern: customers who build AI strategies that address people, process, and technology together succeed more often. In this post, we share practical considerations that can help close the AI value gap.
The AWS Customer Success Center of Excellence (CS COE) helps customers get tangible value from their AWS investments. We’ve seen a pattern: customers who build AI strategies that address people, process, and technology together succeed more often. In this post, we share practical considerations that can help close the AI value gap. Read More
Warner Bros. Discovery achieves 60% cost savings and faster ML inference with AWS GravitonArtificial Intelligence Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models.
Warner Bros. Discovery (WBD) is a leading global media and entertainment company that creates and distributes the world’s most differentiated and complete portfolio of content and brands across television, film and streaming. In this post, we describe the scale of our offerings, artificial intelligence (AI)/machine learning (ML) inference infrastructure requirements for our real time recommender systems, and how we used AWS Graviton-based Amazon SageMaker AI instances for our ML inference workloads and achieved 60% cost savings and 7% to 60% latency improvements across different models. Read More
Physical AI in practice: Technical foundations that fuel human-machine interactionsArtificial Intelligence In this post, we explore the complete development lifecycle of physical AI—from data collection and model training to edge deployment—and examine how these intelligent systems learn to understand, reason, and interact with the physical world through continuous feedback loops. We illustrate this workflow through Diligent Robotics’ Moxi, a mobile manipulation robot that has completed over 1.2 million deliveries in hospitals, saving nearly 600,000 hours for clinical staff while transforming healthcare logistics and returning valuable time to patient care.
In this post, we explore the complete development lifecycle of physical AI—from data collection and model training to edge deployment—and examine how these intelligent systems learn to understand, reason, and interact with the physical world through continuous feedback loops. We illustrate this workflow through Diligent Robotics’ Moxi, a mobile manipulation robot that has completed over 1.2 million deliveries in hospitals, saving nearly 600,000 hours for clinical staff while transforming healthcare logistics and returning valuable time to patient care. Read More

HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasksArtificial Intelligence In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks. Read More

Deploy an AI Analyst in Minutes: Connect Any LLM to Any Data Source with Bag of WordsKDnuggets Deploy an AI analyst fast by connecting any LLM to your SQL database with Bag of Words, allowing immediate, trustworthy data insights via natural language queries.
Deploy an AI analyst fast by connecting any LLM to your SQL database with Bag of Words, allowing immediate, trustworthy data insights via natural language queries. Read More