
Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It NeedsMarkTechPost In the fast-moving world of agentic workflows, the most powerful AI model is still only as good as its documentation. Today, Andrew Ng and his team at DeepLearning.AI officially launched Context Hub, an open-source tool designed to bridge the gap between an agent’s static training data and the rapidly evolving reality of modern APIs. You
The post Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It Needs appeared first on MarkTechPost.
In the fast-moving world of agentic workflows, the most powerful AI model is still only as good as its documentation. Today, Andrew Ng and his team at DeepLearning.AI officially launched Context Hub, an open-source tool designed to bridge the gap between an agent’s static training data and the rapidly evolving reality of modern APIs. You
The post Andrew Ng’s Team Releases Context Hub: An Open Source Tool that Gives Your Coding Agent the Up-to-Date API Documentation It Needs appeared first on MarkTechPost. Read More
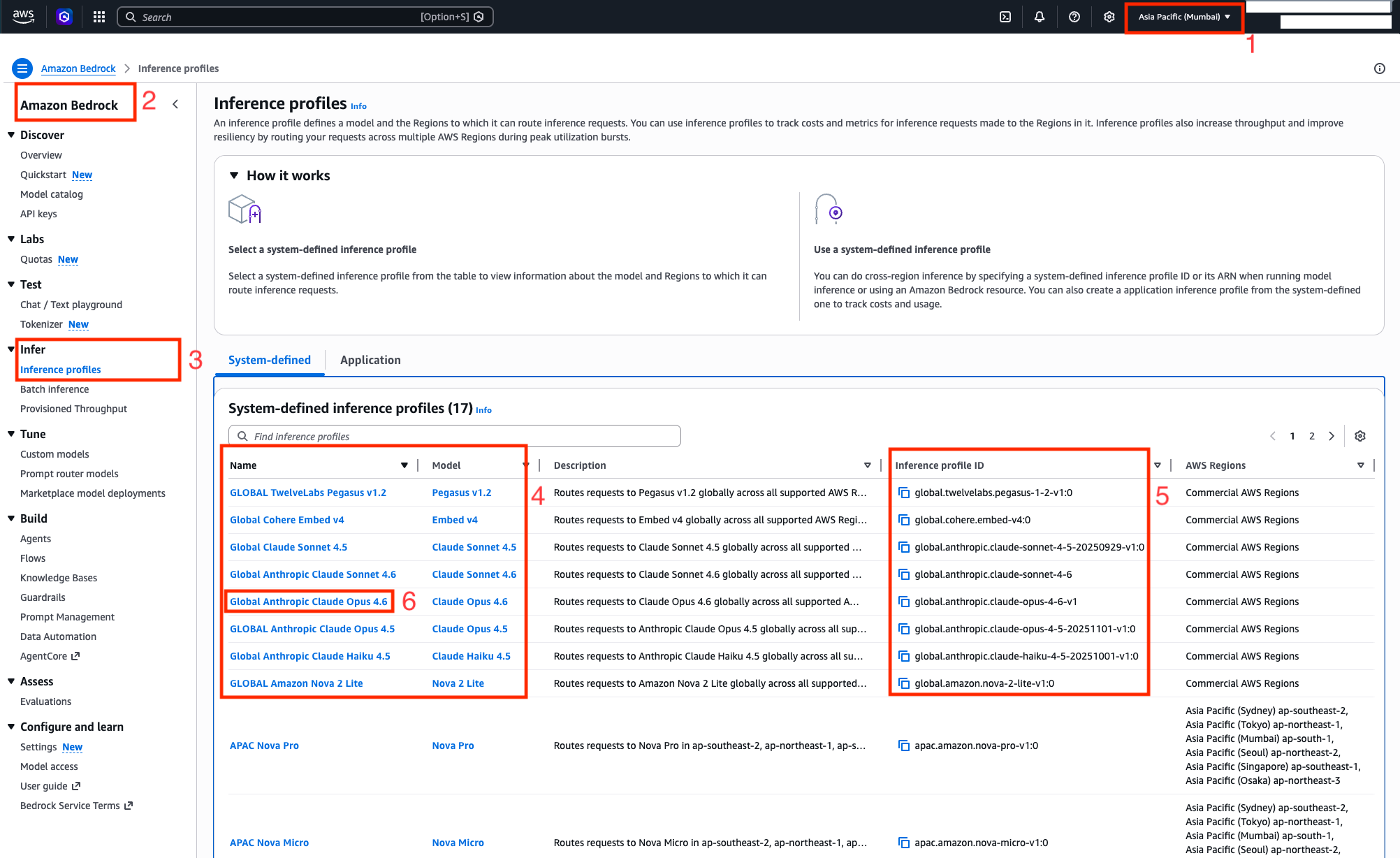
Access Anthropic Claude models in India on Amazon Bedrock with Global cross-Region inferenceArtificial Intelligence In this post, you will discover how to use Amazon Bedrock’s Global cross-Region Inference for Claude models in India. We will guide you through the capabilities of each Claude model variant and how to get started with a code example to help you start building generative AI applications immediately.
In this post, you will discover how to use Amazon Bedrock’s Global cross-Region Inference for Claude models in India. We will guide you through the capabilities of each Claude model variant and how to get started with a code example to help you start building generative AI applications immediately. Read More

Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning LoopsMarkTechPost In the frantic arms race of ‘AI for code,’ we’ve moved past the era of the glorified autocomplete. Today, Anthropic is double-downing on a more ambitious vision: the AI agent that doesn’t just write your boilerplate, but actually understands why your Kubernetes cluster is screaming at 3:00 AM. With the recent launch of Claude Code
The post Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning Loops appeared first on MarkTechPost.
In the frantic arms race of ‘AI for code,’ we’ve moved past the era of the glorified autocomplete. Today, Anthropic is double-downing on a more ambitious vision: the AI agent that doesn’t just write your boilerplate, but actually understands why your Kubernetes cluster is screaming at 3:00 AM. With the recent launch of Claude Code
The post Anthropic Introduces Code Review via Claude Code to Automate Complex Security Research Using Advanced Agentic Multi-Step Reasoning Loops appeared first on MarkTechPost. Read More
Three OpenClaw Mistakes to Avoid and How to Fix ThemTowards Data Science Learn how to set up OpenClaw effectively
The post Three OpenClaw Mistakes to Avoid and How to Fix Them appeared first on Towards Data Science.
Learn how to set up OpenClaw effectively
The post Three OpenClaw Mistakes to Avoid and How to Fix Them appeared first on Towards Data Science. Read More
City Union Bank launches AI centre to support banking operationsAI News Banks have spent years buying analytics tools and automation software. Now some are taking a different step: building internal spaces where AI can be tested directly on real banking problems. One example emerged in India this month. City Union Bank recently entered a four-party agreement to create a Centre of Excellence for Artificial Intelligence in
The post City Union Bank launches AI centre to support banking operations appeared first on AI News.
Banks have spent years buying analytics tools and automation software. Now some are taking a different step: building internal spaces where AI can be tested directly on real banking problems. One example emerged in India this month. City Union Bank recently entered a four-party agreement to create a Centre of Excellence for Artificial Intelligence in
The post City Union Bank launches AI centre to support banking operations appeared first on AI News. Read More
The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning MarkTechPost
The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM ReasoningMarkTechPost Large Language Models (LLMs) are the world’s best mimics, but when it comes to the cold, hard logic of updating beliefs based on new evidence, they are surprisingly stubborn. A team of researchers from Google argue that the current crop of AI agents falls far short of ‘probabilistic reasoning’—the ability to maintain and update a
The post The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning appeared first on MarkTechPost.
Large Language Models (LLMs) are the world’s best mimics, but when it comes to the cold, hard logic of updating beliefs based on new evidence, they are surprisingly stubborn. A team of researchers from Google argue that the current crop of AI agents falls far short of ‘probabilistic reasoning’—the ability to maintain and update a
The post The ‘Bayesian’ Upgrade: Why Google AI’s New Teaching Method is the Key to LLM Reasoning appeared first on MarkTechPost. Read More
Learning to Solve Orienteering Problem with Time Windows and Variable Profitscs.AI updates on arXiv.org arXiv:2603.06260v1 Announce Type: cross
Abstract: The orienteering problem with time windows and variable profits (OPTWVP) is common in many real-world applications and involves continuous time variables. Current approaches fail to develop an efficient solver for this orienteering problem variant with discrete and continuous variables. In this paper, we propose a learning-based two-stage DEcoupled discrete-Continuous optimization with Service-time-guided Trajectory (DeCoST), which aims to effectively decouple the discrete and continuous decision variables in the OPTWVP problem, while enabling efficient and learnable coordination between them. In the first stage, a parallel decoding structure is employed to predict the path and the initial service time allocation. The second stage optimizes the service times through a linear programming (LP) formulation and provides a long-horizon learning of structure estimation. We rigorously prove the global optimality of the second-stage solution. Experiments on OPTWVP instances demonstrate that DeCoST outperforms both state-of-the-art constructive solvers and the latest meta-heuristic algorithms in terms of solution quality and computational efficiency, achieving up to 6.6x inference speedup on instances with fewer than 500 nodes. Moreover, the proposed framework is compatible with various constructive solvers and consistently enhances the solution quality for OPTWVP.
arXiv:2603.06260v1 Announce Type: cross
Abstract: The orienteering problem with time windows and variable profits (OPTWVP) is common in many real-world applications and involves continuous time variables. Current approaches fail to develop an efficient solver for this orienteering problem variant with discrete and continuous variables. In this paper, we propose a learning-based two-stage DEcoupled discrete-Continuous optimization with Service-time-guided Trajectory (DeCoST), which aims to effectively decouple the discrete and continuous decision variables in the OPTWVP problem, while enabling efficient and learnable coordination between them. In the first stage, a parallel decoding structure is employed to predict the path and the initial service time allocation. The second stage optimizes the service times through a linear programming (LP) formulation and provides a long-horizon learning of structure estimation. We rigorously prove the global optimality of the second-stage solution. Experiments on OPTWVP instances demonstrate that DeCoST outperforms both state-of-the-art constructive solvers and the latest meta-heuristic algorithms in terms of solution quality and computational efficiency, achieving up to 6.6x inference speedup on instances with fewer than 500 nodes. Moreover, the proposed framework is compatible with various constructive solvers and consistently enhances the solution quality for OPTWVP. Read More
Structured Exploration vs. Generative Flexibility: A Field Study Comparing Bandit and LLM Architectures for Personalised Health Behaviour Interventionscs.AI updates on arXiv.org arXiv:2603.06330v1 Announce Type: cross
Abstract: Behaviour Change Techniques (BCTs) are central to digital health interventions, yet selecting and delivering effective techniques remains challenging. Contextual bandits enable statistically grounded optimisation of BCT selection, while Large Language Models (LLMs) offer flexible, context-sensitive message generation. We conducted a 4-week study on physical activity motivation (N=54; 9 post-study interviews) that compared five daily messaging approaches: random templates, contextual bandit with templates, LLM generation, hybrid bandit+LLM, and LLM with interaction history. LLM-based approaches were rated substantially more helpful than templates, but no significant differences emerged among LLM conditions. Unexpectedly, bandit optimisation for BCTs selection yielded no additional perceived helpfulness compared with LLM-only approaches. Unconstrained LLMs focused heavily on a single BCT, whereas bandit systems enforced systematic exploration-exploitation across techniques. Quantitative and qualitative findings suggest contextual acknowledgement of user input drove perceived helpfulness. We contribute design suggestions for reflective AI health behaviour change systems that address a trade-off between structured exploration and generative autonomy.
arXiv:2603.06330v1 Announce Type: cross
Abstract: Behaviour Change Techniques (BCTs) are central to digital health interventions, yet selecting and delivering effective techniques remains challenging. Contextual bandits enable statistically grounded optimisation of BCT selection, while Large Language Models (LLMs) offer flexible, context-sensitive message generation. We conducted a 4-week study on physical activity motivation (N=54; 9 post-study interviews) that compared five daily messaging approaches: random templates, contextual bandit with templates, LLM generation, hybrid bandit+LLM, and LLM with interaction history. LLM-based approaches were rated substantially more helpful than templates, but no significant differences emerged among LLM conditions. Unexpectedly, bandit optimisation for BCTs selection yielded no additional perceived helpfulness compared with LLM-only approaches. Unconstrained LLMs focused heavily on a single BCT, whereas bandit systems enforced systematic exploration-exploitation across techniques. Quantitative and qualitative findings suggest contextual acknowledgement of user input drove perceived helpfulness. We contribute design suggestions for reflective AI health behaviour change systems that address a trade-off between structured exploration and generative autonomy. Read More
The World Won’t Stay Still: Programmable Evolution for Agent Benchmarkscs.AI updates on arXiv.org arXiv:2603.05910v1 Announce Type: new
Abstract: LLM-powered agents fulfill user requests by interacting with environments, querying data, and invoking tools in a multi-turn process. Yet, most existing benchmarks assume static environments with fixed schemas and toolsets, neglecting the evolutionary nature of the real world and agents’ robustness to environmental changes. In this paper, we study a crucial problem: how to evolve the agent environment in a scalable and controllable way, thereby better evaluating agents’ adaptability to real-world dynamics. We propose ProEvolve, a graph-based framework that makes environment evolution programmable. At its core, a typed relational graph provides a unified, explicit representation of the environment: data, tools, and schema. Under this formalism, adding, removing, or modifying capabilities are expressed as graph transformations that coherently propagate updates across tools, schemas, and data access. Building on this, ProEvolve can (1) program the evolutionary dynamics as graph transformations to generate environments automatically, and (2) instantiate task sandboxes via subgraph sampling and programming. We validate ProEvolve by evolving a single environment into 200 environments and 3,000 task sandboxes, and benchmark representative agents accordingly.
arXiv:2603.05910v1 Announce Type: new
Abstract: LLM-powered agents fulfill user requests by interacting with environments, querying data, and invoking tools in a multi-turn process. Yet, most existing benchmarks assume static environments with fixed schemas and toolsets, neglecting the evolutionary nature of the real world and agents’ robustness to environmental changes. In this paper, we study a crucial problem: how to evolve the agent environment in a scalable and controllable way, thereby better evaluating agents’ adaptability to real-world dynamics. We propose ProEvolve, a graph-based framework that makes environment evolution programmable. At its core, a typed relational graph provides a unified, explicit representation of the environment: data, tools, and schema. Under this formalism, adding, removing, or modifying capabilities are expressed as graph transformations that coherently propagate updates across tools, schemas, and data access. Building on this, ProEvolve can (1) program the evolutionary dynamics as graph transformations to generate environments automatically, and (2) instantiate task sandboxes via subgraph sampling and programming. We validate ProEvolve by evolving a single environment into 200 environments and 3,000 task sandboxes, and benchmark representative agents accordingly. Read More
Addressing the Ecological Fallacy in Larger LMs with Human Contextcs.AI updates on arXiv.org arXiv:2603.05928v1 Announce Type: cross
Abstract: Language model training and inference ignore a fundamental linguistic fact — there is a dependence between multiple sequences of text written by the same person. Prior work has shown that addressing this form of textit{ecological fallacy} can greatly improve the performance of multiple smaller (~124M) GPT-based models. In this work, we ask if addressing the ecological fallacy by modeling the author’s language context with a specific LM task (called HuLM) can provide similar benefits for a larger-scale model, an 8B Llama model. To this end, we explore variants that process an author’s language in the context of their other temporally ordered texts. We study the effect of pre-training with this author context using the HuLM objective, as well as using it during fine-tuning with author context (textit{HuFT:Human-aware Fine-Tuning}). Empirical comparisons show that addressing the ecological fallacy during fine-tuning alone using QLoRA improves the performance of the larger 8B model over standard fine-tuning. Additionally, QLoRA-based continued HuLM pre-training results in a human-aware model generalizable for improved performance over eight downstream tasks with linear task classifier training alone. These results indicate the utility and importance of modeling language in the context of its original generators, the authors.
arXiv:2603.05928v1 Announce Type: cross
Abstract: Language model training and inference ignore a fundamental linguistic fact — there is a dependence between multiple sequences of text written by the same person. Prior work has shown that addressing this form of textit{ecological fallacy} can greatly improve the performance of multiple smaller (~124M) GPT-based models. In this work, we ask if addressing the ecological fallacy by modeling the author’s language context with a specific LM task (called HuLM) can provide similar benefits for a larger-scale model, an 8B Llama model. To this end, we explore variants that process an author’s language in the context of their other temporally ordered texts. We study the effect of pre-training with this author context using the HuLM objective, as well as using it during fine-tuning with author context (textit{HuFT:Human-aware Fine-Tuning}). Empirical comparisons show that addressing the ecological fallacy during fine-tuning alone using QLoRA improves the performance of the larger 8B model over standard fine-tuning. Additionally, QLoRA-based continued HuLM pre-training results in a human-aware model generalizable for improved performance over eight downstream tasks with linear task classifier training alone. These results indicate the utility and importance of modeling language in the context of its original generators, the authors. Read More