

Identifying Trustworthiness Challenges in Deep Learning Models for Continental-Scale Water Quality Predictioncs.AI updates on arXiv.org arXiv:2503.09947v3 Announce Type: replace-cross
Abstract: Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning offers transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes operational decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges, including performance disparity, robustness, uncertainty, interpretability, generalizability, and reproducibility. In this work, we present a multi-dimensional, quantitative evaluation of trustworthiness benchmarking three state-of-the-art deep learning architectures: recurrent (LSTM), operator-learning (DeepONet), and transformer-based (Informer), trained on 37 years of data from 482 U.S. basins to predict 20 water quality variables. Our investigation reveals systematic performance disparities tied to process complexity, data availability, and basin heterogeneity. Management-critical variables remain the least predictable and most uncertain. Robustness tests reveal pronounced sensitivity to outliers and corrupted targets; notably, the architecture with the strongest baseline performance (LSTM) proves most vulnerable under data corruption. Attribution analyses align for simple variables but diverge for nutrients, underscoring the need for multi-method interpretability. Spatial generalization to ungauged basins remains poor across all models. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management.
arXiv:2503.09947v3 Announce Type: replace-cross
Abstract: Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning offers transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes operational decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges, including performance disparity, robustness, uncertainty, interpretability, generalizability, and reproducibility. In this work, we present a multi-dimensional, quantitative evaluation of trustworthiness benchmarking three state-of-the-art deep learning architectures: recurrent (LSTM), operator-learning (DeepONet), and transformer-based (Informer), trained on 37 years of data from 482 U.S. basins to predict 20 water quality variables. Our investigation reveals systematic performance disparities tied to process complexity, data availability, and basin heterogeneity. Management-critical variables remain the least predictable and most uncertain. Robustness tests reveal pronounced sensitivity to outliers and corrupted targets; notably, the architecture with the strongest baseline performance (LSTM) proves most vulnerable under data corruption. Attribution analyses align for simple variables but diverge for nutrients, underscoring the need for multi-method interpretability. Spatial generalization to ungauged basins remains poor across all models. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management. Read More
Computational Hardness of Reinforcement Learning with Partial $q^{pi}$-Realizabilitycs.AI updates on arXiv.org arXiv:2510.21888v1 Announce Type: new
Abstract: This paper investigates the computational complexity of reinforcement learning in a novel linear function approximation regime, termed partial $q^{pi}$-realizability. In this framework, the objective is to learn an $epsilon$-optimal policy with respect to a predefined policy set $Pi$, under the assumption that all value functions for policies in $Pi$ are linearly realizable. The assumptions of this framework are weaker than those in $q^{pi}$-realizability but stronger than those in $q^*$-realizability, providing a practical model where function approximation naturally arises. We prove that learning an $epsilon$-optimal policy in this setting is computationally hard. Specifically, we establish NP-hardness under a parameterized greedy policy set (argmax) and show that – unless NP = RP – an exponential lower bound (in feature vector dimension) holds when the policy set contains softmax policies, under the Randomized Exponential Time Hypothesis. Our hardness results mirror those in $q^*$-realizability and suggest computational difficulty persists even when $Pi$ is expanded beyond the optimal policy. To establish this, we reduce from two complexity problems, $delta$-Max-3SAT and $delta$-Max-3SAT(b), to instances of GLinear-$kappa$-RL (greedy policy) and SLinear-$kappa$-RL (softmax policy). Our findings indicate that positive computational results are generally unattainable in partial $q^{pi}$-realizability, in contrast to $q^{pi}$-realizability under a generative access model.
arXiv:2510.21888v1 Announce Type: new
Abstract: This paper investigates the computational complexity of reinforcement learning in a novel linear function approximation regime, termed partial $q^{pi}$-realizability. In this framework, the objective is to learn an $epsilon$-optimal policy with respect to a predefined policy set $Pi$, under the assumption that all value functions for policies in $Pi$ are linearly realizable. The assumptions of this framework are weaker than those in $q^{pi}$-realizability but stronger than those in $q^*$-realizability, providing a practical model where function approximation naturally arises. We prove that learning an $epsilon$-optimal policy in this setting is computationally hard. Specifically, we establish NP-hardness under a parameterized greedy policy set (argmax) and show that – unless NP = RP – an exponential lower bound (in feature vector dimension) holds when the policy set contains softmax policies, under the Randomized Exponential Time Hypothesis. Our hardness results mirror those in $q^*$-realizability and suggest computational difficulty persists even when $Pi$ is expanded beyond the optimal policy. To establish this, we reduce from two complexity problems, $delta$-Max-3SAT and $delta$-Max-3SAT(b), to instances of GLinear-$kappa$-RL (greedy policy) and SLinear-$kappa$-RL (softmax policy). Our findings indicate that positive computational results are generally unattainable in partial $q^{pi}$-realizability, in contrast to $q^{pi}$-realizability under a generative access model. Read More
Accelerating Eigenvalue Dataset Generation via Chebyshev Subspace Filtercs.AI updates on arXiv.org arXiv:2510.23215v1 Announce Type: cross
Abstract: Eigenvalue problems are among the most important topics in many scientific disciplines. With the recent surge and development of machine learning, neural eigenvalue methods have attracted significant attention as a forward pass of inference requires only a tiny fraction of the computation time compared to traditional solvers. However, a key limitation is the requirement for large amounts of labeled data in training, including operators and their eigenvalues. To tackle this limitation, we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators — a factor overlooked by existing methods. Specifically, SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations. To the best of our knowledge, SCSF is the first method to accelerate eigenvalue data generation. Experimental results show that SCSF achieves up to a $3.5times$ speedup compared to various numerical solvers.
arXiv:2510.23215v1 Announce Type: cross
Abstract: Eigenvalue problems are among the most important topics in many scientific disciplines. With the recent surge and development of machine learning, neural eigenvalue methods have attracted significant attention as a forward pass of inference requires only a tiny fraction of the computation time compared to traditional solvers. However, a key limitation is the requirement for large amounts of labeled data in training, including operators and their eigenvalues. To tackle this limitation, we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators — a factor overlooked by existing methods. Specifically, SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations. To the best of our knowledge, SCSF is the first method to accelerate eigenvalue data generation. Experimental results show that SCSF achieves up to a $3.5times$ speedup compared to various numerical solvers. Read More
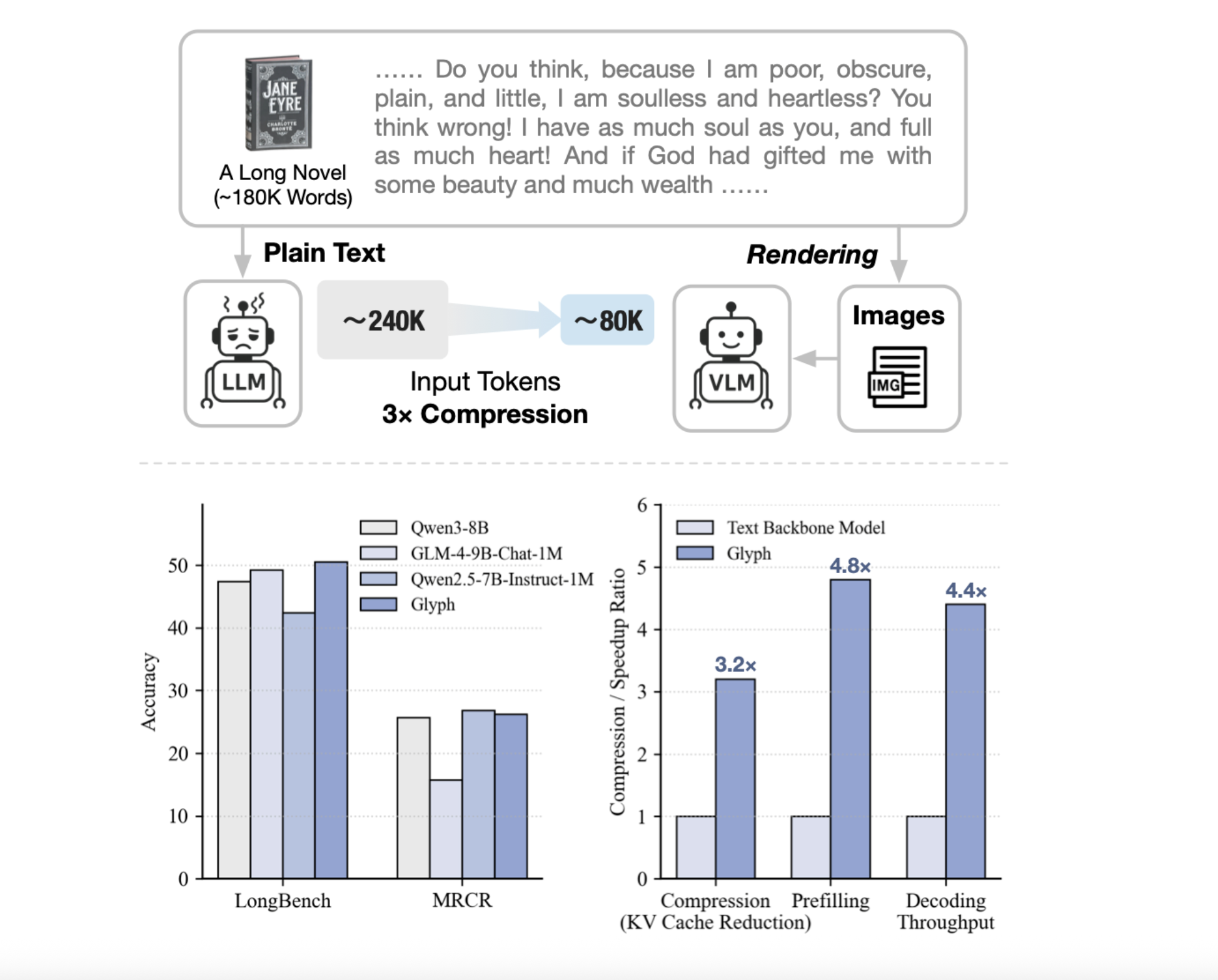
Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text CompressionMarkTechPost Can we render long texts as images and use a VLM to achieve 3–4× token compression, preserving accuracy while scaling a 128K context toward 1M-token workloads? A team of researchers from Zhipu AI release Glyph, an AI framework for scaling the context length through visual-text compression. It renders long textual sequences into images and processes
The post Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression appeared first on MarkTechPost.
Can we render long texts as images and use a VLM to achieve 3–4× token compression, preserving accuracy while scaling a 128K context toward 1M-token workloads? A team of researchers from Zhipu AI release Glyph, an AI framework for scaling the context length through visual-text compression. It renders long textual sequences into images and processes
The post Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression appeared first on MarkTechPost. Read More
FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Finance AI updates on arXiv.org
FAITH: A Framework for Assessing Intrinsic Tabular Hallucinations in Financecs.AI updates on arXiv.org arXiv:2508.05201v2 Announce Type: replace-cross
Abstract: Hallucination remains a critical challenge for deploying Large Language Models (LLMs) in finance. Accurate extraction and precise calculation from tabular data are essential for reliable financial analysis, since even minor numerical errors can undermine decision-making and regulatory compliance. Financial applications have unique requirements, often relying on context-dependent, numerical, and proprietary tabular data that existing hallucination benchmarks rarely capture. In this study, we develop a rigorous and scalable framework for evaluating intrinsic hallucinations in financial LLMs, conceptualized as a context-aware masked span prediction task over real-world financial documents. Our main contributions are: (1) a novel, automated dataset creation paradigm using a masking strategy; (2) a new hallucination evaluation dataset derived from S&P 500 annual reports; and (3) a comprehensive evaluation of intrinsic hallucination patterns in state-of-the-art LLMs on financial tabular data. Our work provides a robust methodology for in-house LLM evaluation and serves as a critical step toward building more trustworthy and reliable financial Generative AI systems.
arXiv:2508.05201v2 Announce Type: replace-cross
Abstract: Hallucination remains a critical challenge for deploying Large Language Models (LLMs) in finance. Accurate extraction and precise calculation from tabular data are essential for reliable financial analysis, since even minor numerical errors can undermine decision-making and regulatory compliance. Financial applications have unique requirements, often relying on context-dependent, numerical, and proprietary tabular data that existing hallucination benchmarks rarely capture. In this study, we develop a rigorous and scalable framework for evaluating intrinsic hallucinations in financial LLMs, conceptualized as a context-aware masked span prediction task over real-world financial documents. Our main contributions are: (1) a novel, automated dataset creation paradigm using a masking strategy; (2) a new hallucination evaluation dataset derived from S&P 500 annual reports; and (3) a comprehensive evaluation of intrinsic hallucination patterns in state-of-the-art LLMs on financial tabular data. Our work provides a robust methodology for in-house LLM evaluation and serves as a critical step toward building more trustworthy and reliable financial Generative AI systems. Read More
Seizing the AI opportunityOpenAI News Meeting the demands of the Intelligence Age will require strategic investment in energy and infrastructure. OpenAI’s submission to the White House details how expanding capacity and workforce readiness can sustain U.S. leadership in AI and economic growth.
Meeting the demands of the Intelligence Age will require strategic investment in energy and infrastructure. OpenAI’s submission to the White House details how expanding capacity and workforce readiness can sustain U.S. leadership in AI and economic growth. Read More

Agentic AI Coding with Google JulesKDnuggets Google Jules is not a chat assistant that lives in your IDE; it’s a fully asynchronous coding agent.
Google Jules is not a chat assistant that lives in your IDE; it’s a fully asynchronous coding agent. Read More
The Machine Learning Lessons I’ve Learned This MonthTowards Data Science October 2025: READMEs, MIGs, and movements
The post The Machine Learning Lessons I’ve Learned This Month appeared first on Towards Data Science.
October 2025: READMEs, MIGs, and movements
The post The Machine Learning Lessons I’ve Learned This Month appeared first on Towards Data Science. Read More
How to Apply Powerful AI Audio Models to Real-World ApplicationsTowards Data Science Learn about different types of AI audio models and the application areas they can be used in.
The post How to Apply Powerful AI Audio Models to Real-World Applications appeared first on Towards Data Science.
Learn about different types of AI audio models and the application areas they can be used in.
The post How to Apply Powerful AI Audio Models to Real-World Applications appeared first on Towards Data Science. Read More
Epistemic Deference to AIcs.AI updates on arXiv.org arXiv:2510.21043v1 Announce Type: new
Abstract: When should we defer to AI outputs over human expert judgment? Drawing on recent work in social epistemology, I motivate the idea that some AI systems qualify as Artificial Epistemic Authorities (AEAs) due to their demonstrated reliability and epistemic superiority. I then introduce AI Preemptionism, the view that AEA outputs should replace rather than supplement a user’s independent epistemic reasons. I show that classic objections to preemptionism – such as uncritical deference, epistemic entrenchment, and unhinging epistemic bases – apply in amplified form to AEAs, given their opacity, self-reinforcing authority, and lack of epistemic failure markers. Against this, I develop a more promising alternative: a total evidence view of AI deference. According to this view, AEA outputs should function as contributory reasons rather than outright replacements for a user’s independent epistemic considerations. This approach has three key advantages: (i) it mitigates expertise atrophy by keeping human users engaged, (ii) it provides an epistemic case for meaningful human oversight and control, and (iii) it explains the justified mistrust of AI when reliability conditions are unmet. While demanding in practice, this account offers a principled way to determine when AI deference is justified, particularly in high-stakes contexts requiring rigorous reliability.
arXiv:2510.21043v1 Announce Type: new
Abstract: When should we defer to AI outputs over human expert judgment? Drawing on recent work in social epistemology, I motivate the idea that some AI systems qualify as Artificial Epistemic Authorities (AEAs) due to their demonstrated reliability and epistemic superiority. I then introduce AI Preemptionism, the view that AEA outputs should replace rather than supplement a user’s independent epistemic reasons. I show that classic objections to preemptionism – such as uncritical deference, epistemic entrenchment, and unhinging epistemic bases – apply in amplified form to AEAs, given their opacity, self-reinforcing authority, and lack of epistemic failure markers. Against this, I develop a more promising alternative: a total evidence view of AI deference. According to this view, AEA outputs should function as contributory reasons rather than outright replacements for a user’s independent epistemic considerations. This approach has three key advantages: (i) it mitigates expertise atrophy by keeping human users engaged, (ii) it provides an epistemic case for meaningful human oversight and control, and (iii) it explains the justified mistrust of AI when reliability conditions are unmet. While demanding in practice, this account offers a principled way to determine when AI deference is justified, particularly in high-stakes contexts requiring rigorous reliability. Read More
