
Goldman Sachs deploys Anthropic systems with successAI News Goldman Sachs plans to deploy Anthropic’s Claude model in trade accounting and client onboarding, and, according to an article in American Banker, presents this as part of a broader push among large banks to use generative artificial intelligence to improve efficiency. The focus is on operational processes that sit in the back office and have
The post Goldman Sachs deploys Anthropic systems with success appeared first on AI News.
Goldman Sachs plans to deploy Anthropic’s Claude model in trade accounting and client onboarding, and, according to an article in American Banker, presents this as part of a broader push among large banks to use generative artificial intelligence to improve efficiency. The focus is on operational processes that sit in the back office and have
The post Goldman Sachs deploys Anthropic systems with success appeared first on AI News. Read More

Beyond Static Snapshots: Dynamic Modeling and Forecasting of Group-Level Value Evolution with Large Language Modelscs.AI updates on arXiv.org arXiv:2602.14043v1 Announce Type: cross
Abstract: Social simulation is critical for mining complex social dynamics and supporting data-driven decision making. LLM-based methods have emerged as powerful tools for this task by leveraging human-like social questionnaire responses to model group behaviors. Existing LLM-based approaches predominantly focus on group-level values at discrete time points, treating them as static snapshots rather than dynamic processes. However, group-level values are not fixed but shaped by long-term social changes. Modeling their dynamics is thus crucial for accurate social evolution prediction–a key challenge in both data mining and social science. This problem remains underexplored due to limited longitudinal data, group heterogeneity, and intricate historical event impacts.
To bridge this gap, we propose a novel framework for group-level dynamic social simulation by integrating historical value trajectories into LLM-based human response modeling. We select China and the U.S. as representative contexts, conducting stratified simulations across four core sociodemographic dimensions (gender, age, education, income). Using the World Values Survey, we construct a multi-wave, group-level longitudinal dataset to capture historical value evolution, and then propose the first event-based prediction method for this task, unifying social events, current value states, and group attributes into a single framework. Evaluations across five LLM families show substantial gains: a maximum 30.88% improvement on seen questions and 33.97% on unseen questions over the Vanilla baseline. We further find notable cross-group heterogeneity: U.S. groups are more volatile than Chinese groups, and younger groups in both countries are more sensitive to external changes. These findings advance LLM-based social simulation and provide new insights for social scientists to understand and predict social value changes.
arXiv:2602.14043v1 Announce Type: cross
Abstract: Social simulation is critical for mining complex social dynamics and supporting data-driven decision making. LLM-based methods have emerged as powerful tools for this task by leveraging human-like social questionnaire responses to model group behaviors. Existing LLM-based approaches predominantly focus on group-level values at discrete time points, treating them as static snapshots rather than dynamic processes. However, group-level values are not fixed but shaped by long-term social changes. Modeling their dynamics is thus crucial for accurate social evolution prediction–a key challenge in both data mining and social science. This problem remains underexplored due to limited longitudinal data, group heterogeneity, and intricate historical event impacts.
To bridge this gap, we propose a novel framework for group-level dynamic social simulation by integrating historical value trajectories into LLM-based human response modeling. We select China and the U.S. as representative contexts, conducting stratified simulations across four core sociodemographic dimensions (gender, age, education, income). Using the World Values Survey, we construct a multi-wave, group-level longitudinal dataset to capture historical value evolution, and then propose the first event-based prediction method for this task, unifying social events, current value states, and group attributes into a single framework. Evaluations across five LLM families show substantial gains: a maximum 30.88% improvement on seen questions and 33.97% on unseen questions over the Vanilla baseline. We further find notable cross-group heterogeneity: U.S. groups are more volatile than Chinese groups, and younger groups in both countries are more sensitive to external changes. These findings advance LLM-based social simulation and provide new insights for social scientists to understand and predict social value changes. Read More
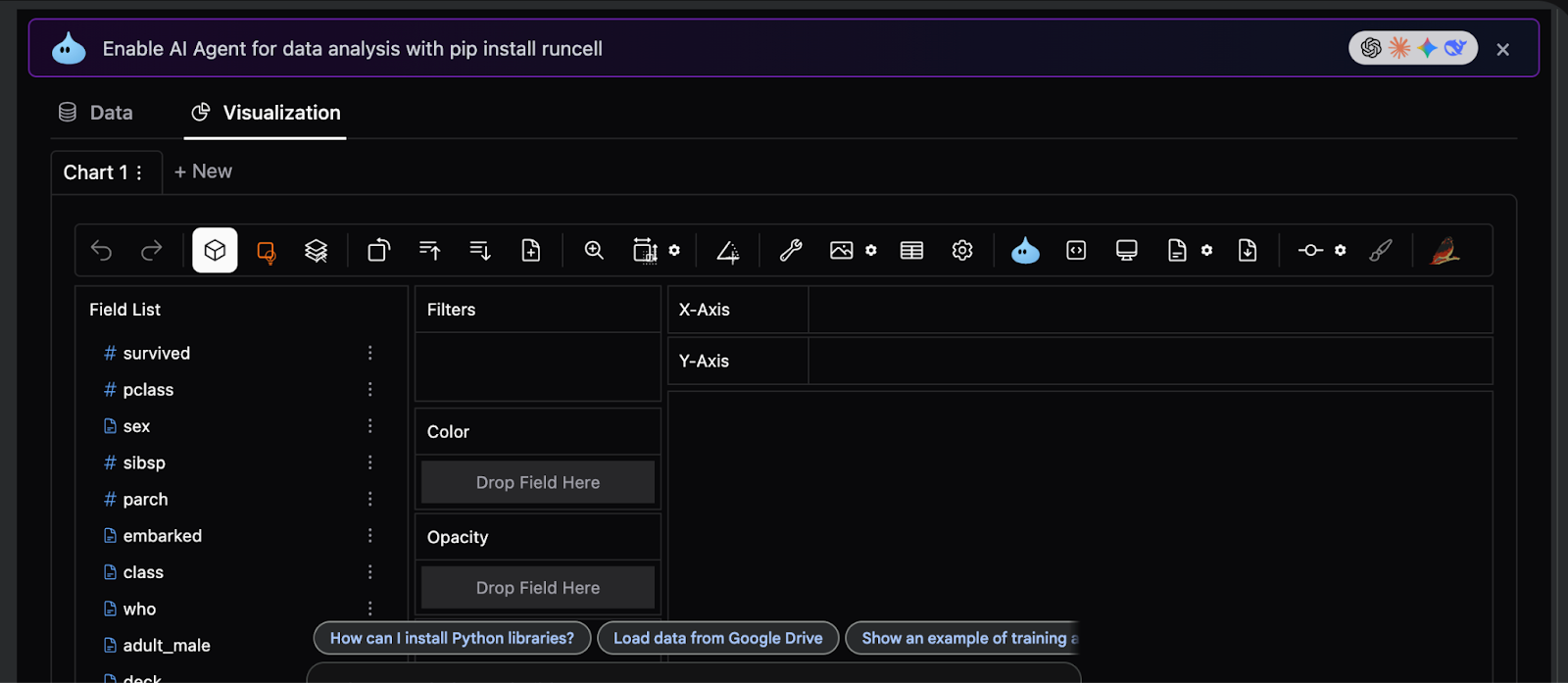
How to Build an Advanced, Interactive Exploratory Data Analysis Workflow Using PyGWalker and Feature-Engineered DataMarkTechPost In this tutorial, we demonstrate how to move beyond static, code-heavy charts and build a genuinely interactive exploratory data analysis workflow directly using PyGWalker. We start by preparing the Titanic dataset for large-scale interactive querying. These analysis-ready engineered features reveal the underlying structure of the data while enabling both detailed row-level exploration and high-level aggregated
The post How to Build an Advanced, Interactive Exploratory Data Analysis Workflow Using PyGWalker and Feature-Engineered Data appeared first on MarkTechPost.
In this tutorial, we demonstrate how to move beyond static, code-heavy charts and build a genuinely interactive exploratory data analysis workflow directly using PyGWalker. We start by preparing the Titanic dataset for large-scale interactive querying. These analysis-ready engineered features reveal the underlying structure of the data while enabling both detailed row-level exploration and high-level aggregated
The post How to Build an Advanced, Interactive Exploratory Data Analysis Workflow Using PyGWalker and Feature-Engineered Data appeared first on MarkTechPost. Read More
Cloudflare Releases Agents SDK v0.5.0 with Rewritten @cloudflare/ai-chat and New Rust-Powered Infire Engine for Optimized Edge Inference PerformanceMarkTechPost Cloudflare has released the Agents SDK v0.5.0 to address the limitations of stateless serverless functions in AI development. In standard serverless architectures, every LLM call requires rebuilding the session context from scratch, which increases latency and token consumption. The Agents SDK’s latest version (Agents SDK v0.5.0) provides a vertically integrated execution layer where compute, state,
The post Cloudflare Releases Agents SDK v0.5.0 with Rewritten @cloudflare/ai-chat and New Rust-Powered Infire Engine for Optimized Edge Inference Performance appeared first on MarkTechPost.
Cloudflare has released the Agents SDK v0.5.0 to address the limitations of stateless serverless functions in AI development. In standard serverless architectures, every LLM call requires rebuilding the session context from scratch, which increases latency and token consumption. The Agents SDK’s latest version (Agents SDK v0.5.0) provides a vertically integrated execution layer where compute, state,
The post Cloudflare Releases Agents SDK v0.5.0 with Rewritten @cloudflare/ai-chat and New Rust-Powered Infire Engine for Optimized Edge Inference Performance appeared first on MarkTechPost. Read More
Iron Triangles: Powerful Tools for Analyzing Trade-Offs in AI Product DevelopmentTowards Data Science Conceptual overview and practical guidance
The post Iron Triangles: Powerful Tools for Analyzing Trade-Offs in AI Product Development appeared first on Towards Data Science.
Conceptual overview and practical guidance
The post Iron Triangles: Powerful Tools for Analyzing Trade-Offs in AI Product Development appeared first on Towards Data Science. Read More

Table of Contents TJS Weekly Security Intelligence Briefing – Week of Feb 16th 1. Executive Summary 2. Critical Action Items 3. Key Security Stories Story 1: Ivanti EPMM Zero-Days Under Mass Exploitation – European Government Agencies Compromised Story 2: Microsoft February 2026 Patch Tuesday – Six Actively Exploited Zero-Days Story 3: BeyondTrust Pre-Auth RCE – […]
End-to-End NOMA with Perfect and Quantized CSI Over Rayleigh Fading Channels AI updates on arXiv.org
End-to-End NOMA with Perfect and Quantized CSI Over Rayleigh Fading Channelscs.AI updates on arXiv.org arXiv:2602.13446v1 Announce Type: cross
Abstract: An end-to-end autoencoder (AE) framework is developed for downlink non-orthogonal multiple access (NOMA) over Rayleigh fading channels, which learns interference-aware and channel-adaptive super-constellations. While existing works either assume additive white Gaussian noise channels or treat fading channels without a fully end-to-end learning approach, our framework directly embeds the wireless channel into both training and inference. To account for practical channel state information (CSI), we further incorporate limited feedback via both uniform and Lloyd-Max quantization of channel gains and analyze their impact on AE training and bit error rate (BER) performance. Simulation results show that, with perfect CSI, the proposed AE outperforms the existing analytical NOMA schemes. In addition, Lloyd-Max quantization achieves superior BER performance compared to uniform quantization. These results demonstrate that end-to-end AEs trained directly over Rayleigh fading can effectively learn robust, interference-aware signaling strategies, paving the way for NOMA deployment in fading environments with realistic CSI constraints.
arXiv:2602.13446v1 Announce Type: cross
Abstract: An end-to-end autoencoder (AE) framework is developed for downlink non-orthogonal multiple access (NOMA) over Rayleigh fading channels, which learns interference-aware and channel-adaptive super-constellations. While existing works either assume additive white Gaussian noise channels or treat fading channels without a fully end-to-end learning approach, our framework directly embeds the wireless channel into both training and inference. To account for practical channel state information (CSI), we further incorporate limited feedback via both uniform and Lloyd-Max quantization of channel gains and analyze their impact on AE training and bit error rate (BER) performance. Simulation results show that, with perfect CSI, the proposed AE outperforms the existing analytical NOMA schemes. In addition, Lloyd-Max quantization achieves superior BER performance compared to uniform quantization. These results demonstrate that end-to-end AEs trained directly over Rayleigh fading can effectively learn robust, interference-aware signaling strategies, paving the way for NOMA deployment in fading environments with realistic CSI constraints. Read More
The Sufficiency-Conciseness Trade-off in LLM Self-Explanation from an Information Bottleneck Perspectivecs.AI updates on arXiv.org arXiv:2602.14002v1 Announce Type: cross
Abstract: Large Language Models increasingly rely on self-explanations, such as chain of thought reasoning, to improve performance on multi step question answering. While these explanations enhance accuracy, they are often verbose and costly to generate, raising the question of how much explanation is truly necessary. In this paper, we examine the trade-off between sufficiency, defined as the ability of an explanation to justify the correct answer, and conciseness, defined as the reduction in explanation length. Building on the information bottleneck principle, we conceptualize explanations as compressed representations that retain only the information essential for producing correct answers.To operationalize this view, we introduce an evaluation pipeline that constrains explanation length and assesses sufficiency using multiple language models on the ARC Challenge dataset. To broaden the scope, we conduct experiments in both English, using the original dataset, and Persian, as a resource-limited language through translation. Our experiments show that more concise explanations often remain sufficient, preserving accuracy while substantially reducing explanation length, whereas excessive compression leads to performance degradation.
arXiv:2602.14002v1 Announce Type: cross
Abstract: Large Language Models increasingly rely on self-explanations, such as chain of thought reasoning, to improve performance on multi step question answering. While these explanations enhance accuracy, they are often verbose and costly to generate, raising the question of how much explanation is truly necessary. In this paper, we examine the trade-off between sufficiency, defined as the ability of an explanation to justify the correct answer, and conciseness, defined as the reduction in explanation length. Building on the information bottleneck principle, we conceptualize explanations as compressed representations that retain only the information essential for producing correct answers.To operationalize this view, we introduce an evaluation pipeline that constrains explanation length and assesses sufficiency using multiple language models on the ARC Challenge dataset. To broaden the scope, we conduct experiments in both English, using the original dataset, and Persian, as a resource-limited language through translation. Our experiments show that more concise explanations often remain sufficient, preserving accuracy while substantially reducing explanation length, whereas excessive compression leads to performance degradation. Read More
What happens when reviewers receive AI feedback in their reviews?cs.AI updates on arXiv.org arXiv:2602.13817v1 Announce Type: cross
Abstract: AI is reshaping academic research, yet its role in peer review remains polarising and contentious. Advocates see its potential to reduce reviewer burden and improve quality, while critics warn of risks to fairness, accountability, and trust. At ICLR 2025, an official AI feedback tool was deployed to provide reviewers with post-review suggestions. We studied this deployment through surveys and interviews, investigating how reviewers engaged with the tool and perceived its usability and impact. Our findings surface both opportunities and tensions when AI augments in peer review. This work contributes the first empirical evidence of such an AI tool in a live review process, documenting how reviewers respond to AI-generated feedback in a high-stakes review context. We further offer design implications for AI-assisted reviewing that aim to enhance quality while safeguarding human expertise, agency, and responsibility.
arXiv:2602.13817v1 Announce Type: cross
Abstract: AI is reshaping academic research, yet its role in peer review remains polarising and contentious. Advocates see its potential to reduce reviewer burden and improve quality, while critics warn of risks to fairness, accountability, and trust. At ICLR 2025, an official AI feedback tool was deployed to provide reviewers with post-review suggestions. We studied this deployment through surveys and interviews, investigating how reviewers engaged with the tool and perceived its usability and impact. Our findings surface both opportunities and tensions when AI augments in peer review. This work contributes the first empirical evidence of such an AI tool in a live review process, documenting how reviewers respond to AI-generated feedback in a high-stakes review context. We further offer design implications for AI-assisted reviewing that aim to enhance quality while safeguarding human expertise, agency, and responsibility. Read More
Agoda Open Sources APIAgent to Convert Any REST pr GraphQL API into an MCP Server with Zero CodeMarkTechPost Building AI agents is the new gold rush. But every developer knows the biggest bottleneck: getting the AI to actually communicate to your data. Today, travel giant Agoda is tackling this problem head-on. They have officially launched APIAgent, an open-source tool designed to turn any REST or GraphQL API into a Model Context Protocol (MCP)
The post Agoda Open Sources APIAgent to Convert Any REST pr GraphQL API into an MCP Server with Zero Code appeared first on MarkTechPost.
Building AI agents is the new gold rush. But every developer knows the biggest bottleneck: getting the AI to actually communicate to your data. Today, travel giant Agoda is tackling this problem head-on. They have officially launched APIAgent, an open-source tool designed to turn any REST or GraphQL API into a Model Context Protocol (MCP)
The post Agoda Open Sources APIAgent to Convert Any REST pr GraphQL API into an MCP Server with Zero Code appeared first on MarkTechPost. Read More