
Beyond Words and Pixels: A Benchmark for Implicit World Knowledge Reasoning in Generative Modelscs.AI updates on arXiv.org arXiv:2511.18271v3 Announce Type: replace-cross
Abstract: Text-to-image (T2I) models today are capable of producing photorealistic, instruction-following images, yet they still frequently fail on prompts that require implicit world knowledge. Existing evaluation protocols either emphasize compositional alignment or rely on single-round VQA-based scoring, leaving critical dimensions such as knowledge grounding, multi-physics interactions, and auditable evidence-substantially undertested. To address these limitations, we introduce PicWorld, the first comprehensive benchmark that assesses the grasp of implicit world knowledge and physical causal reasoning of T2I models. This benchmark consists of 1,100 prompts across three core categories. To facilitate fine-grained evaluation, we propose PW-Agent, an evidence-grounded multi-agent evaluator to hierarchically assess images on their physical realism and logical consistency by decomposing prompts into verifiable visual evidence. We conduct a thorough analysis of 17 mainstream T2I models on PicWorld, illustrating that they universally exhibit a fundamental limitation in their capacity for implicit world knowledge and physical causal reasoning to varying degrees. The findings highlight the need for reasoning-aware, knowledge-integrative architectures in future T2I systems.
arXiv:2511.18271v3 Announce Type: replace-cross
Abstract: Text-to-image (T2I) models today are capable of producing photorealistic, instruction-following images, yet they still frequently fail on prompts that require implicit world knowledge. Existing evaluation protocols either emphasize compositional alignment or rely on single-round VQA-based scoring, leaving critical dimensions such as knowledge grounding, multi-physics interactions, and auditable evidence-substantially undertested. To address these limitations, we introduce PicWorld, the first comprehensive benchmark that assesses the grasp of implicit world knowledge and physical causal reasoning of T2I models. This benchmark consists of 1,100 prompts across three core categories. To facilitate fine-grained evaluation, we propose PW-Agent, an evidence-grounded multi-agent evaluator to hierarchically assess images on their physical realism and logical consistency by decomposing prompts into verifiable visual evidence. We conduct a thorough analysis of 17 mainstream T2I models on PicWorld, illustrating that they universally exhibit a fundamental limitation in their capacity for implicit world knowledge and physical causal reasoning to varying degrees. The findings highlight the need for reasoning-aware, knowledge-integrative architectures in future T2I systems. Read More
Advancing Mathematical Research via Human-AI Interactive Theorem Provingcs.AI updates on arXiv.org arXiv:2512.09443v2 Announce Type: replace-cross
Abstract: We investigate how large language models can be used as research tools in scientific computing while preserving mathematical rigor. We propose a human-in-the-loop workflow for interactive theorem proving and discovery with LLMs. Human experts retain control over problem formulation and admissible assumptions, while the model searches for proofs or contradictions, proposes candidate properties and theorems, and helps construct structures and parameters that satisfy explicit constraints, supported by numerical experiments and simple verification checks. Experts treat these outputs as raw material, further refine them, and organize the results into precise statements and rigorous proofs. We instantiate this workflow in a case study on the connection between manifold optimization and Grover’s quantum search algorithm, where the pipeline helps identify invariant subspaces, explore Grover-compatible retractions, and obtain convergence guarantees for the retraction-based gradient method. The framework provides a practical template for integrating large language models into frontier mathematical research, enabling faster exploration of proof space and algorithm design while maintaining transparent reasoning responsibilities. Although illustrated on manifold optimization problems in quantum computing, the principles extend to other core areas of scientific computing.
arXiv:2512.09443v2 Announce Type: replace-cross
Abstract: We investigate how large language models can be used as research tools in scientific computing while preserving mathematical rigor. We propose a human-in-the-loop workflow for interactive theorem proving and discovery with LLMs. Human experts retain control over problem formulation and admissible assumptions, while the model searches for proofs or contradictions, proposes candidate properties and theorems, and helps construct structures and parameters that satisfy explicit constraints, supported by numerical experiments and simple verification checks. Experts treat these outputs as raw material, further refine them, and organize the results into precise statements and rigorous proofs. We instantiate this workflow in a case study on the connection between manifold optimization and Grover’s quantum search algorithm, where the pipeline helps identify invariant subspaces, explore Grover-compatible retractions, and obtain convergence guarantees for the retraction-based gradient method. The framework provides a practical template for integrating large language models into frontier mathematical research, enabling faster exploration of proof space and algorithm design while maintaining transparent reasoning responsibilities. Although illustrated on manifold optimization problems in quantum computing, the principles extend to other core areas of scientific computing. Read More

10 GitHub Repositories to Master Machine Learning DeploymentKDnuggets Master the essential skill of deploying machine learning models with courses, projects, examples, resources, and interview questions.
Master the essential skill of deploying machine learning models with courses, projects, examples, resources, and interview questions. Read More
How Harmonic Security improved their data-leakage detection system with low-latency fine-tuned models using Amazon SageMaker, Amazon Bedrock, and Amazon Nova ProArtificial Intelligence This post walks through how Harmonic Security used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Pro to fine-tune a ModernBERT model, achieving low-latency, accurate, and scalable data leakage detection.
This post walks through how Harmonic Security used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Pro to fine-tune a ModernBERT model, achieving low-latency, accurate, and scalable data leakage detection. Read More
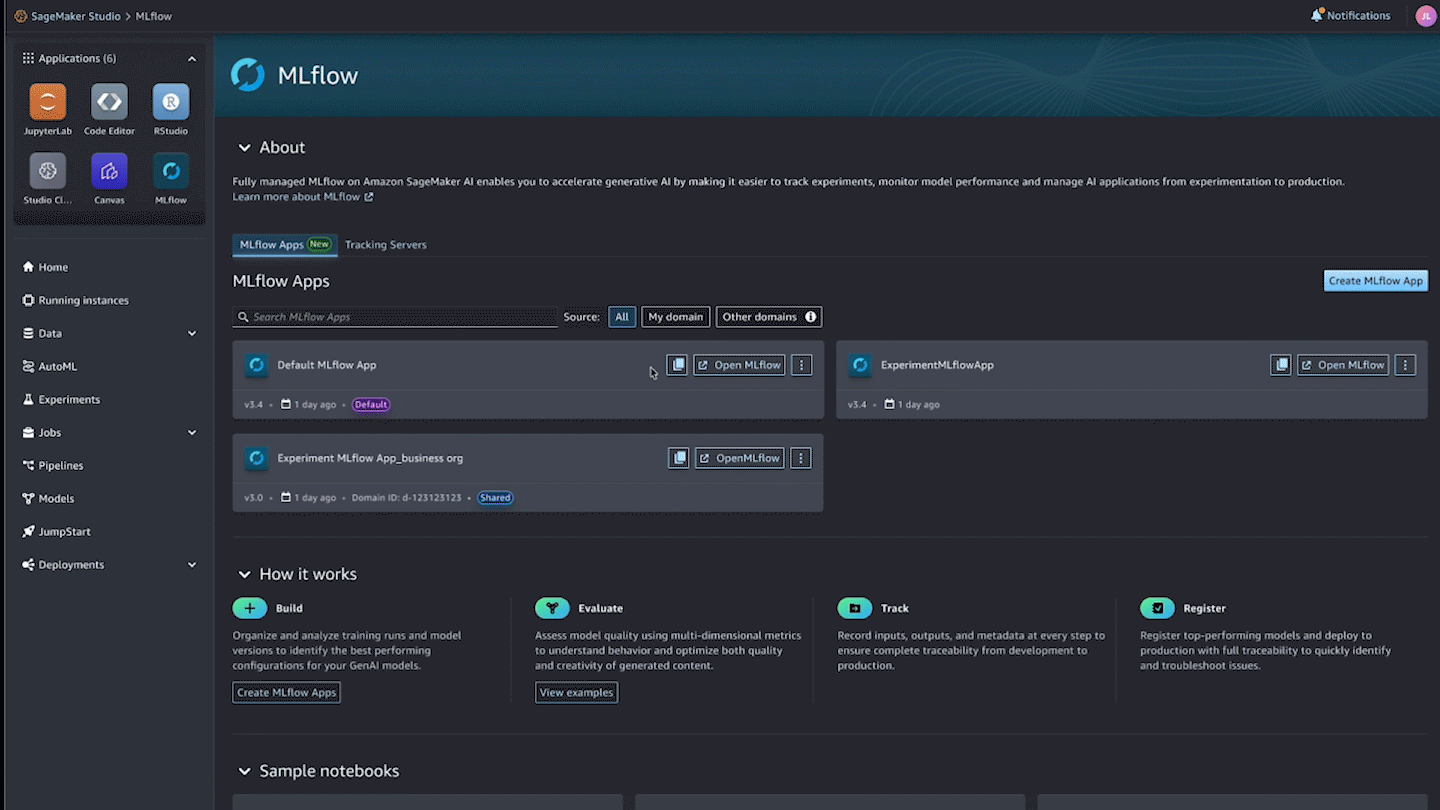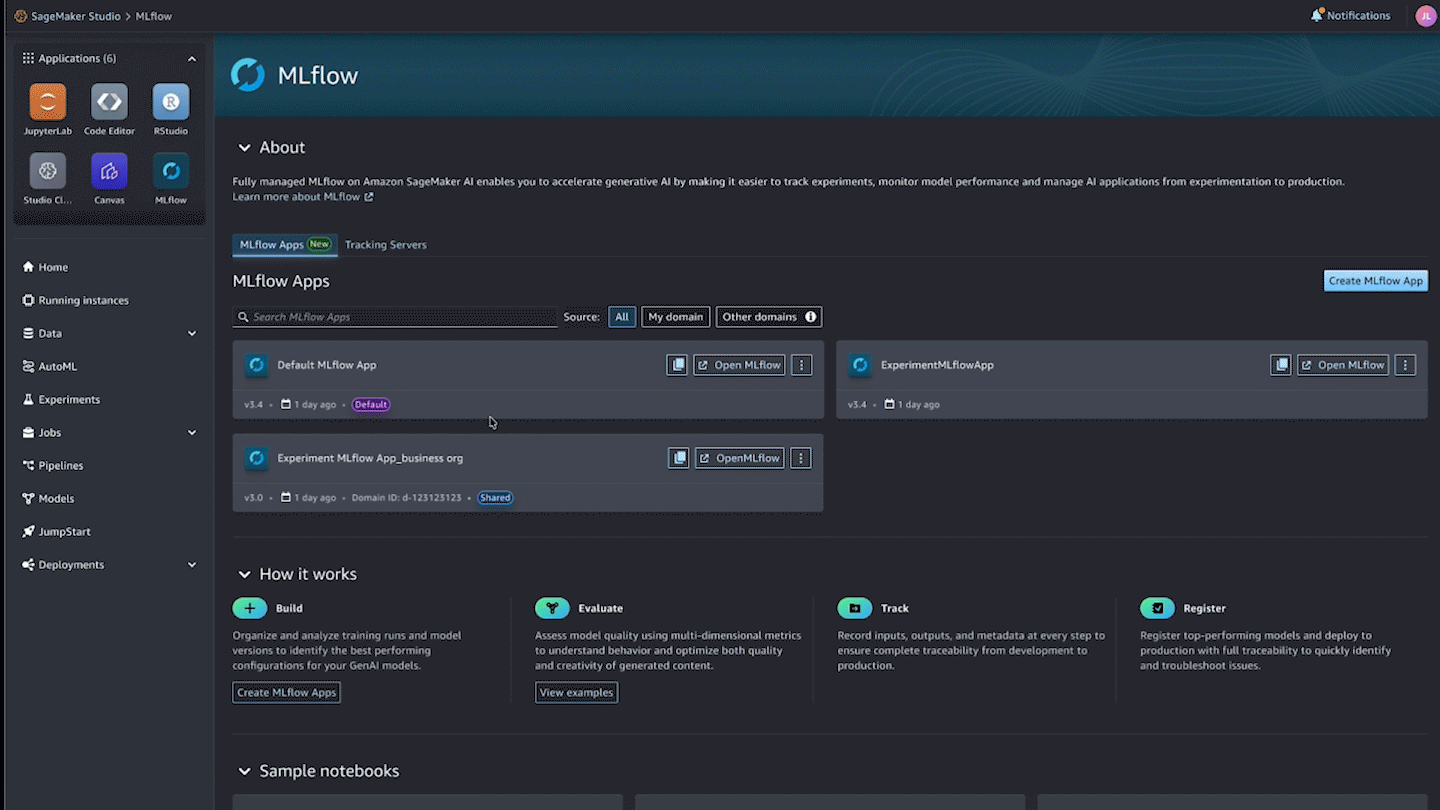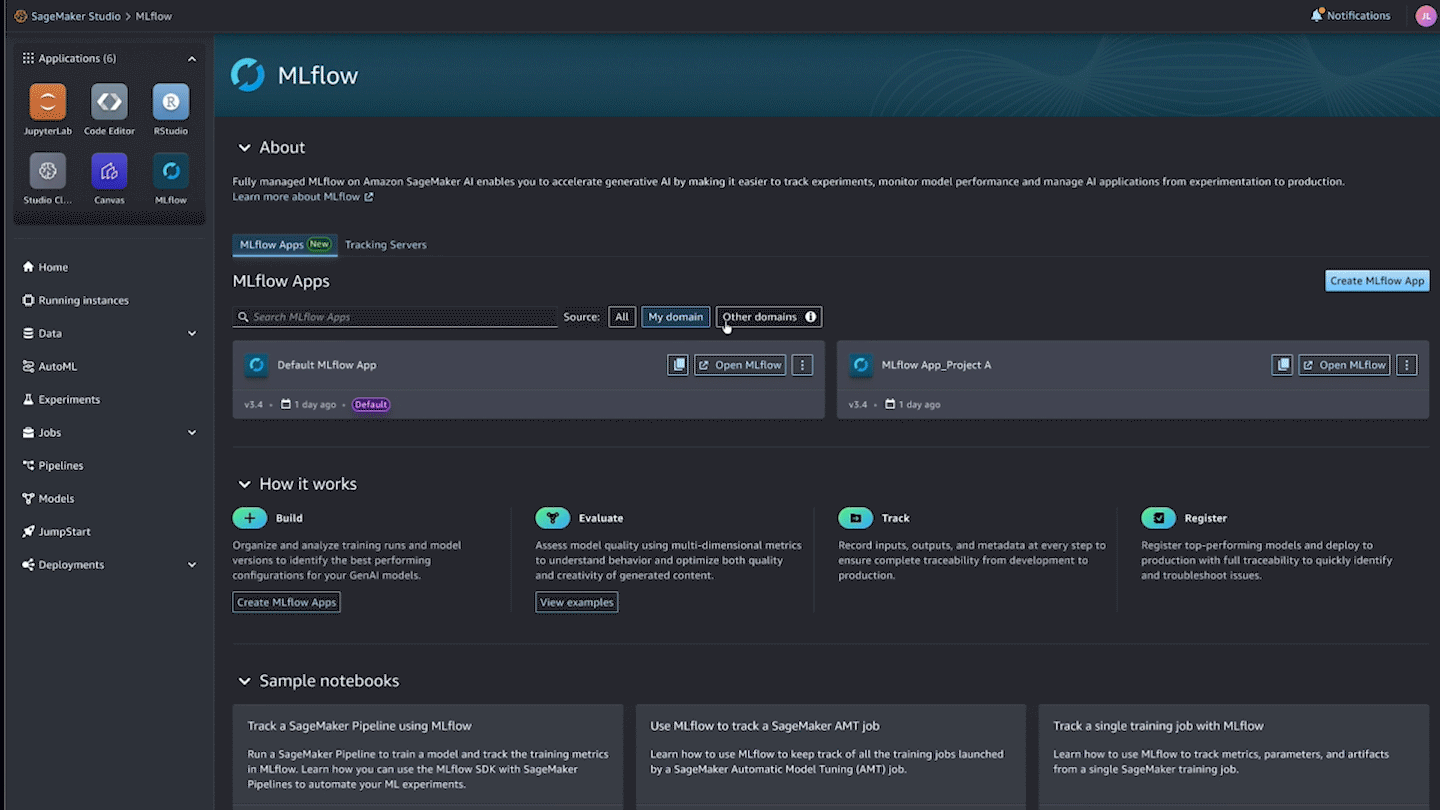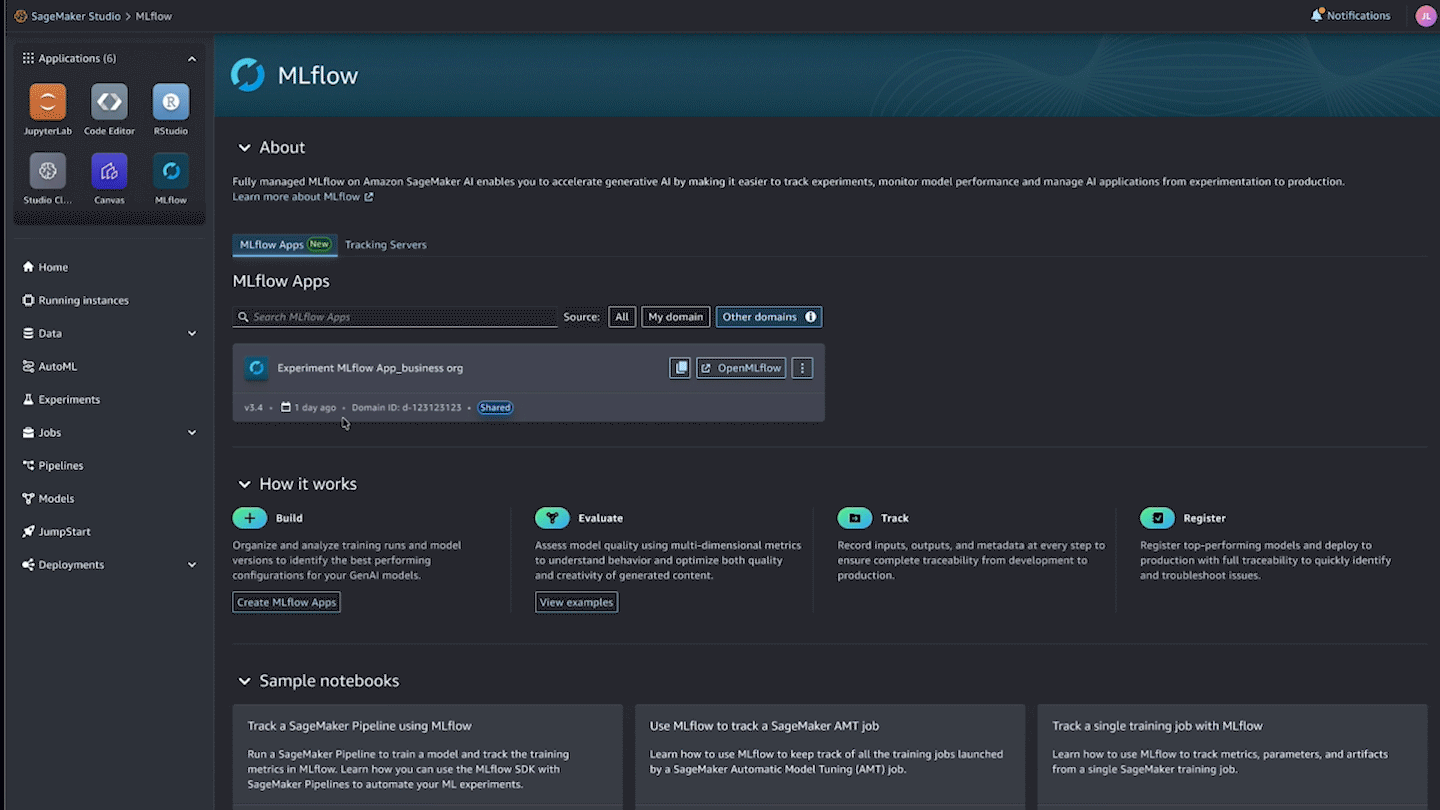
Scaling MLflow for enterprise AI: What’s New in SageMaker AI with MLflowArtificial Intelligence Today we’re announcing Amazon SageMaker AI with MLflow, now including a serverless capability that dynamically manages infrastructure provisioning, scaling, and operations for artificial intelligence and machine learning (AI/ML) development tasks. In this post, we explore how these new capabilities help you run large MLflow workloads—from generative AI agents to large language model (LLM) experimentation—with improved performance, automation, and security using SageMaker AI with MLflow.
Today we’re announcing Amazon SageMaker AI with MLflow, now including a serverless capability that dynamically manages infrastructure provisioning, scaling, and operations for artificial intelligence and machine learning (AI/ML) development tasks. In this post, we explore how these new capabilities help you run large MLflow workloads—from generative AI agents to large language model (LLM) experimentation—with improved performance, automation, and security using SageMaker AI with MLflow. Read More
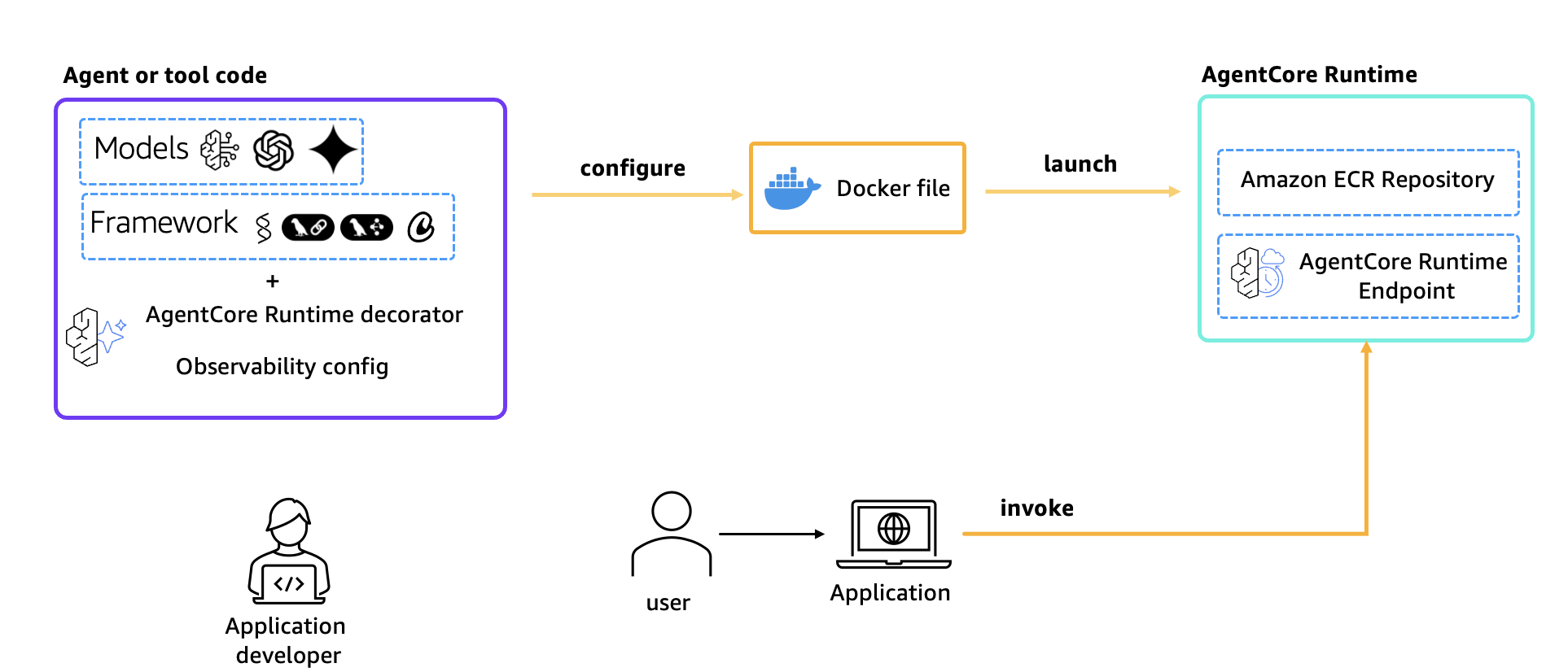
Amazon Bedrock AgentCore Observability with LangfuseArtificial Intelligence In this post, we explain how to integrate Langfuse observability with Amazon Bedrock AgentCore to gain deep visibility into an AI agent’s performance, debug issues faster, and optimize costs. We walk through a complete implementation using Strands agents deployed on AgentCore Runtime followed by step-by-step code examples.
In this post, we explain how to integrate Langfuse observability with Amazon Bedrock AgentCore to gain deep visibility into an AI agent’s performance, debug issues faster, and optimize costs. We walk through a complete implementation using Strands agents deployed on AgentCore Runtime followed by step-by-step code examples. Read More

The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research AdoptionMarkTechPost Los Angeles, December 11, 2025 — Marktechpost has released ML Global Impact Report 2025 (AIResearchTrends.com). This educational report’s analysis includes over 5,000 articles from more than 125 countries, all published within the Nature family of journals between January 1 and September 30, 2025. The scope of this report is strictly confined to this specific body
The post The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research Adoption appeared first on MarkTechPost.
Los Angeles, December 11, 2025 — Marktechpost has released ML Global Impact Report 2025 (AIResearchTrends.com). This educational report’s analysis includes over 5,000 articles from more than 125 countries, all published within the Nature family of journals between January 1 and September 30, 2025. The scope of this report is strictly confined to this specific body
The post The Machine Learning Divide: Marktechpost’s Latest ML Global Impact Report Reveals Geographic Asymmetry Between ML Tool Origins and Research Adoption appeared first on MarkTechPost. Read More

7 Steps to Mastering Agentic AIKDnuggets As AI systems begin handling more complex, multi-stage tasks, understanding agentic design is becoming essential. This article outlines seven practical steps to build reliable, effective AI agents.
As AI systems begin handling more complex, multi-stage tasks, understanding agentic design is becoming essential. This article outlines seven practical steps to build reliable, effective AI agents. Read More
The Machine Learning “Advent Calendar” Day 11: Linear Regression in ExcelTowards Data Science Linear Regression looks simple, but it introduces the core ideas of modern machine learning: loss functions, optimization, gradients, scaling, and interpretation.
In this article, we rebuild Linear Regression in Excel, compare the closed-form solution with Gradient Descent, and see how the coefficients evolve step by step.
This foundation naturally leads to regularization, kernels, classification, and the dual view.
Linear Regression is not just a straight line, but the starting point for many models we will explore next in the Advent Calendar.
The post The Machine Learning “Advent Calendar” Day 11: Linear Regression in Excel appeared first on Towards Data Science.
Linear Regression looks simple, but it introduces the core ideas of modern machine learning: loss functions, optimization, gradients, scaling, and interpretation.
In this article, we rebuild Linear Regression in Excel, compare the closed-form solution with Gradient Descent, and see how the coefficients evolve step by step.
This foundation naturally leads to regularization, kernels, classification, and the dual view.
Linear Regression is not just a straight line, but the starting point for many models we will explore next in the Advent Calendar.
The post The Machine Learning “Advent Calendar” Day 11: Linear Regression in Excel appeared first on Towards Data Science. Read More

Microsoft ‘Promptions’ fix AI prompts failing to deliverAI News Microsoft believes it has a fix for AI prompts being given, the response missing the mark, and the cycle repeating. This inefficiency is a drain on resources. The “trial-and-error loop can feel unpredictable and discouraging,” turning what should be a productivity booster into a time sink. Knowledge workers often spend more time managing the interaction
The post Microsoft ‘Promptions’ fix AI prompts failing to deliver appeared first on AI News.
Microsoft believes it has a fix for AI prompts being given, the response missing the mark, and the cycle repeating. This inefficiency is a drain on resources. The “trial-and-error loop can feel unpredictable and discouraging,” turning what should be a productivity booster into a time sink. Knowledge workers often spend more time managing the interaction
The post Microsoft ‘Promptions’ fix AI prompts failing to deliver appeared first on AI News. Read More