
Specification-Driven Generation and Evaluation of Discrete-Event World Models via the DEVS Formalismcs.AI updates on arXiv.org arXiv:2603.03784v1 Announce Type: new
Abstract: World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution.
arXiv:2603.03784v1 Announce Type: new
Abstract: World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution. Read More
CareMedEval dataset: Evaluating Critical Appraisal and Reasoning in the Biomedical Fieldcs.AI updates on arXiv.org arXiv:2511.03441v3 Announce Type: replace-cross
Abstract: Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal.
arXiv:2511.03441v3 Announce Type: replace-cross
Abstract: Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal. Read More
Prompt Sensitivity and Answer Consistency of Small Open-Source Large Language Models on Clinical Question Answering: Implications for Low-Resource Healthcare Deploymentcs.AI updates on arXiv.org arXiv:2603.00917v2 Announce Type: replace-cross
Abstract: Small open-source language models are gaining attention for healthcare applications in low-resource settings where cloud infrastructure and GPU hardware may be unavailable. However, their reliability under different prompt phrasings remains poorly understood. We evaluate five open-source models (Gemma 2 2B, Phi-3 Mini 3.8B, Llama 3.2 3B, Mistral 7B, and Meditron-7B, a domain-pretrained model without instruction tuning) across three clinical question answering datasets (MedQA, MedMCQA, and PubMedQA) using five prompt styles: original, formal, simplified, roleplay, and direct. Model behavior is evaluated using consistency scores, accuracy, and instruction-following failure rates. All experiments were conducted locally on consumer CPU hardware without fine-tuning.
Consistency and accuracy were largely independent across models. Gemma 2 achieved the highest consistency (0.845-0.888) but the lowest accuracy (33.0-43.5%), while Llama 3.2 showed moderate consistency (0.774-0.807) alongside the highest accuracy (49.0-65.0%). Roleplay prompts consistently reduced accuracy across all models, with Phi-3 Mini dropping 21.5 percentage points on MedQA. Meditron-7B exhibited near-complete instruction-following failure on PubMedQA (99.0% UNKNOWN rate), indicating that domain pretraining alone is insufficient for structured clinical QA.
These findings show that high consistency does not imply correctness: models can be reliably wrong, a dangerous failure mode in clinical AI. Llama 3.2 demonstrated the strongest balance of accuracy and reliability for low-resource deployment. Safe clinical AI requires joint evaluation of consistency, accuracy, and instruction adherence.
arXiv:2603.00917v2 Announce Type: replace-cross
Abstract: Small open-source language models are gaining attention for healthcare applications in low-resource settings where cloud infrastructure and GPU hardware may be unavailable. However, their reliability under different prompt phrasings remains poorly understood. We evaluate five open-source models (Gemma 2 2B, Phi-3 Mini 3.8B, Llama 3.2 3B, Mistral 7B, and Meditron-7B, a domain-pretrained model without instruction tuning) across three clinical question answering datasets (MedQA, MedMCQA, and PubMedQA) using five prompt styles: original, formal, simplified, roleplay, and direct. Model behavior is evaluated using consistency scores, accuracy, and instruction-following failure rates. All experiments were conducted locally on consumer CPU hardware without fine-tuning.
Consistency and accuracy were largely independent across models. Gemma 2 achieved the highest consistency (0.845-0.888) but the lowest accuracy (33.0-43.5%), while Llama 3.2 showed moderate consistency (0.774-0.807) alongside the highest accuracy (49.0-65.0%). Roleplay prompts consistently reduced accuracy across all models, with Phi-3 Mini dropping 21.5 percentage points on MedQA. Meditron-7B exhibited near-complete instruction-following failure on PubMedQA (99.0% UNKNOWN rate), indicating that domain pretraining alone is insufficient for structured clinical QA.
These findings show that high consistency does not imply correctness: models can be reliably wrong, a dangerous failure mode in clinical AI. Llama 3.2 demonstrated the strongest balance of accuracy and reliability for low-resource deployment. Safe clinical AI requires joint evaluation of consistency, accuracy, and instruction adherence. Read More
ZeSTA: Zero-Shot TTS Augmentation with Domain-Conditioned Training for Data-Efficient Personalized Speech Synthesiscs.AI updates on arXiv.org arXiv:2603.04219v1 Announce Type: cross
Abstract: We investigate the use of zero-shot text-to-speech (ZS-TTS) as a data augmentation source for low-resource personalized speech synthesis. While synthetic augmentation can provide linguistically rich and phonetically diverse speech, naively mixing large amounts of synthetic speech with limited real recordings often leads to speaker similarity degradation during fine-tuning. To address this issue, we propose ZeSTA, a simple domain-conditioned training framework that distinguishes real and synthetic speech via a lightweight domain embedding, combined with real-data oversampling to stabilize adaptation under extremely limited target data, without modifying the base architecture. Experiments on LibriTTS and an in-house dataset with two ZS-TTS sources demonstrate that our approach improves speaker similarity over naive synthetic augmentation while preserving intelligibility and perceptual quality.
arXiv:2603.04219v1 Announce Type: cross
Abstract: We investigate the use of zero-shot text-to-speech (ZS-TTS) as a data augmentation source for low-resource personalized speech synthesis. While synthetic augmentation can provide linguistically rich and phonetically diverse speech, naively mixing large amounts of synthetic speech with limited real recordings often leads to speaker similarity degradation during fine-tuning. To address this issue, we propose ZeSTA, a simple domain-conditioned training framework that distinguishes real and synthetic speech via a lightweight domain embedding, combined with real-data oversampling to stabilize adaptation under extremely limited target data, without modifying the base architecture. Experiments on LibriTTS and an in-house dataset with two ZS-TTS sources demonstrate that our approach improves speaker similarity over naive synthetic augmentation while preserving intelligibility and perceptual quality. Read More

Beyond the pilot: Dyna.Ai raises eight-figure Series A to put agentic AI in financial services to workAI News The financial services industry has a pilot problem. Institutions pour resources into AI proofs-of-concept, generate impressive dashboards, and then quietly watch momentum stall before anything reaches production. Singapore-headquartered Dyna.Ai was built precisely to break that pattern–and investors are now backing that thesis with serious capital. The AI-as-a-Service company has closed an eight-figure Series A round
The post Beyond the pilot: Dyna.Ai raises eight-figure Series A to put agentic AI in financial services to work appeared first on AI News.
The financial services industry has a pilot problem. Institutions pour resources into AI proofs-of-concept, generate impressive dashboards, and then quietly watch momentum stall before anything reaches production. Singapore-headquartered Dyna.Ai was built precisely to break that pattern–and investors are now backing that thesis with serious capital. The AI-as-a-Service company has closed an eight-figure Series A round
The post Beyond the pilot: Dyna.Ai raises eight-figure Series A to put agentic AI in financial services to work appeared first on AI News. Read More
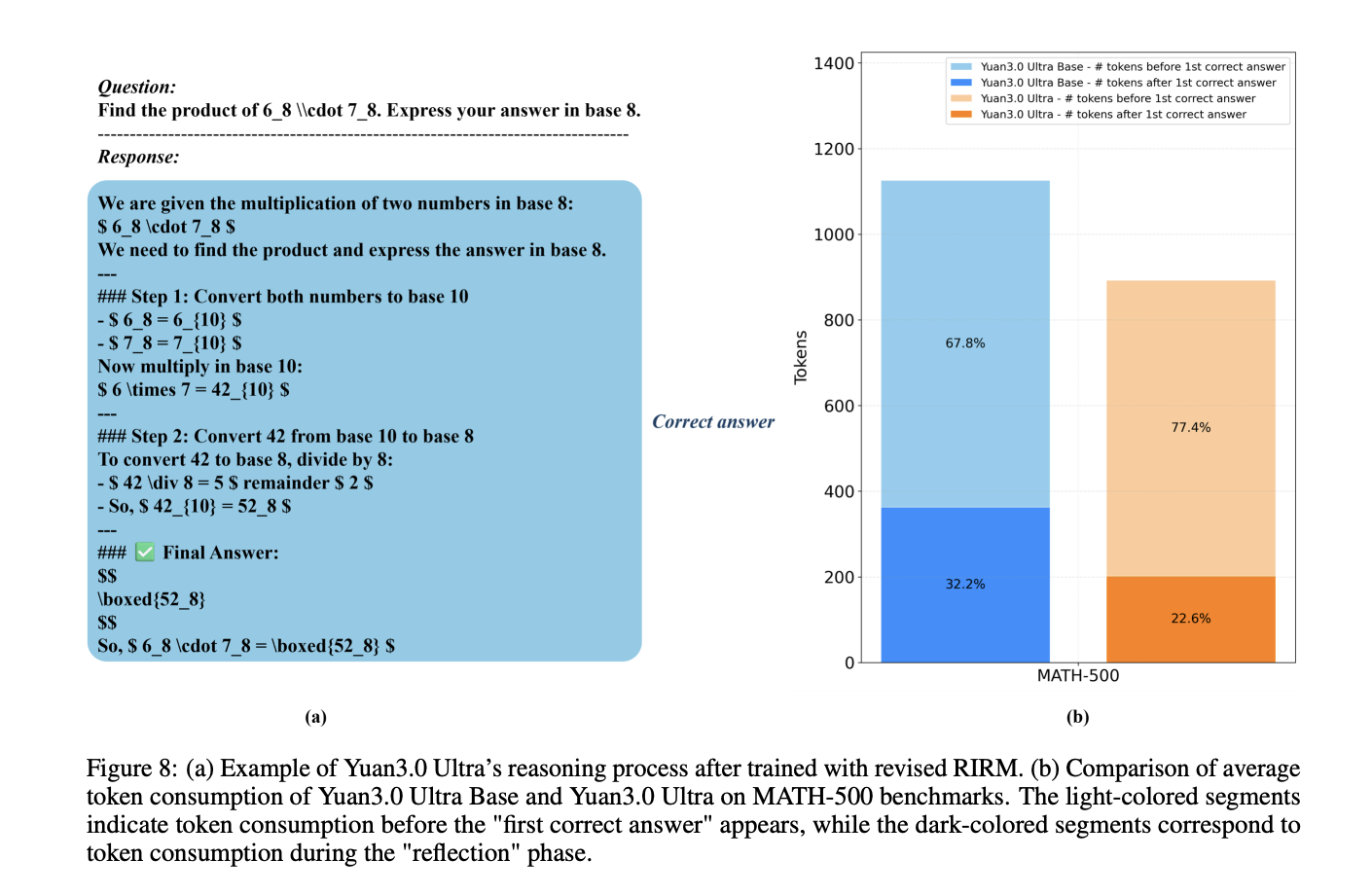
YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled EfficiencyMarkTechPost How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its total parameter count by 33.3% and boosting pre-training efficiency by 49%? Yuan Lab AI releases Yuan3.0 Ultra, an open-source Mixture-of-Experts (MoE) large language model featuring 1T total parameters and 68.8B activated parameters. The model architecture is designed to optimize performance
The post YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency appeared first on MarkTechPost.
How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its total parameter count by 33.3% and boosting pre-training efficiency by 49%? Yuan Lab AI releases Yuan3.0 Ultra, an open-source Mixture-of-Experts (MoE) large language model featuring 1T total parameters and 68.8B activated parameters. The model architecture is designed to optimize performance
The post YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency appeared first on MarkTechPost. Read More
Memory, Benchmark & Robots: A Benchmark for Solving Complex Tasks with Reinforcement Learningcs.AI updates on arXiv.org arXiv:2502.10550v3 Announce Type: replace-cross
Abstract: Memory is crucial for enabling agents to tackle complex tasks with temporal and spatial dependencies. While many reinforcement learning (RL) algorithms incorporate memory, the field lacks a universal benchmark to assess an agent’s memory capabilities across diverse scenarios. This gap is particularly evident in tabletop robotic manipulation, where memory is essential for solving tasks with partial observability and ensuring robust performance, yet no standardized benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills Assessment Suite for Agents), a comprehensive benchmark for memory RL, with three key contributions: (1) we propose a comprehensive classification framework for memory-intensive RL tasks, (2) we collect MIKASA-Base — a unified benchmark that enables systematic evaluation of memory-enhanced agents across diverse scenarios, and (3) we develop MIKASA-Robo (pip install mikasa-robo-suite) — a novel benchmark of 32 carefully designed memory-intensive tasks that assess memory capabilities in tabletop robotic manipulation. Our work introduces a unified framework to advance memory RL research, enabling more robust systems for real-world use. MIKASA is available at https://tinyurl.com/membenchrobots.
arXiv:2502.10550v3 Announce Type: replace-cross
Abstract: Memory is crucial for enabling agents to tackle complex tasks with temporal and spatial dependencies. While many reinforcement learning (RL) algorithms incorporate memory, the field lacks a universal benchmark to assess an agent’s memory capabilities across diverse scenarios. This gap is particularly evident in tabletop robotic manipulation, where memory is essential for solving tasks with partial observability and ensuring robust performance, yet no standardized benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills Assessment Suite for Agents), a comprehensive benchmark for memory RL, with three key contributions: (1) we propose a comprehensive classification framework for memory-intensive RL tasks, (2) we collect MIKASA-Base — a unified benchmark that enables systematic evaluation of memory-enhanced agents across diverse scenarios, and (3) we develop MIKASA-Robo (pip install mikasa-robo-suite) — a novel benchmark of 32 carefully designed memory-intensive tasks that assess memory capabilities in tabletop robotic manipulation. Our work introduces a unified framework to advance memory RL research, enabling more robust systems for real-world use. MIKASA is available at https://tinyurl.com/membenchrobots. Read More
How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory ConsolidationMarkTechPost In this tutorial, we build an EverMem-style persistent agent OS. We combine short-term conversational context (STM) with long-term vector memory using FAISS so the agent can recall relevant past information before generating each response. Alongside semantic memory, we also store structured records in SQLite to persist metadata like timestamps, importance scores, and memory signals (preference,
The post How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory Consolidation appeared first on MarkTechPost.
In this tutorial, we build an EverMem-style persistent agent OS. We combine short-term conversational context (STM) with long-term vector memory using FAISS so the agent can recall relevant past information before generating each response. Alongside semantic memory, we also store structured records in SQLite to persist metadata like timestamps, importance scores, and memory signals (preference,
The post How to Build an EverMem-Style Persistent AI Agent OS with Hierarchical Memory, FAISS Vector Retrieval, SQLite Storage, and Automated Memory Consolidation appeared first on MarkTechPost. Read More
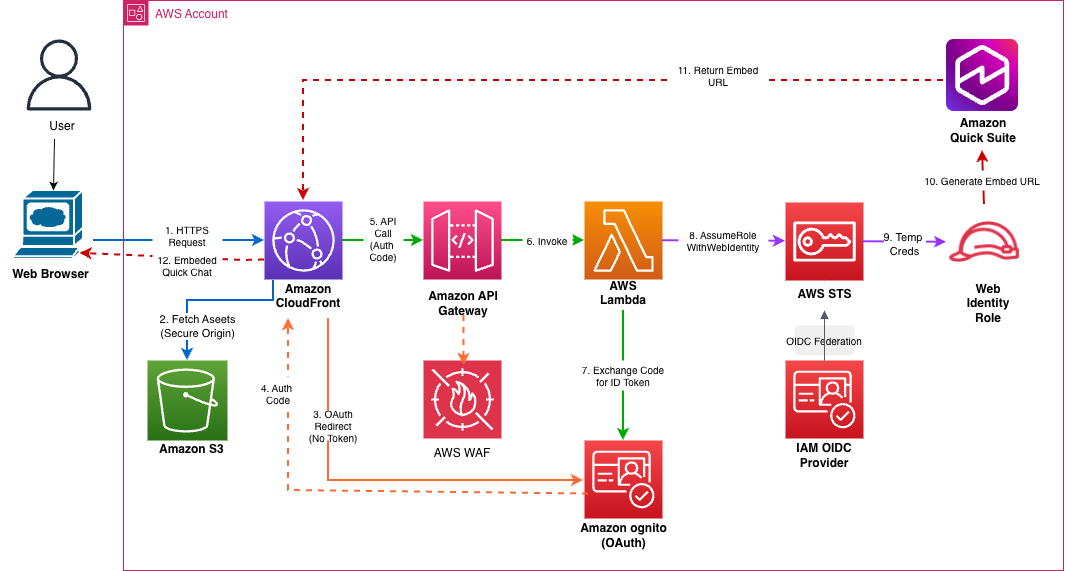
Embed Amazon Quick Suite chat agents in enterprise applicationsArtificial Intelligence Organizations find it challenging to implement a secure embedded chat in their applications and can require weeks of development to build authentication, token validation, domain security, and global distribution infrastructure. In this post, we show you how to solve this with a one-click deployment solution to embed the chat agents using the Quick Suite Embedding SDK in enterprise portals.
Organizations find it challenging to implement a secure embedded chat in their applications and can require weeks of development to build authentication, token validation, domain security, and global distribution infrastructure. In this post, we show you how to solve this with a one-click deployment solution to embed the chat agents using the Quick Suite Embedding SDK in enterprise portals. Read More
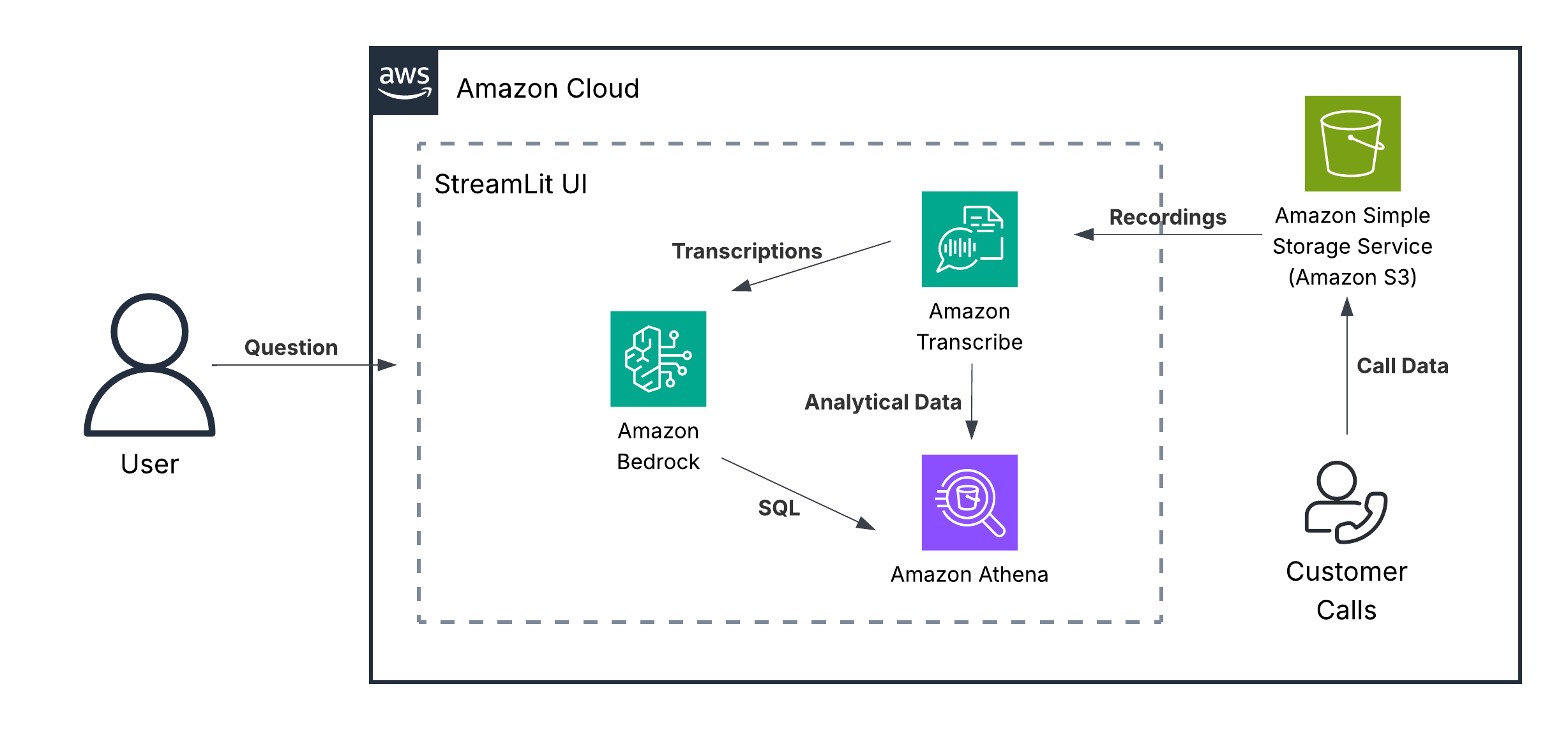
Unlock powerful call center analytics with Amazon Nova foundation modelsArtificial Intelligence In this post, we discuss how Amazon Nova demonstrates capabilities in conversational analytics, call classification, and other use cases often relevant to contact center solutions. We examine these capabilities for both single-call and multi-call analytics use cases.
In this post, we discuss how Amazon Nova demonstrates capabilities in conversational analytics, call classification, and other use cases often relevant to contact center solutions. We examine these capabilities for both single-call and multi-call analytics use cases. Read More