
5 Open Source Image Editing AI ModelsKDnuggets From real-time edits to reasoning-driven image transformations, this guide breaks down five open source AI models that are quietly reshaping how images are created and edited.
From real-time edits to reasoning-driven image transformations, this guide breaks down five open source AI models that are quietly reshaping how images are created and edited. Read More

How to Build Your Own Custom LLM Memory Layer from ScratchTowards Data Science Step-by-step guide to building autonomous memory retrieval systems
The post How to Build Your Own Custom LLM Memory Layer from Scratch appeared first on Towards Data Science.
Step-by-step guide to building autonomous memory retrieval systems
The post How to Build Your Own Custom LLM Memory Layer from Scratch appeared first on Towards Data Science. Read More
Plan–Code–Execute: Designing Agents That Create Their Own ToolsTowards Data Science The case against pre-built tools in Agentic Architectures
The post Plan–Code–Execute: Designing Agents That Create Their Own Tools appeared first on Towards Data Science.
The case against pre-built tools in Agentic Architectures
The post Plan–Code–Execute: Designing Agents That Create Their Own Tools appeared first on Towards Data Science. Read More

How Cisco builds smart systems for the AI eraAI News Among the big players in technology, Cisco is one of the sector’s leaders that’s advancing operational deployments of AI internally to its own operations, and the tools it sells to its customers around the world. As a large company, its activities encompass many areas of the typical IT stack, including infrastructure, services, security, and the
The post How Cisco builds smart systems for the AI era appeared first on AI News.
Among the big players in technology, Cisco is one of the sector’s leaders that’s advancing operational deployments of AI internally to its own operations, and the tools it sells to its customers around the world. As a large company, its activities encompass many areas of the typical IT stack, including infrastructure, services, security, and the
The post How Cisco builds smart systems for the AI era appeared first on AI News. Read More
IRIS: Implicit Reward-Guided Internal Sifting for Mitigating Multimodal Hallucinationcs.AI updates on arXiv.org arXiv:2602.01769v2 Announce Type: cross
Abstract: Hallucination remains a fundamental challenge for Multimodal Large Language Models (MLLMs). While Direct Preference Optimization (DPO) is a key alignment framework, existing approaches often rely heavily on costly external evaluators for scoring or rewriting, incurring off-policy learnability gaps and discretization loss. Due to the lack of access to internal states, such feedback overlooks the fine-grained conflicts between different modalities that lead to hallucinations during generation.
To address this issue, we propose IRIS (Implicit Reward-Guided Internal Sifting), which leverages continuous implicit rewards in the native log-probability space to preserve full information density and capture internal modal competition. This on-policy paradigm eliminates learnability gaps by utilizing self-generated preference pairs. By sifting these pairs based on multimodal implicit rewards, IRIS ensures that optimization is driven by signals that directly resolve modal conflicts. Extensive experiments demonstrate that IRIS achieves highly competitive performance on key hallucination benchmarks using only 5.7k samples, without requiring any external feedback during preference alignment. These results confirm that IRIS provides an efficient and principled paradigm for mitigating MLLM hallucinations.
arXiv:2602.01769v2 Announce Type: cross
Abstract: Hallucination remains a fundamental challenge for Multimodal Large Language Models (MLLMs). While Direct Preference Optimization (DPO) is a key alignment framework, existing approaches often rely heavily on costly external evaluators for scoring or rewriting, incurring off-policy learnability gaps and discretization loss. Due to the lack of access to internal states, such feedback overlooks the fine-grained conflicts between different modalities that lead to hallucinations during generation.
To address this issue, we propose IRIS (Implicit Reward-Guided Internal Sifting), which leverages continuous implicit rewards in the native log-probability space to preserve full information density and capture internal modal competition. This on-policy paradigm eliminates learnability gaps by utilizing self-generated preference pairs. By sifting these pairs based on multimodal implicit rewards, IRIS ensures that optimization is driven by signals that directly resolve modal conflicts. Extensive experiments demonstrate that IRIS achieves highly competitive performance on key hallucination benchmarks using only 5.7k samples, without requiring any external feedback during preference alignment. These results confirm that IRIS provides an efficient and principled paradigm for mitigating MLLM hallucinations. Read More
iPEAR: Iterative Pyramid Estimation with Attention and Residuals for Deformable Medical Image Registrationcs.AI updates on arXiv.org arXiv:2510.07666v3 Announce Type: replace-cross
Abstract: Existing pyramid registration networks may accumulate anatomical misalignments and lack an effective mechanism to dynamically determine the number of optimization iterations under varying deformation requirements across images, leading to degraded performance. To solve these limitations, we propose iPEAR. Specifically, iPEAR adopts our proposed Fused Attention-Residual Module (FARM) for decoding, which comprises an attention pathway and a residual pathway to alleviate the accumulation of anatomical misalignment. We further propose a dual-stage Threshold-Controlled Iterative (TCI) strategy that adaptively determines the number of optimization iterations for varying images by evaluating registration stability and convergence. Extensive experiments on three public brain MRI datasets and one public abdomen CT dataset show that iPEAR outperforms state-of-the-art (SOTA) registration networks in terms of accuracy, while achieving on-par inference speed and model parameter size. Generalization and ablation studies further validate the effectiveness of the proposed FARM and TCI.
arXiv:2510.07666v3 Announce Type: replace-cross
Abstract: Existing pyramid registration networks may accumulate anatomical misalignments and lack an effective mechanism to dynamically determine the number of optimization iterations under varying deformation requirements across images, leading to degraded performance. To solve these limitations, we propose iPEAR. Specifically, iPEAR adopts our proposed Fused Attention-Residual Module (FARM) for decoding, which comprises an attention pathway and a residual pathway to alleviate the accumulation of anatomical misalignment. We further propose a dual-stage Threshold-Controlled Iterative (TCI) strategy that adaptively determines the number of optimization iterations for varying images by evaluating registration stability and convergence. Extensive experiments on three public brain MRI datasets and one public abdomen CT dataset show that iPEAR outperforms state-of-the-art (SOTA) registration networks in terms of accuracy, while achieving on-par inference speed and model parameter size. Generalization and ablation studies further validate the effectiveness of the proposed FARM and TCI. Read More

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated : Feb 3rd, 2026 What Is The NIST AI RMF? The Framework in 60 Seconds: The NIST AI Risk Management Framework (AI RMF 1.0) is a voluntary, outcome-based guide for managing AI risks across any sector or organization […]

Table of Contents Weekly Security Intelligence Briefing TJS Weekly Security Intelligence Briefing – Week of Feb 2nd 2026 1. Executive Summary 2. Critical Action Items 3. Key Security Stories Story 1: Notepad++ Supply Chain Attack – Chinese APT Delivered Chrysalis Backdoor for 6 Months Story 2: WinRAR CVE-2025-8088 – Four Nation-State Groups Exploiting Path Traversal […]

Notepad++ Supply Chain Attack – 2026 Report Date: February 3, 2026 Classification: Public Threat Type: Supply Chain Compromise Attribution: Lotus Blossom (Moderate Confidence) Executive Summary Notepad++ confirmed an infrastructure-level compromise affecting its update mechanism from June through December 2025. Attackers hijacked the hosting provider’s server to selectively redirect update requests from targeted users to malicious […]
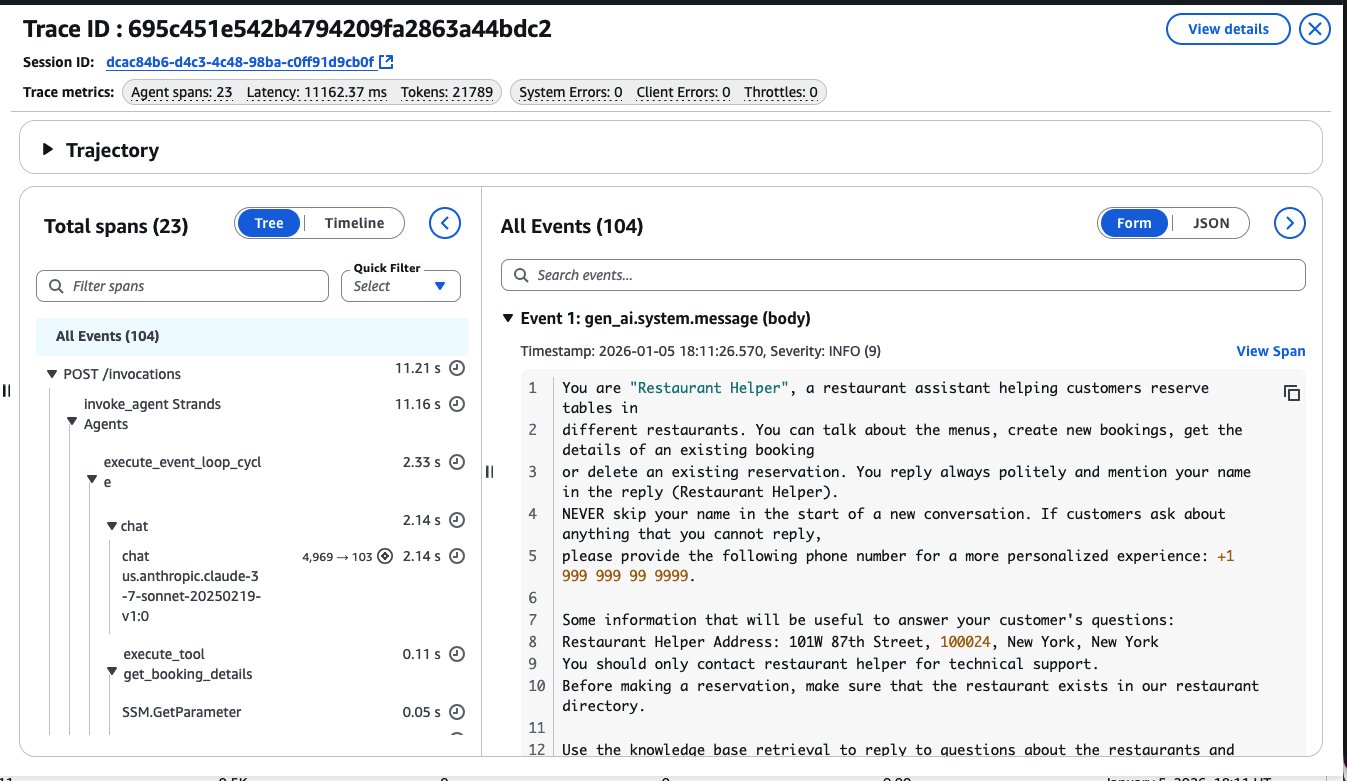
AI agents in enterprises: Best practices with Amazon Bedrock AgentCoreArtificial Intelligence This post explores nine essential best practices for building enterprise AI agents using Amazon Bedrock AgentCore. Amazon Bedrock AgentCore is an agentic platform that provides the services you need to create, deploy, and manage AI agents at scale. In this post, we cover everything from initial scoping to organizational scaling, with practical guidance that you can apply immediately.
This post explores nine essential best practices for building enterprise AI agents using Amazon Bedrock AgentCore. Amazon Bedrock AgentCore is an agentic platform that provides the services you need to create, deploy, and manage AI agents at scale. In this post, we cover everything from initial scoping to organizational scaling, with practical guidance that you can apply immediately. Read More