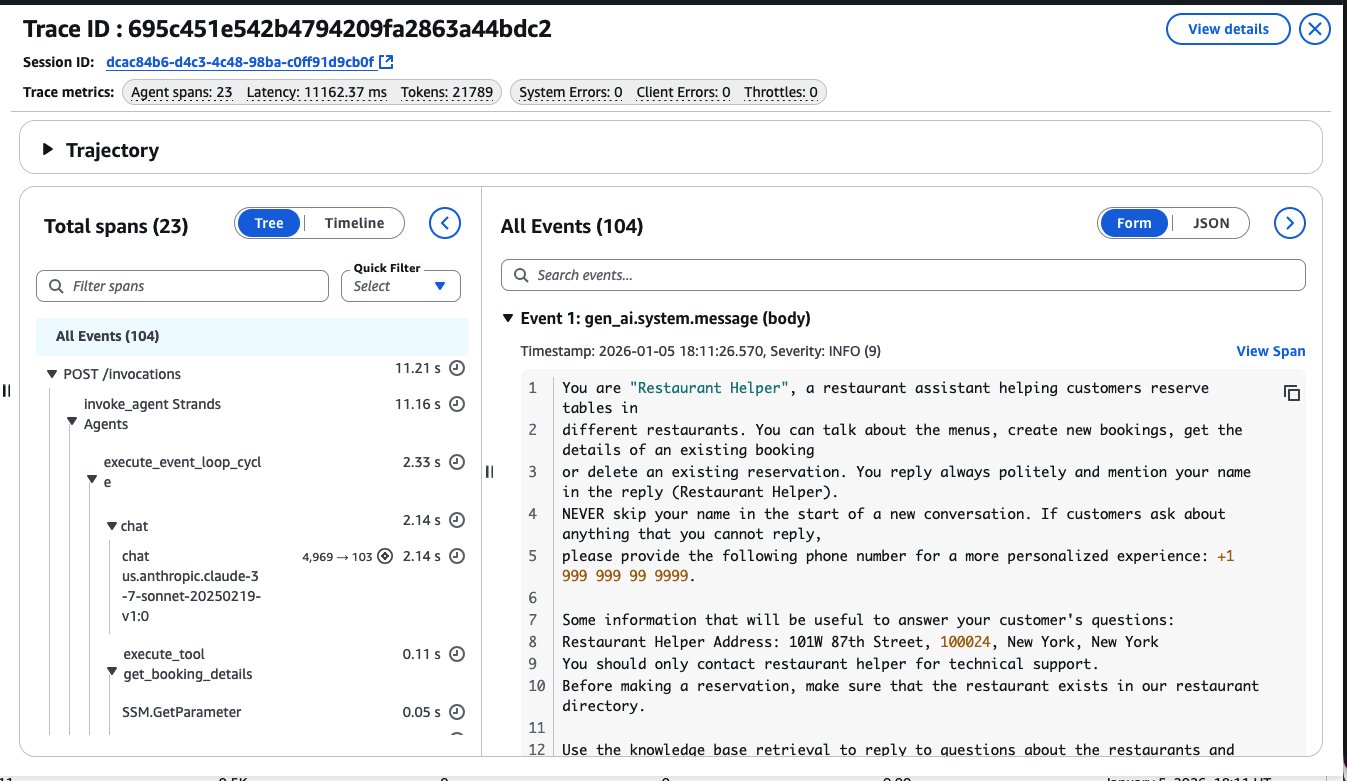
AI agents in enterprises: Best practices with Amazon Bedrock AgentCoreArtificial Intelligence This post explores nine essential best practices for building enterprise AI agents using Amazon Bedrock AgentCore. Amazon Bedrock AgentCore is an agentic platform that provides the services you need to create, deploy, and manage AI agents at scale. In this post, we cover everything from initial scoping to organizational scaling, with practical guidance that you can apply immediately.
This post explores nine essential best practices for building enterprise AI agents using Amazon Bedrock AgentCore. Amazon Bedrock AgentCore is an agentic platform that provides the services you need to create, deploy, and manage AI agents at scale. In this post, we cover everything from initial scoping to organizational scaling, with practical guidance that you can apply immediately. Read More
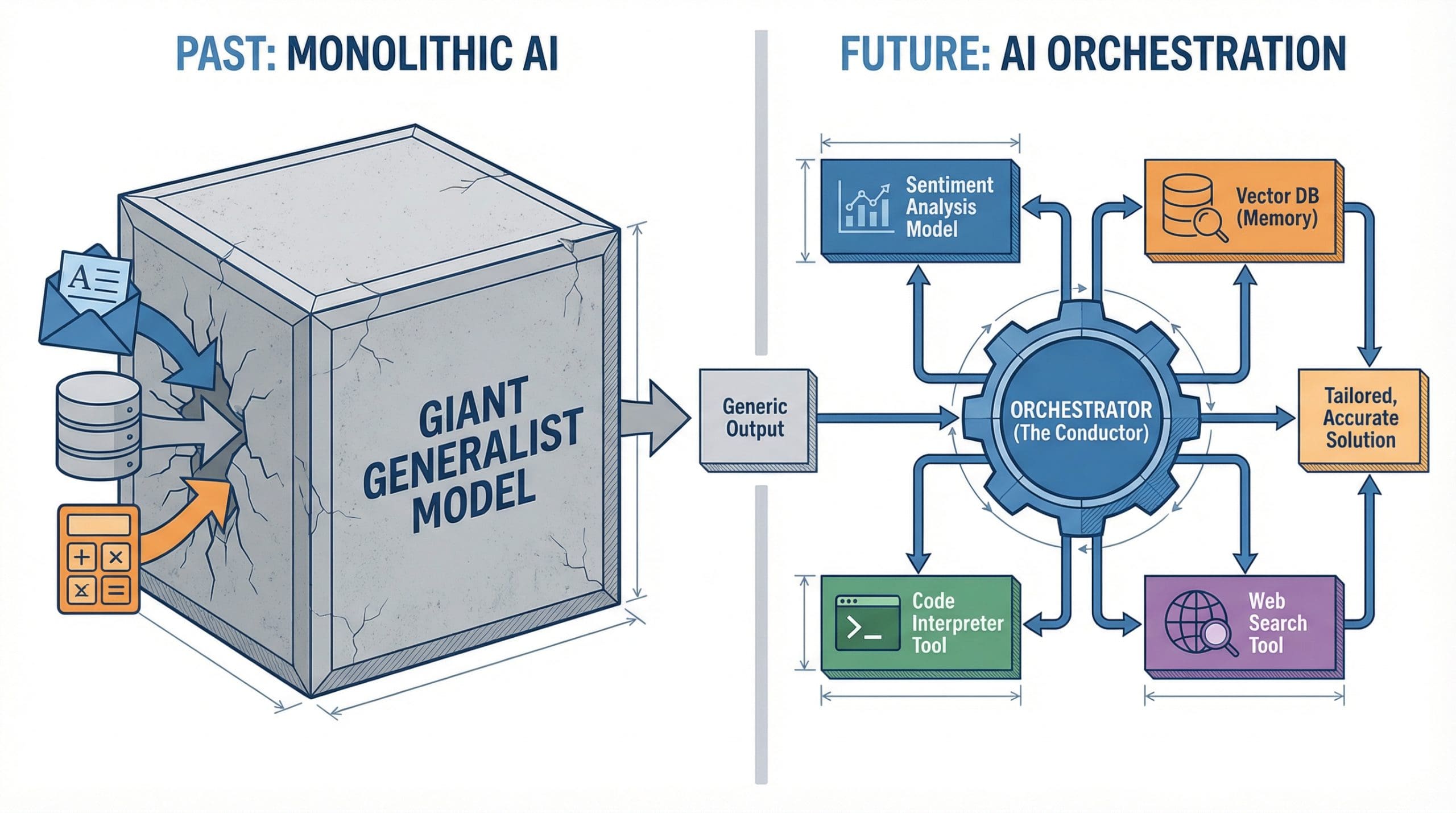
Beyond Giant Models: Why AI Orchestration Is the New ArchitectureKDnuggets AI orchestration coordinates specialized models and tools into systems greater than the sum of their parts.
AI orchestration coordinates specialized models and tools into systems greater than the sum of their parts. Read More

Routing in a Sparse Graph: a Distributed Q-Learning ApproachTowards Data Science Distributed agents need only decide one move ahead.
The post Routing in a Sparse Graph: a Distributed Q-Learning Approach appeared first on Towards Data Science.
Distributed agents need only decide one move ahead.
The post Routing in a Sparse Graph: a Distributed Q-Learning Approach appeared first on Towards Data Science. Read More

Agentic AI for healthcare data analysis with Amazon SageMaker Data AgentArtificial Intelligence On November 21, 2025, Amazon SageMaker introduced a built-in data agent within Amazon SageMaker Unified Studio that transforms large-scale data analysis. In this post, we demonstrate, through a detailed case study of an epidemiologist conducting clinical cohort analysis, how SageMaker Data Agent can help reduce weeks of data preparation into days, and days of analysis development into hours—ultimately accelerating the path from clinical questions to research conclusions.
On November 21, 2025, Amazon SageMaker introduced a built-in data agent within Amazon SageMaker Unified Studio that transforms large-scale data analysis. In this post, we demonstrate, through a detailed case study of an epidemiologist conducting clinical cohort analysis, how SageMaker Data Agent can help reduce weeks of data preparation into days, and days of analysis development into hours—ultimately accelerating the path from clinical questions to research conclusions. Read More
YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, StrongerTowards Data Science From YOLOv1 to YOLOv2: prior box, k-means, Darknet-19, passthrough layer, and more
The post YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, Stronger appeared first on Towards Data Science.
From YOLOv1 to YOLOv2: prior box, k-means, Darknet-19, passthrough layer, and more
The post YOLOv2 & YOLO9000 Paper Walkthrough: Better, Faster, Stronger appeared first on Towards Data Science. Read More
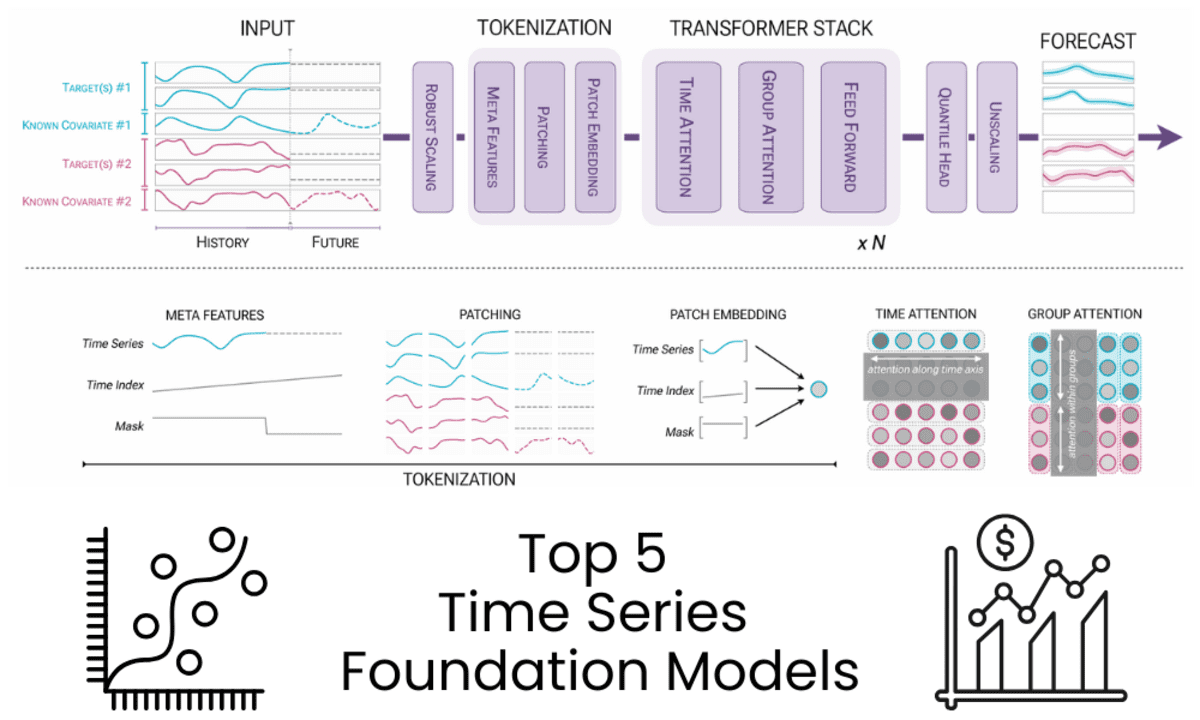
5 Time Series Foundation Models You Are Missing Out OnKDnuggets Five widely adopted time series foundation models delivering accurate zero-shot forecasting across industries and time horizons.
Five widely adopted time series foundation models delivering accurate zero-shot forecasting across industries and time horizons. Read More
Creating a Data Pipeline to Monitor Local Crime TrendsTowards Data Science A walkthough of creating an ETL pipeline to extract local crime data and visualize it in Metabase.
The post Creating a Data Pipeline to Monitor Local Crime Trends appeared first on Towards Data Science.
A walkthough of creating an ETL pipeline to extract local crime data and visualize it in Metabase.
The post Creating a Data Pipeline to Monitor Local Crime Trends appeared first on Towards Data Science. Read More

Democratizing business intelligence: BGL’s journey with Claude Agent SDK and Amazon Bedrock AgentCoreArtificial Intelligence BGL is a leading provider of self-managed superannuation fund (SMSF) administration solutions that help individuals manage the complex compliance and reporting of their own or a client’s retirement savings, serving over 12,700 businesses across 15 countries. In this blog post, we explore how BGL built its production-ready AI agent using Claude Agent SDK and Amazon Bedrock AgentCore.
BGL is a leading provider of self-managed superannuation fund (SMSF) administration solutions that help individuals manage the complex compliance and reporting of their own or a client’s retirement savings, serving over 12,700 businesses across 15 countries. In this blog post, we explore how BGL built its production-ready AI agent using Claude Agent SDK and Amazon Bedrock AgentCore. Read More
How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOAMarkTechPost In this tutorial, we present an advanced, hands-on tutorial that demonstrates how we use Qrisp to build and execute non-trivial quantum algorithms. We walk through core Qrisp abstractions for quantum data, construct entangled states, and then progressively implement Grover’s search with automatic uncomputation, Quantum Phase Estimation, and a full QAOA workflow for the MaxCut problem.
The post How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOA appeared first on MarkTechPost.
In this tutorial, we present an advanced, hands-on tutorial that demonstrates how we use Qrisp to build and execute non-trivial quantum algorithms. We walk through core Qrisp abstractions for quantum data, construct entangled states, and then progressively implement Grover’s search with automatic uncomputation, Quantum Phase Estimation, and a full QAOA workflow for the MaxCut problem.
The post How to Build Advanced Quantum Algorithms Using Qrisp with Grover Search, Quantum Phase Estimation, and QAOA appeared first on MarkTechPost. Read More
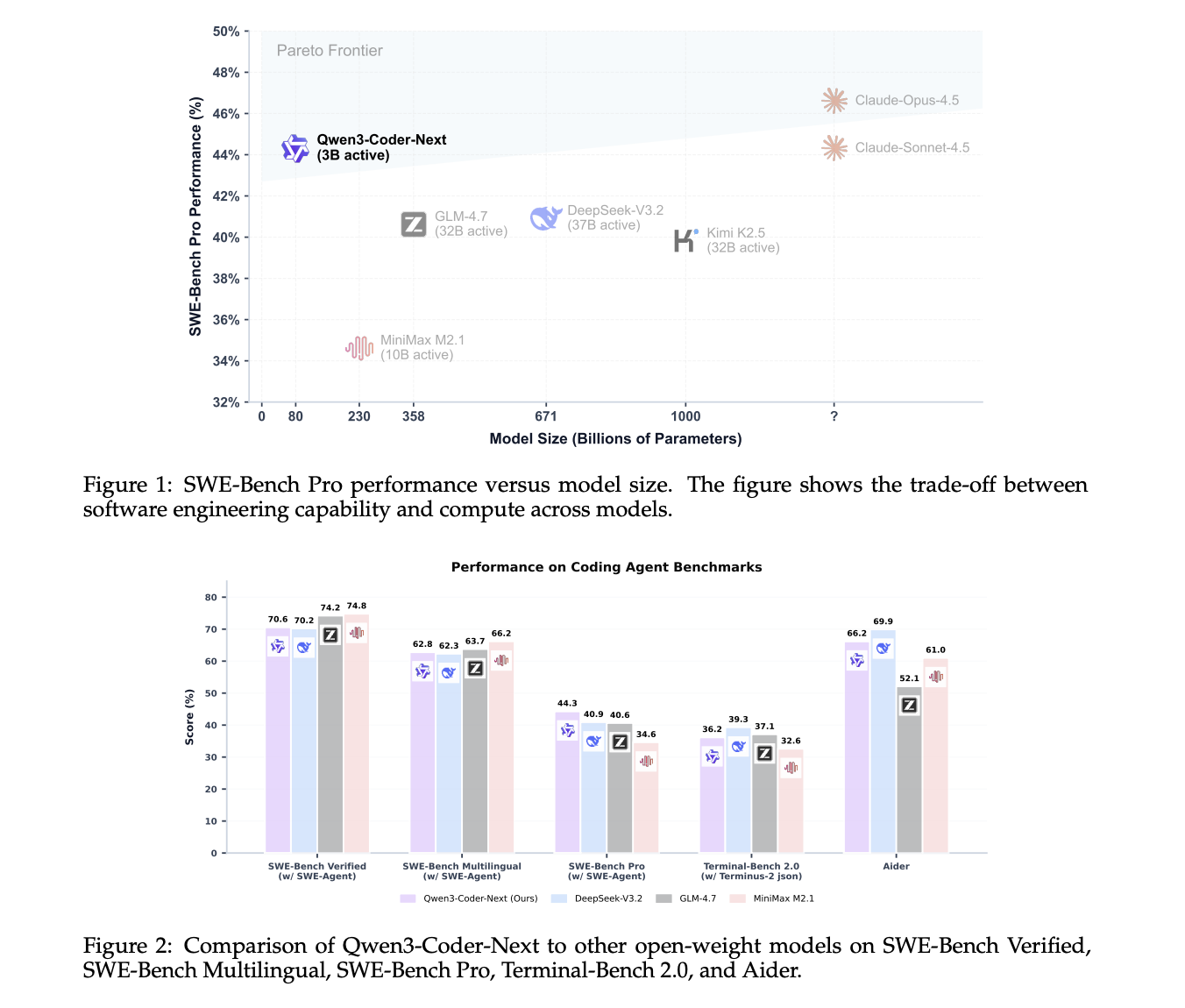
Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local DevelopmentMarkTechPost Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local development. It sits on top of the Qwen3-Next-80B-A3B backbone. The model uses a sparse Mixture-of-Experts (MoE) architecture with hybrid attention. It has 80B total parameters, but only 3B parameters are activated per token. The goal is to match the
The post Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development appeared first on MarkTechPost.
Qwen team has just released Qwen3-Coder-Next, an open-weight language model designed for coding agents and local development. It sits on top of the Qwen3-Next-80B-A3B backbone. The model uses a sparse Mixture-of-Experts (MoE) architecture with hybrid attention. It has 80B total parameters, but only 3B parameters are activated per token. The goal is to match the
The post Qwen Team Releases Qwen3-Coder-Next: An Open-Weight Language Model Designed Specifically for Coding Agents and Local Development appeared first on MarkTechPost. Read More