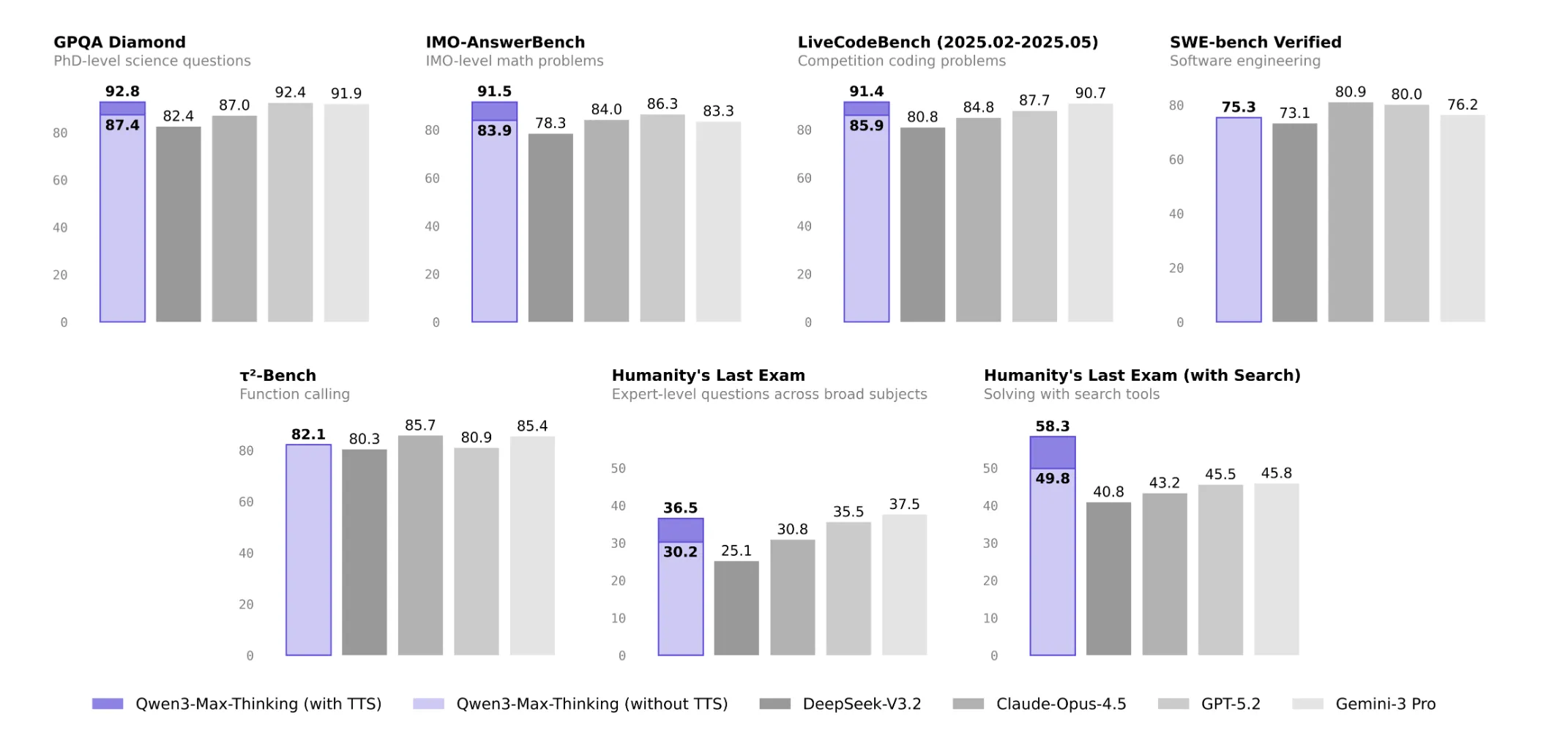
Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic WorkloadsMarkTechPost Qwen3-Max-Thinking is Alibaba’s new flagship reasoning model. It does not only scale parameters, it also changes how inference is done, with explicit control over thinking depth and built in tools for search, memory, and code execution. Model scale, data, and deployment Qwen3-Max-Thinking is a trillion-parameter MoE flagship LLM pretrained on 36T tokens and built on
The post Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic Workloads appeared first on MarkTechPost.
Qwen3-Max-Thinking is Alibaba’s new flagship reasoning model. It does not only scale parameters, it also changes how inference is done, with explicit control over thinking depth and built in tools for search, memory, and code execution. Model scale, data, and deployment Qwen3-Max-Thinking is a trillion-parameter MoE flagship LLM pretrained on 36T tokens and built on
The post Alibaba Introduces Qwen3-Max-Thinking, a Test Time Scaled Reasoning Model with Native Tool Use Powering Agentic Workloads appeared first on MarkTechPost. Read More

How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial OperationsMarkTechPost In this tutorial, we implement a dual-agent governance system that applies Constitutional AI principles to financial operations. We demonstrate how we separate execution and oversight by pairing a Worker Agent that performs financial actions with an Auditor Agent that enforces policy, safety, and compliance. By encoding governance rules directly into a formal constitution and combining
The post How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial Operations appeared first on MarkTechPost.
In this tutorial, we implement a dual-agent governance system that applies Constitutional AI principles to financial operations. We demonstrate how we separate execution and oversight by pairing a Worker Agent that performs financial actions with an Auditor Agent that enforces policy, safety, and compliance. By encoding governance rules directly into a formal constitution and combining
The post How to Design Self-Reflective Dual-Agent Governance Systems with Constitutional AI for Secure and Compliant Financial Operations appeared first on MarkTechPost. Read More

White House compares industrial revolution with AI eraAI News A White House paper titled “Artificial Intelligence and the Great Divergence” sets out parallels between the effects of the industrial revolution in the 18th and 19th centuries and the current times, with artificial intelligence positioned as guiding the way the world’s economies will be shaped. Artificial intelligence now sits at the centre of US economic
The post White House compares industrial revolution with AI era appeared first on AI News.
A White House paper titled “Artificial Intelligence and the Great Divergence” sets out parallels between the effects of the industrial revolution in the 18th and 19th centuries and the current times, with artificial intelligence positioned as guiding the way the world’s economies will be shaped. Artificial intelligence now sits at the centre of US economic
The post White House compares industrial revolution with AI era appeared first on AI News. Read More

Top 7 Coding Plans for Vibe CodingKDnuggets API bills are killing vibe coding. These seven coding plans let you ship faster without watching token costs.
API bills are killing vibe coding. These seven coding plans let you ship faster without watching token costs. Read More
Masumi Network: How AI-blockchain fusion adds trust to burgeoning agent economyAI News 2026 will see forward-thinking organisations building out their squads of AI agents across roles and functions. But amid the rush, there is another aspect to consider. One of IDC’s enterprise technology predictions for the coming five years, published in October, was fascinating. “By 2030, up to 20% of [global 1000] organisations will have faced lawsuits,
The post Masumi Network: How AI-blockchain fusion adds trust to burgeoning agent economy appeared first on AI News.
2026 will see forward-thinking organisations building out their squads of AI agents across roles and functions. But amid the rush, there is another aspect to consider. One of IDC’s enterprise technology predictions for the coming five years, published in October, was fascinating. “By 2030, up to 20% of [global 1000] organisations will have faced lawsuits,
The post Masumi Network: How AI-blockchain fusion adds trust to burgeoning agent economy appeared first on AI News. Read More

Franny Hsiao, Salesforce: Scaling enterprise AIAI News Scaling enterprise AI requires overcoming architectural oversights that often stall pilots before production, a challenge that goes far beyond model selection. While generative AI prototypes are easy to spin up, turning them into reliable business assets involves solving the difficult problems of data engineering and governance. Ahead of AI & Big Data Global 2026 in
The post Franny Hsiao, Salesforce: Scaling enterprise AI appeared first on AI News.
Scaling enterprise AI requires overcoming architectural oversights that often stall pilots before production, a challenge that goes far beyond model selection. While generative AI prototypes are easy to spin up, turning them into reliable business assets involves solving the difficult problems of data engineering and governance. Ahead of AI & Big Data Global 2026 in
The post Franny Hsiao, Salesforce: Scaling enterprise AI appeared first on AI News. Read More
Machine Learning in Production? What This Really MeansTowards Data Science From notebooks to real-world systems
The post Machine Learning in Production? What This Really Means appeared first on Towards Data Science.
From notebooks to real-world systems
The post Machine Learning in Production? What This Really Means appeared first on Towards Data Science. Read More
Deloitte sounds alarm as AI agent deployment outruns safety frameworksAI News A new report from Deloitte has warned that businesses are deploying AI agents faster than their safety protocols and safeguards can keep up. Therefore, serious concerns around security, data privacy, and accountability are spreading. According to the survey, agentic systems are moving from pilot to production so quickly that traditional risk controls, which were designed
The post Deloitte sounds alarm as AI agent deployment outruns safety frameworks appeared first on AI News.
A new report from Deloitte has warned that businesses are deploying AI agents faster than their safety protocols and safeguards can keep up. Therefore, serious concerns around security, data privacy, and accountability are spreading. According to the survey, agentic systems are moving from pilot to production so quickly that traditional risk controls, which were designed
The post Deloitte sounds alarm as AI agent deployment outruns safety frameworks appeared first on AI News. Read More
Federated Learning, Part 2: Implementation with the Flower Framework 🌼Towards Data Science Implementing cross-silo federated learning step by step
The post Federated Learning, Part 2: Implementation with the Flower Framework 🌼 appeared first on Towards Data Science.
Implementing cross-silo federated learning step by step
The post Federated Learning, Part 2: Implementation with the Flower Framework 🌼 appeared first on Towards Data Science. Read More
RIFT: Reordered Instruction Following Testbed To Evaluate Instruction Following in Singular Multistep Prompt Structurescs.AI updates on arXiv.org arXiv:2601.18924v1 Announce Type: new
Abstract: Large Language Models (LLMs) are increasingly relied upon for complex workflows, yet their ability to maintain flow of instructions remains underexplored. Existing benchmarks conflate task complexity with structural ordering, making it difficult to isolate the impact of prompt topology on performance. We introduce RIFT, Reordered Instruction Following Testbed, to assess instruction following by disentangling structure from content. Using rephrased Jeopardy! question-answer pairs, we test LLMs across two prompt structures: linear prompts, which progress sequentially, and jumping prompts, which preserve identical content but require non-sequential traversal. Across 10,000 evaluations spanning six state-of-the-art open-source LLMs, accuracy dropped by up to 72% under jumping conditions (compared to baseline), revealing a strong dependence on positional continuity. Error analysis shows that approximately 50% of failures stem from instruction-order violations and semantic drift, indicating that current architectures internalize instruction following as a sequential pattern rather than a reasoning skill. These results reveal structural sensitivity as a fundamental limitation in current architectures, with direct implications for applications requiring non-sequential control flow such as workflow automation and multi-agent systems.
arXiv:2601.18924v1 Announce Type: new
Abstract: Large Language Models (LLMs) are increasingly relied upon for complex workflows, yet their ability to maintain flow of instructions remains underexplored. Existing benchmarks conflate task complexity with structural ordering, making it difficult to isolate the impact of prompt topology on performance. We introduce RIFT, Reordered Instruction Following Testbed, to assess instruction following by disentangling structure from content. Using rephrased Jeopardy! question-answer pairs, we test LLMs across two prompt structures: linear prompts, which progress sequentially, and jumping prompts, which preserve identical content but require non-sequential traversal. Across 10,000 evaluations spanning six state-of-the-art open-source LLMs, accuracy dropped by up to 72% under jumping conditions (compared to baseline), revealing a strong dependence on positional continuity. Error analysis shows that approximately 50% of failures stem from instruction-order violations and semantic drift, indicating that current architectures internalize instruction following as a sequential pattern rather than a reasoning skill. These results reveal structural sensitivity as a fundamental limitation in current architectures, with direct implications for applications requiring non-sequential control flow such as workflow automation and multi-agent systems. Read More