
5 NotebookLM Tips to Make Your Day a Little EasierKDnuggets Here are five quality tips for using NotebookLM to make a data scientist’s day a little easier.
Here are five quality tips for using NotebookLM to make a data scientist’s day a little easier. Read More

Vibe analytics for data insights that are simple to surface AI News Every business, big or small, has a wealth of valuable data that can inform impactful decisions. But to extract insights, there’s usually a good deal of manual work that needs to be done on raw data, either by semitechnical users (such as founders and product leaders), or dedicated – and expensive – data specialists. Either
The post Vibe analytics for data insights that are simple to surface appeared first on AI News.
Every business, big or small, has a wealth of valuable data that can inform impactful decisions. But to extract insights, there’s usually a good deal of manual work that needs to be done on raw data, either by semitechnical users (such as founders and product leaders), or dedicated – and expensive – data specialists. Either
The post Vibe analytics for data insights that are simple to surface appeared first on AI News. Read More

10 Data + AI Observations for Fall 2025Towards Data Science What’s happening—and what’s next— for data and AI at the close of 2025.
The post 10 Data + AI Observations for Fall 2025 appeared first on Towards Data Science.
What’s happening—and what’s next— for data and AI at the close of 2025.
The post 10 Data + AI Observations for Fall 2025 appeared first on Towards Data Science. Read More

We Benchmarked DuckDB, SQLite, and Pandas on 1M Rows: Here’s What HappenedKDnuggets See the results of comparing speed and memory efficiency of DuckDB, SQLite, and Pandas on a million-row dataset.
See the results of comparing speed and memory efficiency of DuckDB, SQLite, and Pandas on a million-row dataset. Read More
VersionRAG: Version-Aware Retrieval-Augmented Generation for Evolving Documentscs.AI updates on arXiv.org arXiv:2510.08109v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) systems fail when documents evolve through versioning-a ubiquitous characteristic of technical documentation. Existing approaches achieve only 58-64% accuracy on version-sensitive questions, retrieving semantically similar content without temporal validity checks. We present VersionRAG, a version-aware RAG framework that explicitly models document evolution through a hierarchical graph structure capturing version sequences, content boundaries, and changes between document states. During retrieval, VersionRAG routes queries through specialized paths based on intent classification, enabling precise version-aware filtering and change tracking. On our VersionQA benchmark-100 manually curated questions across 34 versioned technical documents-VersionRAG achieves 90% accuracy, outperforming naive RAG (58%) and GraphRAG (64%). VersionRAG reaches 60% accuracy on implicit change detection where baselines fail (0-10%), demonstrating its ability to track undocumented modifications. Additionally, VersionRAG requires 97% fewer tokens during indexing than GraphRAG, making it practical for large-scale deployment. Our work establishes versioned document QA as a distinct task and provides both a solution and benchmark for future research.
arXiv:2510.08109v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) systems fail when documents evolve through versioning-a ubiquitous characteristic of technical documentation. Existing approaches achieve only 58-64% accuracy on version-sensitive questions, retrieving semantically similar content without temporal validity checks. We present VersionRAG, a version-aware RAG framework that explicitly models document evolution through a hierarchical graph structure capturing version sequences, content boundaries, and changes between document states. During retrieval, VersionRAG routes queries through specialized paths based on intent classification, enabling precise version-aware filtering and change tracking. On our VersionQA benchmark-100 manually curated questions across 34 versioned technical documents-VersionRAG achieves 90% accuracy, outperforming naive RAG (58%) and GraphRAG (64%). VersionRAG reaches 60% accuracy on implicit change detection where baselines fail (0-10%), demonstrating its ability to track undocumented modifications. Additionally, VersionRAG requires 97% fewer tokens during indexing than GraphRAG, making it practical for large-scale deployment. Our work establishes versioned document QA as a distinct task and provides both a solution and benchmark for future research. Read More
Past, Present, and Future of Bug Tracking in the Generative AI Eracs.AI updates on arXiv.org arXiv:2510.08005v1 Announce Type: cross
Abstract: Traditional bug tracking systems rely heavily on manual reporting, reproduction, triaging, and resolution, each carried out by different stakeholders such as end users, customer support, developers, and testers. This division of responsibilities requires significant coordination and widens the communication gap between non-technical users and technical teams, slowing the process from bug discovery to resolution. Moreover, current systems are highly asynchronous; users often wait hours or days for a first response, delaying fixes and contributing to frustration. This paper examines the evolution of bug tracking, from early paper-based reporting to today’s web-based and SaaS platforms. Building on this trajectory, we propose an AI-powered bug tracking framework that augments existing tools with intelligent, large language model (LLM)-driven automation. Our framework addresses two main challenges: reducing time-to-fix and minimizing human overhead. Users report issues in natural language, while AI agents refine reports, attempt reproduction, and request missing details. Reports are then classified, invalid ones resolved through no-code fixes, and valid ones localized and assigned to developers. LLMs also generate candidate patches, with human oversight ensuring correctness. By integrating automation into each phase, our framework accelerates response times, improves collaboration, and strengthens software maintenance practices for a more efficient, user-centric future.
arXiv:2510.08005v1 Announce Type: cross
Abstract: Traditional bug tracking systems rely heavily on manual reporting, reproduction, triaging, and resolution, each carried out by different stakeholders such as end users, customer support, developers, and testers. This division of responsibilities requires significant coordination and widens the communication gap between non-technical users and technical teams, slowing the process from bug discovery to resolution. Moreover, current systems are highly asynchronous; users often wait hours or days for a first response, delaying fixes and contributing to frustration. This paper examines the evolution of bug tracking, from early paper-based reporting to today’s web-based and SaaS platforms. Building on this trajectory, we propose an AI-powered bug tracking framework that augments existing tools with intelligent, large language model (LLM)-driven automation. Our framework addresses two main challenges: reducing time-to-fix and minimizing human overhead. Users report issues in natural language, while AI agents refine reports, attempt reproduction, and request missing details. Reports are then classified, invalid ones resolved through no-code fixes, and valid ones localized and assigned to developers. LLMs also generate candidate patches, with human oversight ensuring correctness. By integrating automation into each phase, our framework accelerates response times, improves collaboration, and strengthens software maintenance practices for a more efficient, user-centric future. Read More
Evaluation of LLMs for Process Model Analysis and Optimizationcs.AI updates on arXiv.org arXiv:2510.07489v1 Announce Type: new
Abstract: In this paper, we report our experience with several LLMs for their ability to understand a process model in an interactive, conversational style, find syntactical and logical errors in it, and reason with it in depth through a natural language (NL) interface. Our findings show that a vanilla, untrained LLM like ChatGPT (model o3) in a zero-shot setting is effective in understanding BPMN process models from images and answering queries about them intelligently at syntactic, logic, and semantic levels of depth. Further, different LLMs vary in performance in terms of their accuracy and effectiveness. Nevertheless, our empirical analysis shows that LLMs can play a valuable role as assistants for business process designers and users. We also study the LLM’s “thought process” and ability to perform deeper reasoning in the context of process analysis and optimization. We find that the LLMs seem to exhibit anthropomorphic properties.
arXiv:2510.07489v1 Announce Type: new
Abstract: In this paper, we report our experience with several LLMs for their ability to understand a process model in an interactive, conversational style, find syntactical and logical errors in it, and reason with it in depth through a natural language (NL) interface. Our findings show that a vanilla, untrained LLM like ChatGPT (model o3) in a zero-shot setting is effective in understanding BPMN process models from images and answering queries about them intelligently at syntactic, logic, and semantic levels of depth. Further, different LLMs vary in performance in terms of their accuracy and effectiveness. Nevertheless, our empirical analysis shows that LLMs can play a valuable role as assistants for business process designers and users. We also study the LLM’s “thought process” and ability to perform deeper reasoning in the context of process analysis and optimization. We find that the LLMs seem to exhibit anthropomorphic properties. Read More
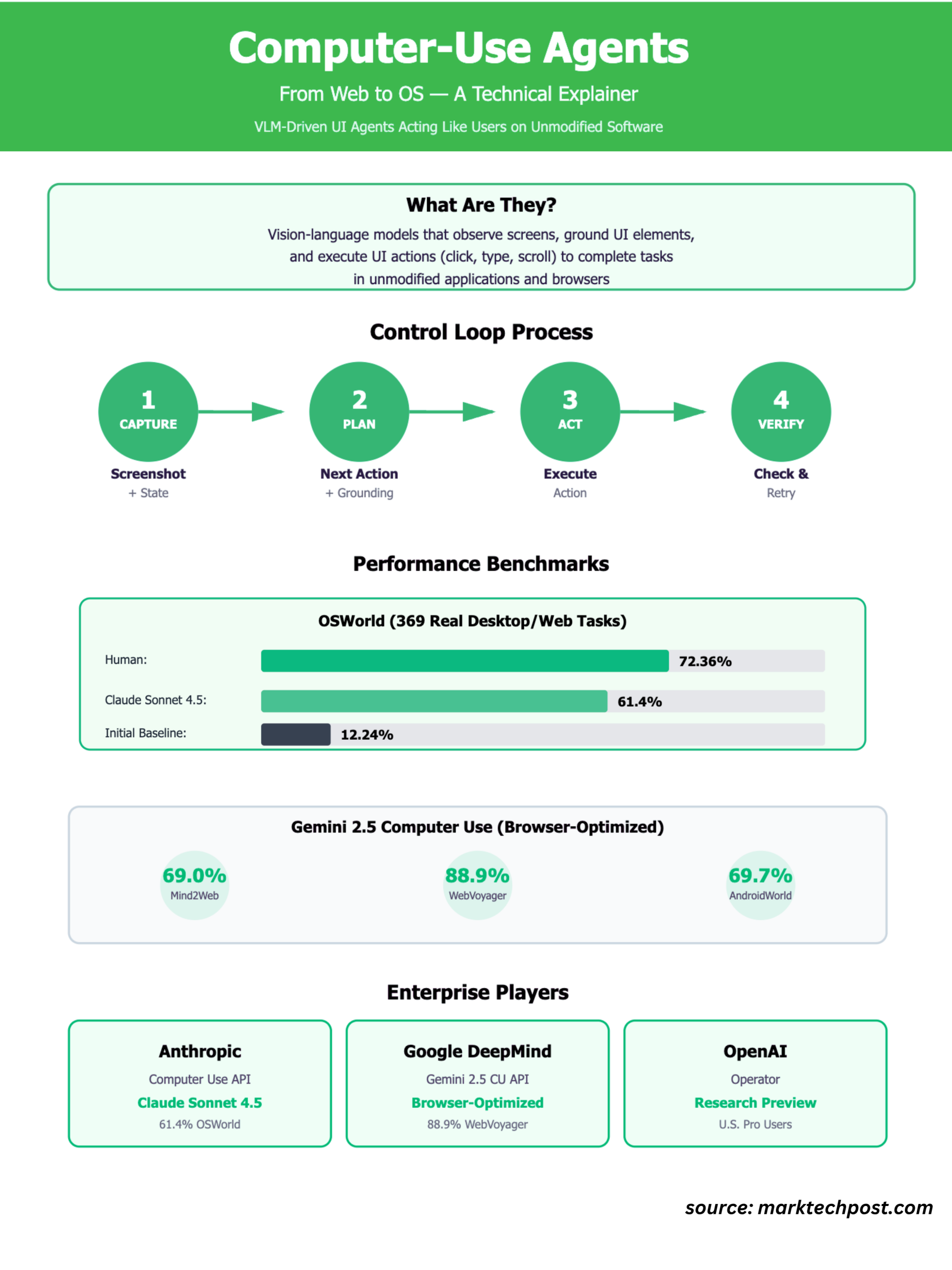
What are ‘Computer-Use Agents’? From Web to OS—A Technical ExplainerMarkTechPost TL;DR: Computer-use agents are VLM-driven UI agents that act like users on unmodified software. Baselines on OSWorld started at 12.24% (human 72.36%); Claude Sonnet 4.5 now reports 61.4%. Gemini 2.5 Computer Use leads several web benchmarks (Online-Mind2Web 69.0%, WebVoyager 88.9%) but is not yet OS-optimized. Next steps center on OS-level robustness, sub-second action loops, and
The post What are ‘Computer-Use Agents’? From Web to OS—A Technical Explainer appeared first on MarkTechPost.
TL;DR: Computer-use agents are VLM-driven UI agents that act like users on unmodified software. Baselines on OSWorld started at 12.24% (human 72.36%); Claude Sonnet 4.5 now reports 61.4%. Gemini 2.5 Computer Use leads several web benchmarks (Online-Mind2Web 69.0%, WebVoyager 88.9%) but is not yet OS-optimized. Next steps center on OS-level robustness, sub-second action loops, and
The post What are ‘Computer-Use Agents’? From Web to OS—A Technical Explainer appeared first on MarkTechPost. Read More
Self-Improving LLM Agents at Test-Timecs.AI updates on arXiv.org arXiv:2510.07841v1 Announce Type: cross
Abstract: One paradigm of language model (LM) fine-tuning relies on creating large training datasets, under the assumption that high quantity and diversity will enable models to generalize to novel tasks after post-training. In practice, gathering large sets of data is inefficient, and training on them is prohibitively expensive; worse, there is no guarantee that the resulting model will handle complex scenarios or generalize better. Moreover, existing techniques rarely assess whether a training sample provides novel information or is redundant with the knowledge already acquired by the model, resulting in unnecessary costs. In this work, we explore a new test-time self-improvement method to create more effective and generalizable agentic LMs on-the-fly. The proposed algorithm can be summarized in three steps: (i) first it identifies the samples that model struggles with (self-awareness), (ii) then generates similar examples from detected uncertain samples (self-data augmentation), and (iii) uses these newly generated samples at test-time fine-tuning (self-improvement). We study two variants of this approach: Test-Time Self-Improvement (TT-SI), where the same model generates additional training examples from its own uncertain cases and then learns from them, and contrast this approach with Test-Time Distillation (TT-D), where a stronger model generates similar examples for uncertain cases, enabling student to adapt using distilled supervision. Empirical evaluations across different agent benchmarks demonstrate that TT-SI improves the performance with +5.48% absolute accuracy gain on average across all benchmarks and surpasses other standard learning methods, yet using 68x less training samples. Our findings highlight the promise of TT-SI, demonstrating the potential of self-improvement algorithms at test-time as a new paradigm for building more capable agents toward self-evolution.
arXiv:2510.07841v1 Announce Type: cross
Abstract: One paradigm of language model (LM) fine-tuning relies on creating large training datasets, under the assumption that high quantity and diversity will enable models to generalize to novel tasks after post-training. In practice, gathering large sets of data is inefficient, and training on them is prohibitively expensive; worse, there is no guarantee that the resulting model will handle complex scenarios or generalize better. Moreover, existing techniques rarely assess whether a training sample provides novel information or is redundant with the knowledge already acquired by the model, resulting in unnecessary costs. In this work, we explore a new test-time self-improvement method to create more effective and generalizable agentic LMs on-the-fly. The proposed algorithm can be summarized in three steps: (i) first it identifies the samples that model struggles with (self-awareness), (ii) then generates similar examples from detected uncertain samples (self-data augmentation), and (iii) uses these newly generated samples at test-time fine-tuning (self-improvement). We study two variants of this approach: Test-Time Self-Improvement (TT-SI), where the same model generates additional training examples from its own uncertain cases and then learns from them, and contrast this approach with Test-Time Distillation (TT-D), where a stronger model generates similar examples for uncertain cases, enabling student to adapt using distilled supervision. Empirical evaluations across different agent benchmarks demonstrate that TT-SI improves the performance with +5.48% absolute accuracy gain on average across all benchmarks and surpasses other standard learning methods, yet using 68x less training samples. Our findings highlight the promise of TT-SI, demonstrating the potential of self-improvement algorithms at test-time as a new paradigm for building more capable agents toward self-evolution. Read More
Google Open-Sources an MCP Server for the Google Ads API, Bringing LLM-Native Access to Ads DataMarkTechPost Google has open-sourced a Model Context Protocol (MCP) server that exposes read-only access to the Google Ads API for agentic and LLM applications. The repository googleads/google-ads-mcp implements an MCP server in Python that surfaces two tools today: search (GAQL queries over Ads accounts) and list_accessible_customers (enumeration of customer resources). It includes setup via pipx, Google
The post Google Open-Sources an MCP Server for the Google Ads API, Bringing LLM-Native Access to Ads Data appeared first on MarkTechPost.
Google has open-sourced a Model Context Protocol (MCP) server that exposes read-only access to the Google Ads API for agentic and LLM applications. The repository googleads/google-ads-mcp implements an MCP server in Python that surfaces two tools today: search (GAQL queries over Ads accounts) and list_accessible_customers (enumeration of customer resources). It includes setup via pipx, Google
The post Google Open-Sources an MCP Server for the Google Ads API, Bringing LLM-Native Access to Ads Data appeared first on MarkTechPost. Read More