
Prototyping Gradient Descent in Machine LearningTowards Data Scienceon May 24, 2025 at 1:12 am Mathematical theorem and credit transaction prediction using Stochastic / Batch GD
The post Prototyping Gradient Descent in Machine Learning appeared first on Towards Data Science.
Mathematical theorem and credit transaction prediction using Stochastic / Batch GD
The post Prototyping Gradient Descent in Machine Learning appeared first on Towards Data Science. Read More

Part of the AI Governance Career Hub This guide is one piece of a 20-role interactive ecosystem with verified salary data, skills assessments, and market intelligence. Start with the tool that fits where you are right now. Career Evaluator Personalized role match in 90 sec Roles & Career Paths Explore all 20 positions Career Hub […]

What is Identity and Access Management? Identity and Access Management (IAM) sits at the heart of modern cybersecurity strategies and business operations. But what exactly is IAM, and why is it so vital? At its core, IAM is the framework of policies, technologies, and processes that ensure the right people (or systems) have access to […]

The Thing That Keeps You up at Night It’s 2:47 AM, and the first signs of trouble start to surface. Unusual network traffic begins streaming from your financial database server, but no one is there to catch the alerts. At this moment, a sophisticated ransomware attack is quietly taking hold of your organization’s network. What […]

Introducing The 7-Stage AI Lifecycle Framework Artificial intelligence has rocketed from a speculative venture to business reality. But as organizations rush to implement new models and automate processes, plenty of well-intentioned AI projects stall out, plagued by governance blind spots, regulatory surprises, or plain old miscommunication between business, technical, and legal teams. The pressure is […]

Take Your Entry-Level Security Role Hunt to The Next Level Are you curious about how to break into information security? Maybe you love solving puzzles, enjoy learning how things work, or want a career that puts you at the forefront of defending organizations? Maybe you just want to maintain and increase your pay in a […]
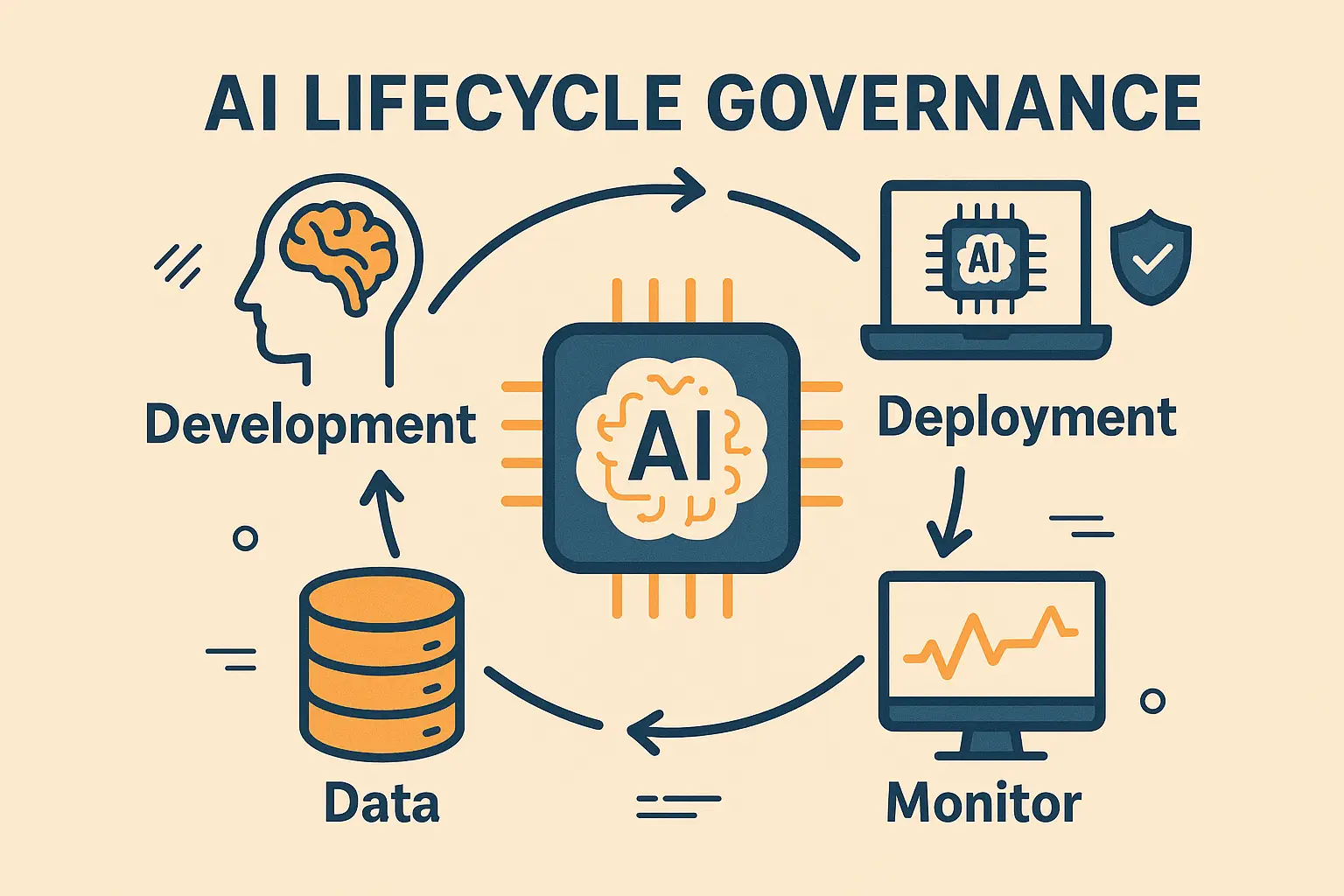
Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CSSPLast updated May 13th, 2025 AI Lifecycle Governance – Milestone 1 of 13: Objectives & Problem Definition So, let’s get into it. AI governance can feel daunting. Trust me, I know. As AI works its way into the vast majority […]

Introduction A data breach doesn’t care if you’re a startup or a Fortune 100. Over the past decade, I’ve seen teams scramble to contain ransomware at midnight, and others calmly execute playbooks as if rehearsed for Broadway. What sets these worlds apart often boils down to one thing: Are your incident response (IR) efforts aligned […]

UNDERSTANDING AI BIAS As organizations increasingly rely on Artificial Intelligence (AI) across sectors such as healthcare, hiring, finance, and public safety, understanding and mitigating embedded biases (AI bias) within these systems is vital. Left unaddressed, these biases pose significant threats, including exacerbating systemic discrimination, creating ethical and legal challenges, eroding public trust, and negatively impacting […]

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated: August,28th 2025 Pressed For Time Review or Download our 2-3 min Quick Slides or the 5-7 min Article Insights to gain knowledge with the time you have! Review or Download our 2-3 min Quick Slides or the 5-7 min Article Insights to gain knowledge with the time you have! AI Acceptable Use Policies: […]