
A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEENMarkTechPost In this tutorial, we walk through an end-to-end, advanced workflow for knowledge graph embeddings using PyKEEN, actively exploring how modern embedding models are trained, evaluated, optimized, and interpreted in practice. We start by understanding the structure of a real knowledge graph dataset, then systematically train and compare multiple embedding models, tune their hyperparameters, and analyze
The post A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEEN appeared first on MarkTechPost.
In this tutorial, we walk through an end-to-end, advanced workflow for knowledge graph embeddings using PyKEEN, actively exploring how modern embedding models are trained, evaluated, optimized, and interpreted in practice. We start by understanding the structure of a real knowledge graph dataset, then systematically train and compare multiple embedding models, tune their hyperparameters, and analyze
The post A Coding Implementation to Training, Optimizing, Evaluating, and Interpreting Knowledge Graph Embeddings with PyKEEN appeared first on MarkTechPost. Read More
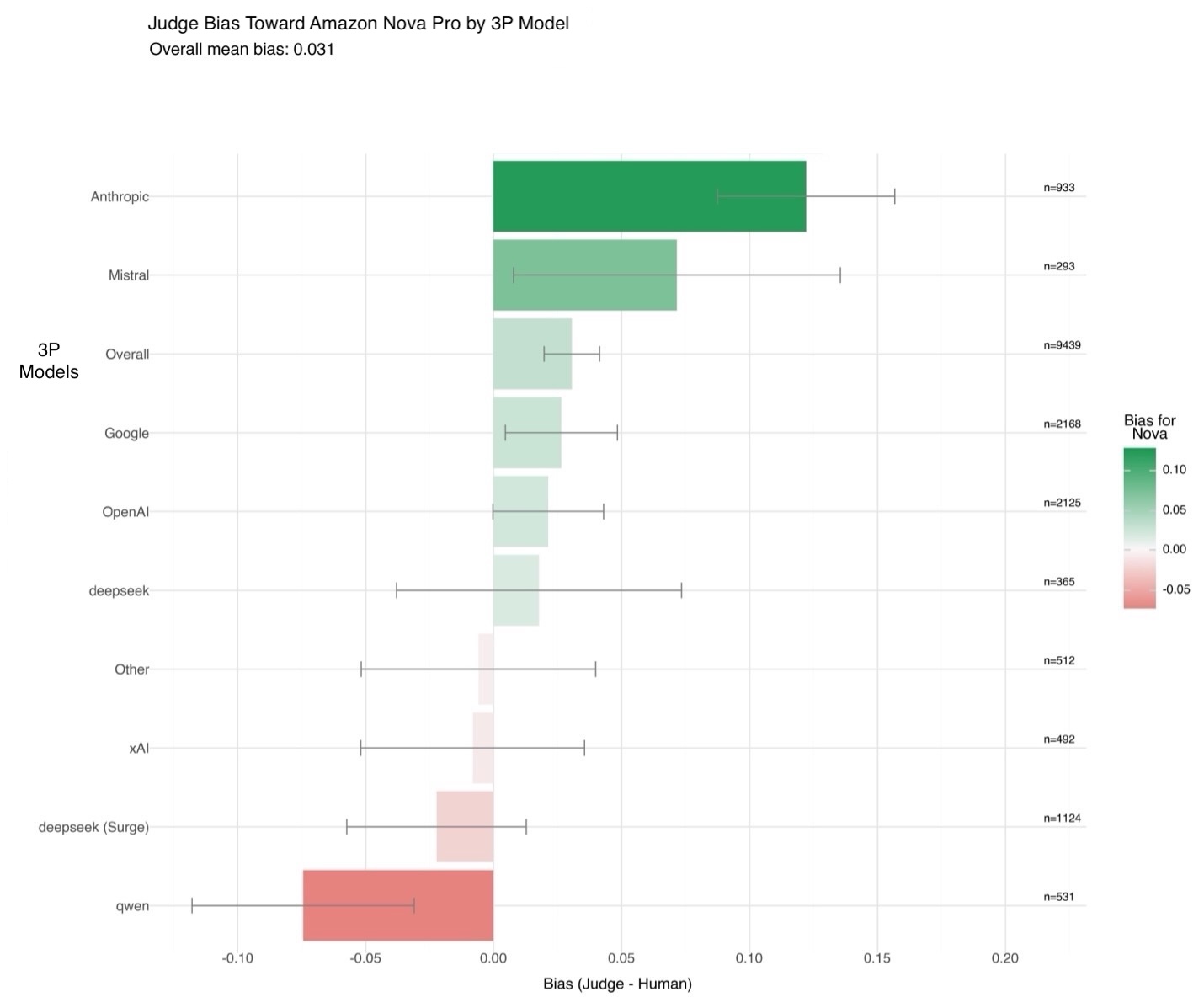
Evaluating generative AI models with Amazon Nova LLM-as-a-Judge on Amazon SageMaker AIArtificial Intelligence Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation,
Evaluating the performance of large language models (LLMs) goes beyond statistical metrics like perplexity or bilingual evaluation understudy (BLEU) scores. For most real-world generative AI scenarios, it’s crucial to understand whether a model is producing better outputs than a baseline or an earlier iteration. This is especially important for applications such as summarization, content generation, Read More
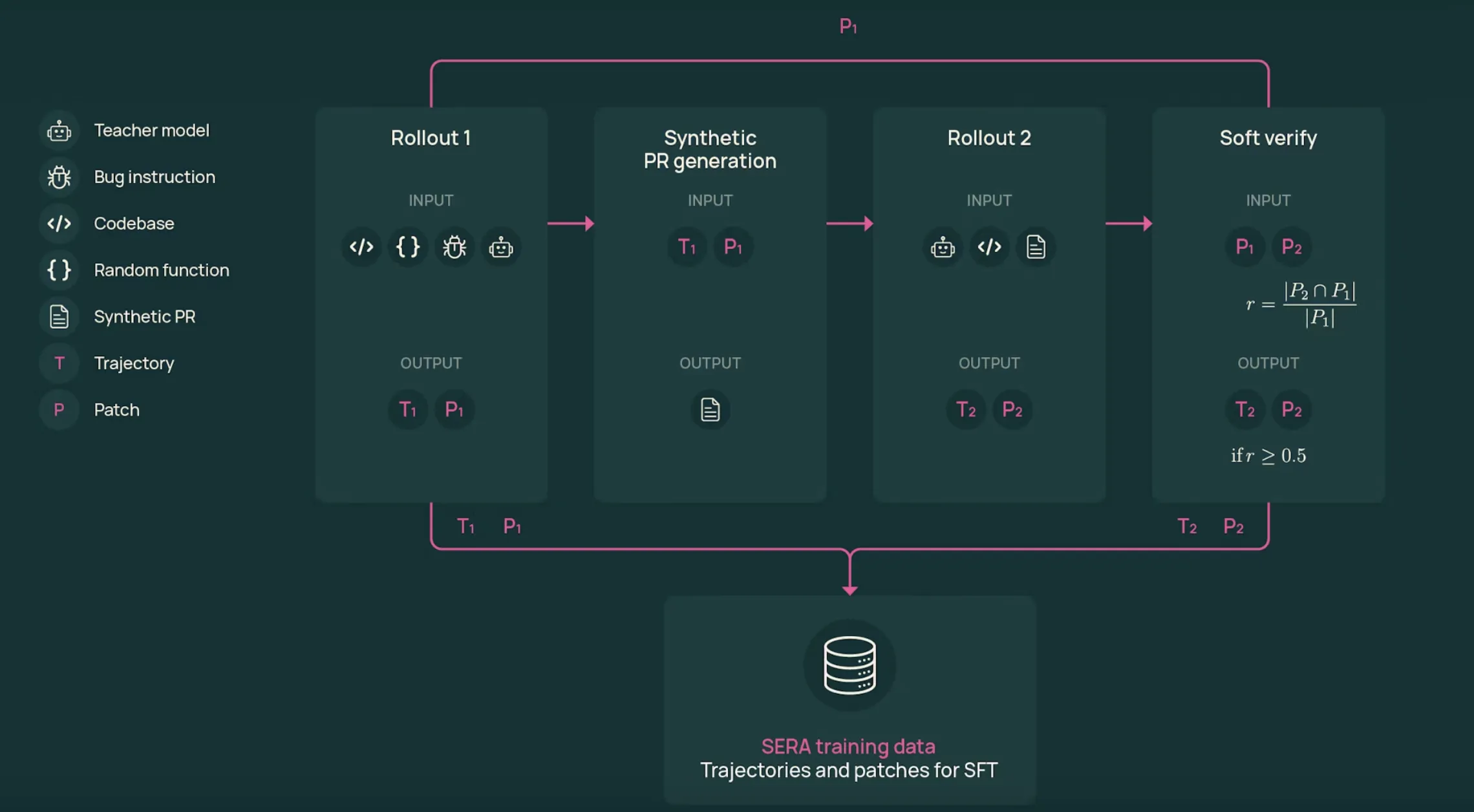
AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation WorkflowsMarkTechPost Allen Institute for AI (AI2) Researchers introduce SERA, Soft Verified Efficient Repository Agents, as a coding agent family that aims to match much larger closed systems using only supervised training and synthetic trajectories. What is SERA? SERA is the first release in AI2’s Open Coding Agents series. The flagship model, SERA-32B, is built on the
The post AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation Workflows appeared first on MarkTechPost.
Allen Institute for AI (AI2) Researchers introduce SERA, Soft Verified Efficient Repository Agents, as a coding agent family that aims to match much larger closed systems using only supervised training and synthetic trajectories. What is SERA? SERA is the first release in AI2’s Open Coding Agents series. The flagship model, SERA-32B, is built on the
The post AI2 Releases SERA, Soft Verified Coding Agents Built with Supervised Training Only for Practical Repository Level Automation Workflows appeared first on MarkTechPost. Read More
Large language models accurately predict public perceptions of support for climate action worldwidecs.AI updates on arXiv.org arXiv:2601.20141v1 Announce Type: cross
Abstract: Although most people support climate action, widespread underestimation of others’ support stalls individual and systemic changes. In this preregistered experiment, we test whether large language models (LLMs) can reliably predict these perception gaps worldwide. Using country-level indicators and public opinion data from 125 countries, we benchmark four state-of-the-art LLMs against Gallup World Poll 2021/22 data and statistical regressions. LLMs, particularly Claude, accurately capture public perceptions of others’ willingness to contribute financially to climate action (MAE approximately 5 p.p.; r = .77), comparable to statistical models, though performance declines in less digitally connected, lower-GDP countries. Controlled tests show that LLMs capture the key psychological process – social projection with a systematic downward bias – and rely on structured reasoning rather than memorized values. Overall, LLMs provide a rapid tool for assessing perception gaps in climate action, serving as an alternative to costly surveys in resource-rich countries and as a complement in underrepresented populations.
arXiv:2601.20141v1 Announce Type: cross
Abstract: Although most people support climate action, widespread underestimation of others’ support stalls individual and systemic changes. In this preregistered experiment, we test whether large language models (LLMs) can reliably predict these perception gaps worldwide. Using country-level indicators and public opinion data from 125 countries, we benchmark four state-of-the-art LLMs against Gallup World Poll 2021/22 data and statistical regressions. LLMs, particularly Claude, accurately capture public perceptions of others’ willingness to contribute financially to climate action (MAE approximately 5 p.p.; r = .77), comparable to statistical models, though performance declines in less digitally connected, lower-GDP countries. Controlled tests show that LLMs capture the key psychological process – social projection with a systematic downward bias – and rely on structured reasoning rather than memorized values. Overall, LLMs provide a rapid tool for assessing perception gaps in climate action, serving as an alternative to costly surveys in resource-rich countries and as a complement in underrepresented populations. Read More
Dynamics of Human-AI Collective Knowledge on the Web: A Scalable Model and Insights for Sustainable Growthcs.AI updates on arXiv.org arXiv:2601.20099v1 Announce Type: cross
Abstract: Humans and large language models (LLMs) now co-produce and co-consume the web’s shared knowledge archives. Such human-AI collective knowledge ecosystems contain feedback loops with both benefits (e.g., faster growth, easier learning) and systemic risks (e.g., quality dilution, skill reduction, model collapse). To understand such phenomena, we propose a minimal, interpretable dynamical model of the co-evolution of archive size, archive quality, model (LLM) skill, aggregate human skill, and query volume. The model captures two content inflows (human, LLM) controlled by a gate on LLM-content admissions, two learning pathways for humans (archive study vs. LLM assistance), and two LLM-training modalities (corpus-driven scaling vs. learning from human feedback). Through numerical experiments, we identify different growth regimes (e.g., healthy growth, inverted flow, inverted learning, oscillations), and show how platform and policy levers (gate strictness, LLM training, human learning pathways) shift the system across regime boundaries. Two domain configurations (PubMed, GitHub and Copilot) illustrate contrasting steady states under different growth rates and moderation norms. We also fit the model to Wikipedia’s knowledge flow during pre-ChatGPT and post-ChatGPT eras separately. We find a rise in LLM additions with a concurrent decline in human inflow, consistent with a regime identified by the model. Our model and analysis yield actionable insights for sustainable growth of human-AI collective knowledge on the Web.
arXiv:2601.20099v1 Announce Type: cross
Abstract: Humans and large language models (LLMs) now co-produce and co-consume the web’s shared knowledge archives. Such human-AI collective knowledge ecosystems contain feedback loops with both benefits (e.g., faster growth, easier learning) and systemic risks (e.g., quality dilution, skill reduction, model collapse). To understand such phenomena, we propose a minimal, interpretable dynamical model of the co-evolution of archive size, archive quality, model (LLM) skill, aggregate human skill, and query volume. The model captures two content inflows (human, LLM) controlled by a gate on LLM-content admissions, two learning pathways for humans (archive study vs. LLM assistance), and two LLM-training modalities (corpus-driven scaling vs. learning from human feedback). Through numerical experiments, we identify different growth regimes (e.g., healthy growth, inverted flow, inverted learning, oscillations), and show how platform and policy levers (gate strictness, LLM training, human learning pathways) shift the system across regime boundaries. Two domain configurations (PubMed, GitHub and Copilot) illustrate contrasting steady states under different growth rates and moderation norms. We also fit the model to Wikipedia’s knowledge flow during pre-ChatGPT and post-ChatGPT eras separately. We find a rise in LLM additions with a concurrent decline in human inflow, consistent with a regime identified by the model. Our model and analysis yield actionable insights for sustainable growth of human-AI collective knowledge on the Web. Read More
How AI Impacts Skill Formationcs.AI updates on arXiv.org arXiv:2601.20245v1 Announce Type: cross
Abstract: AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively supervise AI remains unclear. Novice workers who rely heavily on AI to complete unfamiliar tasks may compromise their own skill acquisition in the process. We conduct randomized experiments to study how developers gained mastery of a new asynchronous programming library with and without the assistance of AI. We find that AI use impairs conceptual understanding, code reading, and debugging abilities, without delivering significant efficiency gains on average. Participants who fully delegated coding tasks showed some productivity improvements, but at the cost of learning the library. We identify six distinct AI interaction patterns, three of which involve cognitive engagement and preserve learning outcomes even when participants receive AI assistance. Our findings suggest that AI-enhanced productivity is not a shortcut to competence and AI assistance should be carefully adopted into workflows to preserve skill formation — particularly in safety-critical domains.
arXiv:2601.20245v1 Announce Type: cross
Abstract: AI assistance produces significant productivity gains across professional domains, particularly for novice workers. Yet how this assistance affects the development of skills required to effectively supervise AI remains unclear. Novice workers who rely heavily on AI to complete unfamiliar tasks may compromise their own skill acquisition in the process. We conduct randomized experiments to study how developers gained mastery of a new asynchronous programming library with and without the assistance of AI. We find that AI use impairs conceptual understanding, code reading, and debugging abilities, without delivering significant efficiency gains on average. Participants who fully delegated coding tasks showed some productivity improvements, but at the cost of learning the library. We identify six distinct AI interaction patterns, three of which involve cognitive engagement and preserve learning outcomes even when participants receive AI assistance. Our findings suggest that AI-enhanced productivity is not a shortcut to competence and AI assistance should be carefully adopted into workflows to preserve skill formation — particularly in safety-critical domains. Read More
NCSAM Noise-Compensated Sharpness-Aware Minimization for Noisy Label Learningcs.AI updates on arXiv.org arXiv:2601.19947v1 Announce Type: cross
Abstract: Learning from Noisy Labels (LNL) presents a fundamental challenge in deep learning, as real-world datasets often contain erroneous or corrupted annotations, textit{e.g.}, data crawled from Web. Current research focuses on sophisticated label correction mechanisms. In contrast, this paper adopts a novel perspective by establishing a theoretical analysis the relationship between flatness of the loss landscape and the presence of label noise. In this paper, we theoretically demonstrate that carefully simulated label noise synergistically enhances both the generalization performance and robustness of label noises. Consequently, we propose Noise-Compensated Sharpness-aware Minimization (NCSAM) to leverage the perturbation of Sharpness-Aware Minimization (SAM) to remedy the damage of label noises. Our analysis reveals that the testing accuracy exhibits a similar behavior that has been observed on the noise-clear dataset. Extensive experimental results on multiple benchmark datasets demonstrate the consistent superiority of the proposed method over existing state-of-the-art approaches on diverse tasks.
arXiv:2601.19947v1 Announce Type: cross
Abstract: Learning from Noisy Labels (LNL) presents a fundamental challenge in deep learning, as real-world datasets often contain erroneous or corrupted annotations, textit{e.g.}, data crawled from Web. Current research focuses on sophisticated label correction mechanisms. In contrast, this paper adopts a novel perspective by establishing a theoretical analysis the relationship between flatness of the loss landscape and the presence of label noise. In this paper, we theoretically demonstrate that carefully simulated label noise synergistically enhances both the generalization performance and robustness of label noises. Consequently, we propose Noise-Compensated Sharpness-aware Minimization (NCSAM) to leverage the perturbation of Sharpness-Aware Minimization (SAM) to remedy the damage of label noises. Our analysis reveals that the testing accuracy exhibits a similar behavior that has been observed on the noise-clear dataset. Extensive experimental results on multiple benchmark datasets demonstrate the consistent superiority of the proposed method over existing state-of-the-art approaches on diverse tasks. Read More

5 Fun APIs for Absolute BeginnersKDnuggets Five APIs that make experimenting with AI and web data easy, practical, and beginner-friendly.
Five APIs that make experimenting with AI and web data easy, practical, and beginner-friendly. Read More

AI use surges at Travelers as call centre roles reduceAI News Mid-January saw insurance company, Travelers, announce a new deal that empowers 10,000 engineers and data scientists with AI assistants. However, less than two weeks on, Travelers’ leadership explained that the company’s true competitive advantage lies in expertise, not AIs alone, believing this is what will drive longer-term profit growth. According to Travelers’ chief executive officer
The post AI use surges at Travelers as call centre roles reduce appeared first on AI News.
Mid-January saw insurance company, Travelers, announce a new deal that empowers 10,000 engineers and data scientists with AI assistants. However, less than two weeks on, Travelers’ leadership explained that the company’s true competitive advantage lies in expertise, not AIs alone, believing this is what will drive longer-term profit growth. According to Travelers’ chief executive officer
The post AI use surges at Travelers as call centre roles reduce appeared first on AI News. Read More
A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU AugmentationsMarkTechPost We implement an advanced, end-to-end Kornia tutorial and demonstrate how modern, differentiable computer vision can be built entirely in PyTorch. We start by constructing GPU-accelerated, synchronized augmentation pipelines for images, masks, and keypoints, then move into differentiable geometry by optimizing a homography directly through gradient descent. We also show how learned feature matching with LoFTR
The post A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU Augmentations appeared first on MarkTechPost.
We implement an advanced, end-to-end Kornia tutorial and demonstrate how modern, differentiable computer vision can be built entirely in PyTorch. We start by constructing GPU-accelerated, synchronized augmentation pipelines for images, masks, and keypoints, then move into differentiable geometry by optimizing a homography directly through gradient descent. We also show how learned feature matching with LoFTR
The post A Coding Deep Dive into Differentiable Computer Vision with Kornia Using Geometry Optimization, LoFTR Matching, and GPU Augmentations appeared first on MarkTechPost. Read More