
Microsoft Unveils Maia 200, An FP4 and FP8 Optimized AI Inference Accelerator for Azure DatacentersMarkTechPost Maia 200 is Microsoft’s new in house AI accelerator designed for inference in Azure datacenters. It targets the cost of token generation for large language models and other reasoning workloads by combining narrow precision compute, a dense on chip memory hierarchy and an Ethernet based scale up fabric. Why Microsoft built a dedicated inference chip?
The post Microsoft Unveils Maia 200, An FP4 and FP8 Optimized AI Inference Accelerator for Azure Datacenters appeared first on MarkTechPost.
Maia 200 is Microsoft’s new in house AI accelerator designed for inference in Azure datacenters. It targets the cost of token generation for large language models and other reasoning workloads by combining narrow precision compute, a dense on chip memory hierarchy and an Ethernet based scale up fabric. Why Microsoft built a dedicated inference chip?
The post Microsoft Unveils Maia 200, An FP4 and FP8 Optimized AI Inference Accelerator for Azure Datacenters appeared first on MarkTechPost. Read More
China’s hyperscalers bet billions on agentic AI as commerce becomes the new battlegroundAI News The artificial intelligence industry’s pivot toward agentic AI – systems capable of autonomously executing multi-step tasks – has dominated technology discussions in recent months. But while Western firms focus on foundational models and cross-platform interoperability, China’s technology giants are racing to dominate through commerce integration, a divergence that could reshape how enterprises deploy autonomous systems
The post China’s hyperscalers bet billions on agentic AI as commerce becomes the new battleground appeared first on AI News.
The artificial intelligence industry’s pivot toward agentic AI – systems capable of autonomously executing multi-step tasks – has dominated technology discussions in recent months. But while Western firms focus on foundational models and cross-platform interoperability, China’s technology giants are racing to dominate through commerce integration, a divergence that could reshape how enterprises deploy autonomous systems
The post China’s hyperscalers bet billions on agentic AI as commerce becomes the new battleground appeared first on AI News. Read More
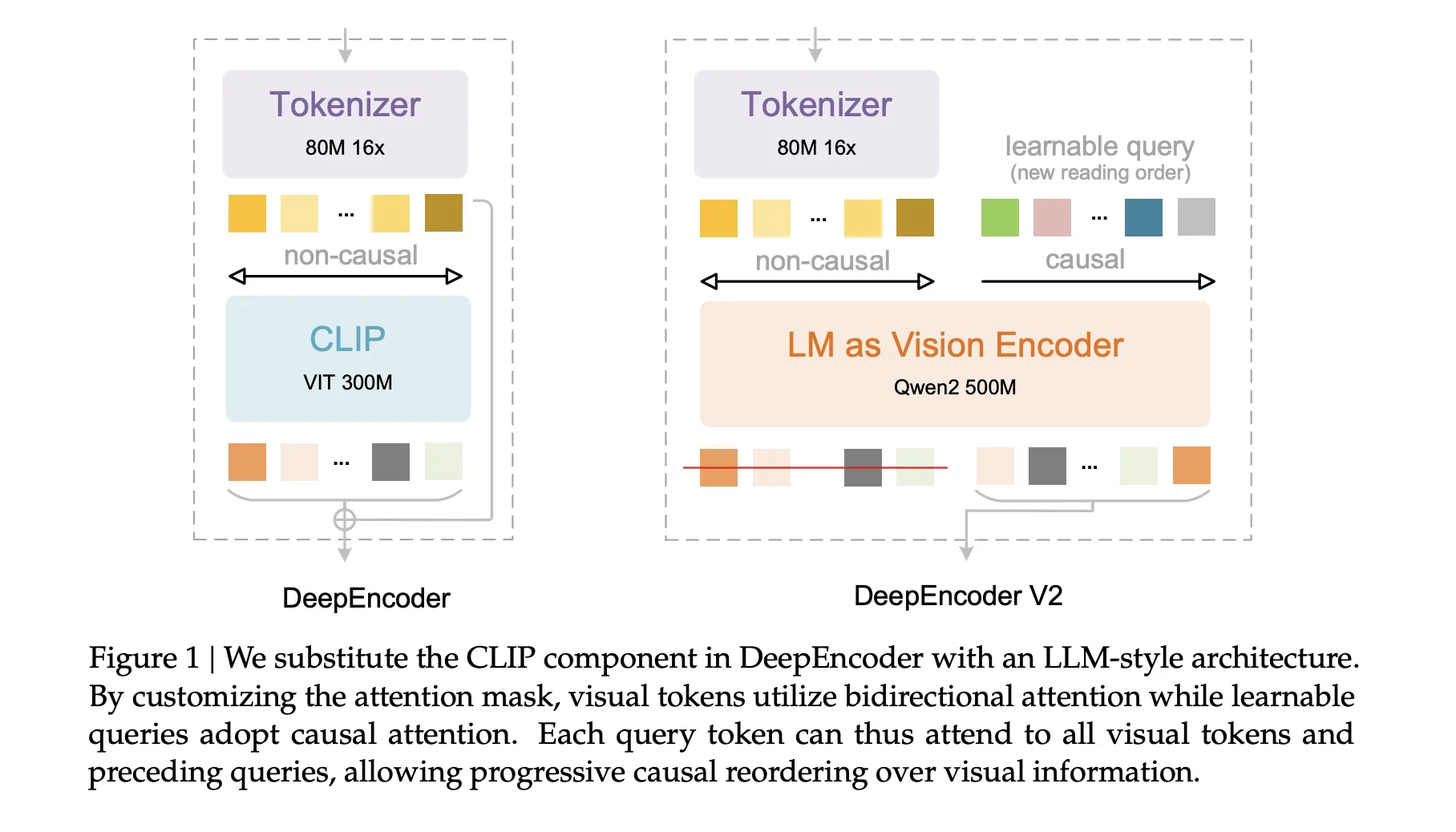
DeepSeek AI Releases DeepSeek-OCR 2 with Causal Visual Flow Encoder for Layout Aware Document UnderstandingMarkTechPost DeepSeek AI released DeepSeek-OCR 2, an open source document OCR and understanding system that restructures its vision encoder to read pages in a causal order that is closer to how humans scan complex documents. The key component is DeepEncoder V2, a language model style transformer that converts a 2D page into a 1D sequence of
The post DeepSeek AI Releases DeepSeek-OCR 2 with Causal Visual Flow Encoder for Layout Aware Document Understanding appeared first on MarkTechPost.
DeepSeek AI released DeepSeek-OCR 2, an open source document OCR and understanding system that restructures its vision encoder to read pages in a causal order that is closer to how humans scan complex documents. The key component is DeepEncoder V2, a language model style transformer that converts a 2D page into a 1D sequence of
The post DeepSeek AI Releases DeepSeek-OCR 2 with Causal Visual Flow Encoder for Layout Aware Document Understanding appeared first on MarkTechPost. Read More
A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU AugmentationsMarkTechPost We implement an advanced, end-to-end Kornia tutorial and demonstrate how modern, differentiable computer vision can be built entirely in PyTorch. We start by constructing GPU-accelerated, synchronized augmentation pipelines for images, masks, and keypoints, then move into differentiable geometry by optimizing a homography directly through gradient descent. We also show how learned feature matching with LoFTR
The post A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU Augmentations appeared first on MarkTechPost.
We implement an advanced, end-to-end Kornia tutorial and demonstrate how modern, differentiable computer vision can be built entirely in PyTorch. We start by constructing GPU-accelerated, synchronized augmentation pipelines for images, masks, and keypoints, then move into differentiable geometry by optimizing a homography directly through gradient descent. We also show how learned feature matching with LoFTR
The post A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU Augmentations appeared first on MarkTechPost. Read More
Agent Benchmarks Fail Public Sector Requirementscs.AI updates on arXiv.org arXiv:2601.20617v1 Announce Type: cross
Abstract: Deploying Large Language Model-based agents (LLM agents) in the public sector requires assuring that they meet the stringent legal, procedural, and structural requirements of public-sector institutions. Practitioners and researchers often turn to benchmarks for such assessments. However, it remains unclear what criteria benchmarks must meet to ensure they adequately reflect public-sector requirements, or how many existing benchmarks do so. In this paper, we first define such criteria based on a first-principles survey of public administration literature: benchmarks must be emph{process-based}, emph{realistic}, emph{public-sector-specific} and report emph{metrics} that reflect the unique requirements of the public sector. We analyse more than 1,300 benchmark papers for these criteria using an expert-validated LLM-assisted pipeline. Our results show that no single benchmark meets all of the criteria. Our findings provide a call to action for both researchers to develop public sector-relevant benchmarks and for public-sector officials to apply these criteria when evaluating their own agentic use cases.
arXiv:2601.20617v1 Announce Type: cross
Abstract: Deploying Large Language Model-based agents (LLM agents) in the public sector requires assuring that they meet the stringent legal, procedural, and structural requirements of public-sector institutions. Practitioners and researchers often turn to benchmarks for such assessments. However, it remains unclear what criteria benchmarks must meet to ensure they adequately reflect public-sector requirements, or how many existing benchmarks do so. In this paper, we first define such criteria based on a first-principles survey of public administration literature: benchmarks must be emph{process-based}, emph{realistic}, emph{public-sector-specific} and report emph{metrics} that reflect the unique requirements of the public sector. We analyse more than 1,300 benchmark papers for these criteria using an expert-validated LLM-assisted pipeline. Our results show that no single benchmark meets all of the criteria. Our findings provide a call to action for both researchers to develop public sector-relevant benchmarks and for public-sector officials to apply these criteria when evaluating their own agentic use cases. Read More
Unsupervised Ensemble Learning Through Deep Energy-based Modelscs.AI updates on arXiv.org arXiv:2601.20556v1 Announce Type: cross
Abstract: Unsupervised ensemble learning emerged to address the challenge of combining multiple learners’ predictions without access to ground truth labels or additional data. This paradigm is crucial in scenarios where evaluating individual classifier performance or understanding their strengths is challenging due to limited information. We propose a novel deep energy-based method for constructing an accurate meta-learner using only the predictions of individual learners, potentially capable of capturing complex dependence structures between them. Our approach requires no labeled data, learner features, or problem-specific information, and has theoretical guarantees for when learners are conditionally independent. We demonstrate superior performance across diverse ensemble scenarios, including challenging mixture of experts settings. Our experiments span standard ensemble datasets and curated datasets designed to test how the model fuses expertise from multiple sources. These results highlight the potential of unsupervised ensemble learning to harness collective intelligence, especially in data-scarce or privacy-sensitive environments.
arXiv:2601.20556v1 Announce Type: cross
Abstract: Unsupervised ensemble learning emerged to address the challenge of combining multiple learners’ predictions without access to ground truth labels or additional data. This paradigm is crucial in scenarios where evaluating individual classifier performance or understanding their strengths is challenging due to limited information. We propose a novel deep energy-based method for constructing an accurate meta-learner using only the predictions of individual learners, potentially capable of capturing complex dependence structures between them. Our approach requires no labeled data, learner features, or problem-specific information, and has theoretical guarantees for when learners are conditionally independent. We demonstrate superior performance across diverse ensemble scenarios, including challenging mixture of experts settings. Our experiments span standard ensemble datasets and curated datasets designed to test how the model fuses expertise from multiple sources. These results highlight the potential of unsupervised ensemble learning to harness collective intelligence, especially in data-scarce or privacy-sensitive environments. Read More
SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchipscs.AI updates on arXiv.org arXiv:2601.20309v1 Announce Type: cross
Abstract: Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving.
arXiv:2601.20309v1 Announce Type: cross
Abstract: Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving. Read More
Eliciting Least-to-Most Reasoning for Phishing URL Detectioncs.AI updates on arXiv.org arXiv:2601.20270v1 Announce Type: cross
Abstract: Phishing continues to be one of the most prevalent attack vectors, making accurate classification of phishing URLs essential. Recently, large language models (LLMs) have demonstrated promising results in phishing URL detection. However, their reasoning capabilities that enabled such performance remain underexplored. To this end, in this paper, we propose a Least-to-Most prompting framework for phishing URL detection. In particular, we introduce an “answer sensitivity” mechanism that guides Least-to-Most’s iterative approach to enhance reasoning and yield higher prediction accuracy. We evaluate our framework using three URL datasets and four state-of-the-art LLMs, comparing against a one-shot approach and a supervised model. We demonstrate that our framework outperforms the one-shot baseline while achieving performance comparable to that of the supervised model, despite requiring significantly less training data. Furthermore, our in-depth analysis highlights how the iterative reasoning enabled by Least-to-Most, and reinforced by our answer sensitivity mechanism, drives these performance gains. Overall, we show that this simple yet powerful prompting strategy consistently outperforms both one-shot and supervised approaches, despite requiring minimal training or few-shot guidance. Our experimental setup can be found in our Github repository github.sydney.edu.au/htri0928/least-to-most-phishing-detection.
arXiv:2601.20270v1 Announce Type: cross
Abstract: Phishing continues to be one of the most prevalent attack vectors, making accurate classification of phishing URLs essential. Recently, large language models (LLMs) have demonstrated promising results in phishing URL detection. However, their reasoning capabilities that enabled such performance remain underexplored. To this end, in this paper, we propose a Least-to-Most prompting framework for phishing URL detection. In particular, we introduce an “answer sensitivity” mechanism that guides Least-to-Most’s iterative approach to enhance reasoning and yield higher prediction accuracy. We evaluate our framework using three URL datasets and four state-of-the-art LLMs, comparing against a one-shot approach and a supervised model. We demonstrate that our framework outperforms the one-shot baseline while achieving performance comparable to that of the supervised model, despite requiring significantly less training data. Furthermore, our in-depth analysis highlights how the iterative reasoning enabled by Least-to-Most, and reinforced by our answer sensitivity mechanism, drives these performance gains. Overall, we show that this simple yet powerful prompting strategy consistently outperforms both one-shot and supervised approaches, despite requiring minimal training or few-shot guidance. Our experimental setup can be found in our Github repository github.sydney.edu.au/htri0928/least-to-most-phishing-detection. Read More
Inside OpenAI’s in-house data agentOpenAI News How OpenAI built an in-house AI data agent that uses GPT-5, Codex, and memory to reason over massive datasets and deliver reliable insights in minutes.
How OpenAI built an in-house AI data agent that uses GPT-5, Codex, and memory to reason over massive datasets and deliver reliable insights in minutes. Read More

Insurers betting big on AI: AccentureAI News New research from Accenture has discovered insurance executives are planning on increased investment into AI during 2026 despite a widening skills gap in insurance organisations. Surveying 3,650 C-suite leaders over 20 industries and 20 countries, the Pulse of Change poll revealed 90% of the 218 senior insurance executives intend to spend more on AI over
The post Insurers betting big on AI: Accenture appeared first on AI News.
New research from Accenture has discovered insurance executives are planning on increased investment into AI during 2026 despite a widening skills gap in insurance organisations. Surveying 3,650 C-suite leaders over 20 industries and 20 countries, the Pulse of Change poll revealed 90% of the 218 senior insurance executives intend to spend more on AI over
The post Insurers betting big on AI: Accenture appeared first on AI News. Read More