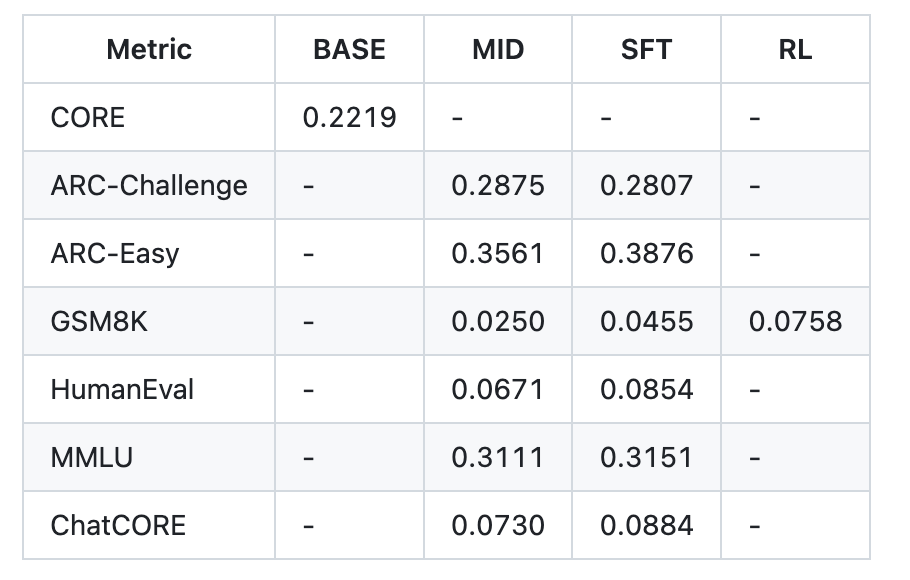
Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100MarkTechPost Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase that implements a full ChatGPT-style stack—from tokenizer training to web UI inference—aimed at reproducible, hackable LLM training on a single multi-GPU node. The repo provides a single-script “speedrun” that executes the full loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use data, Supervised Finetuning (SFT), optional RL on
The post Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100 appeared first on MarkTechPost.
Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase that implements a full ChatGPT-style stack—from tokenizer training to web UI inference—aimed at reproducible, hackable LLM training on a single multi-GPU node. The repo provides a single-script “speedrun” that executes the full loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use data, Supervised Finetuning (SFT), optional RL on
The post Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline You Can Train in ~4 Hours for ~$100 appeared first on MarkTechPost. Read More
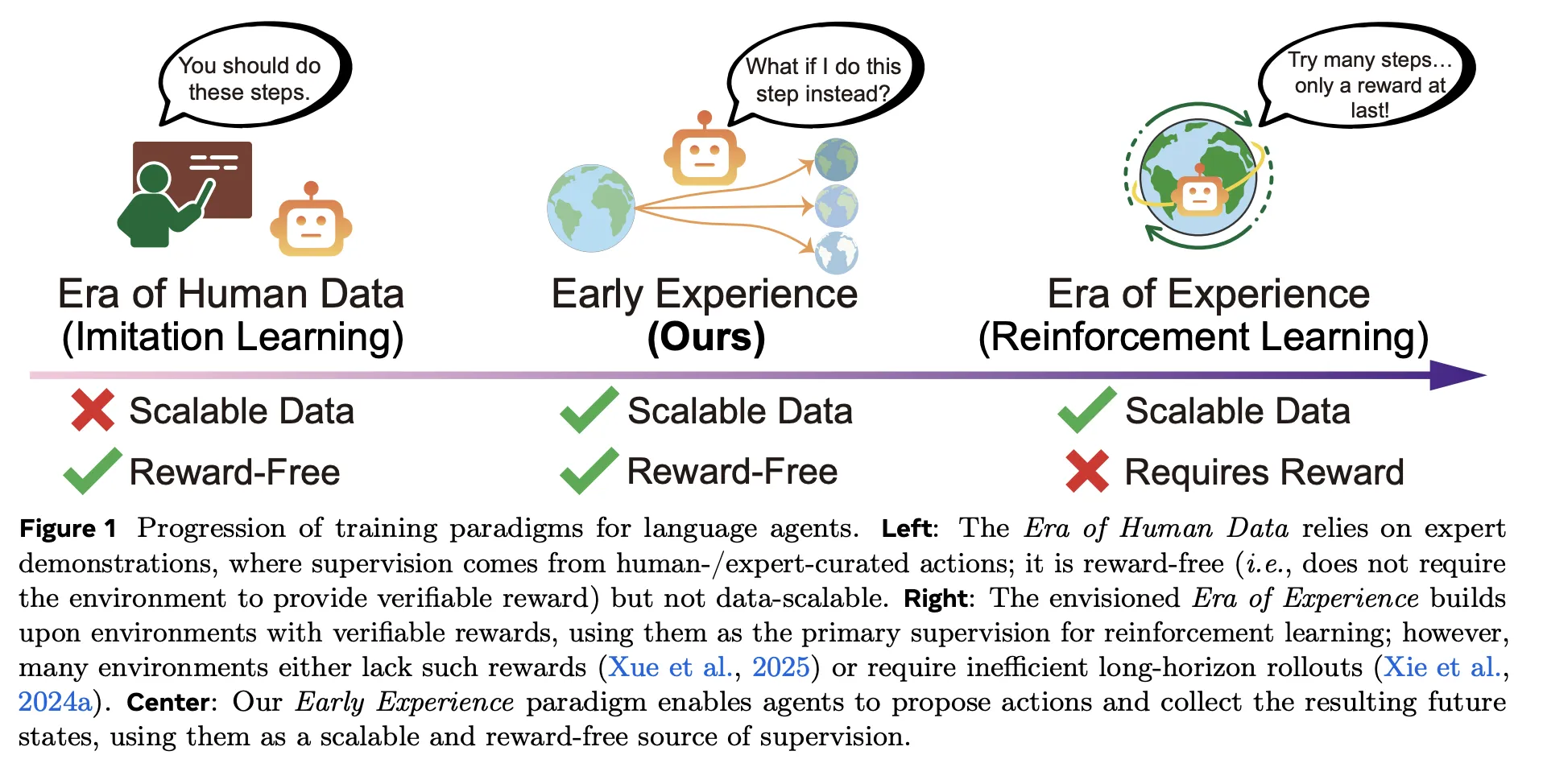
Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation LearningMarkTechPost How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet beat imitation learning across eight benchmarks? Meta Superintelligence Labs propose ‘Early Experience‘, a reward-free training approach that improves policy learning in language agents without large human demonstration sets and without reinforcement learning (RL) in the
The post Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning appeared first on MarkTechPost.
How would your agent stack change if a policy could train purely from its own outcome-grounded rollouts—no rewards, no demos—yet beat imitation learning across eight benchmarks? Meta Superintelligence Labs propose ‘Early Experience‘, a reward-free training approach that improves policy learning in language agents without large human demonstration sets and without reinforcement learning (RL) in the
The post Meta AI’s ‘Early Experience’ Trains Language Agents without Rewards—and Outperforms Imitation Learning appeared first on MarkTechPost. Read More

LiteVPNet: A Lightweight Network for Video Encoding Control in Quality-Critical Applicationscs.AI updates on arXiv.org arXiv:2510.12379v1 Announce Type: cross
Abstract: In the last decade, video workflows in the cinema production ecosystem have presented new use cases for video streaming technology. These new workflows, e.g. in On-set Virtual Production, present the challenge of requiring precise quality control and energy efficiency. Existing approaches to transcoding often fall short of these requirements, either due to a lack of quality control or computational overhead. To fill this gap, we present a lightweight neural network (LiteVPNet) for accurately predicting Quantisation Parameters for NVENC AV1 encoders that achieve a specified VMAF score. We use low-complexity features, including bitstream characteristics, video complexity measures, and CLIP-based semantic embeddings. Our results demonstrate that LiteVPNet achieves mean VMAF errors below 1.2 points across a wide range of quality targets. Notably, LiteVPNet achieves VMAF errors within 2 points for over 87% of our test corpus, c.f. approx 61% with state-of-the-art methods. LiteVPNet’s performance across various quality regions highlights its applicability for enhancing high-value content transport and streaming for more energy-efficient, high-quality media experiences.
arXiv:2510.12379v1 Announce Type: cross
Abstract: In the last decade, video workflows in the cinema production ecosystem have presented new use cases for video streaming technology. These new workflows, e.g. in On-set Virtual Production, present the challenge of requiring precise quality control and energy efficiency. Existing approaches to transcoding often fall short of these requirements, either due to a lack of quality control or computational overhead. To fill this gap, we present a lightweight neural network (LiteVPNet) for accurately predicting Quantisation Parameters for NVENC AV1 encoders that achieve a specified VMAF score. We use low-complexity features, including bitstream characteristics, video complexity measures, and CLIP-based semantic embeddings. Our results demonstrate that LiteVPNet achieves mean VMAF errors below 1.2 points across a wide range of quality targets. Notably, LiteVPNet achieves VMAF errors within 2 points for over 87% of our test corpus, c.f. approx 61% with state-of-the-art methods. LiteVPNet’s performance across various quality regions highlights its applicability for enhancing high-value content transport and streaming for more energy-efficient, high-quality media experiences. Read More
MoRA: On-the-fly Molecule-aware Low-Rank Adaptation Framework for LLM-based Multi-Modal Molecular Assistantcs.AI updates on arXiv.org arXiv:2510.12245v1 Announce Type: cross
Abstract: Effectively integrating molecular graph structures with Large Language Models (LLMs) is a key challenge in drug discovery. Most existing multi-modal alignment methods typically process these structures by fine-tuning the LLM or adding a static adapter simultaneously. However, these approaches have two main limitations: (1) it optimizes a shared parameter space across all molecular inputs, limiting the model’s ability to capture instance-specific structural features; and (2) fine-tuning the LLM for molecular tasks can lead to catastrophic forgetting, undermining its general reasoning capabilities. In this paper, instead of static task-oriented adaptation, we propose an instance-specific parameter space alignment approach for each molecule on-the-fly. To this end, we introduce Molecule-aware Low-Rank Adaptation (MoRA) that produces a unique set of low-rank adaptation weights for each input molecular graph. These weights are then dynamically injected into a frozen LLM, allowing the model to adapt its reasoning to the structure of each molecular input, while preserving the LLM’s core knowledge. Extensive experiments demonstrate that on key molecular tasks, such as chemical reaction prediction and molecular captioning, MoRA’s instance-specific dynamic adaptation outperforms statically adapted baselines, including a 14.1% relative improvement in reaction prediction exact match and a 22% reduction in error for quantum property prediction. The code is available at https://github.com/jk-sounds/MoRA.
arXiv:2510.12245v1 Announce Type: cross
Abstract: Effectively integrating molecular graph structures with Large Language Models (LLMs) is a key challenge in drug discovery. Most existing multi-modal alignment methods typically process these structures by fine-tuning the LLM or adding a static adapter simultaneously. However, these approaches have two main limitations: (1) it optimizes a shared parameter space across all molecular inputs, limiting the model’s ability to capture instance-specific structural features; and (2) fine-tuning the LLM for molecular tasks can lead to catastrophic forgetting, undermining its general reasoning capabilities. In this paper, instead of static task-oriented adaptation, we propose an instance-specific parameter space alignment approach for each molecule on-the-fly. To this end, we introduce Molecule-aware Low-Rank Adaptation (MoRA) that produces a unique set of low-rank adaptation weights for each input molecular graph. These weights are then dynamically injected into a frozen LLM, allowing the model to adapt its reasoning to the structure of each molecular input, while preserving the LLM’s core knowledge. Extensive experiments demonstrate that on key molecular tasks, such as chemical reaction prediction and molecular captioning, MoRA’s instance-specific dynamic adaptation outperforms statically adapted baselines, including a 14.1% relative improvement in reaction prediction exact match and a 22% reduction in error for quantum property prediction. The code is available at https://github.com/jk-sounds/MoRA. Read More
Chinese ModernBERT with Whole-Word Maskingcs.AI updates on arXiv.org arXiv:2510.12285v1 Announce Type: cross
Abstract: Encoder-only Transformers have advanced along three axes — architecture, data, and systems — yielding Pareto gains in accuracy, speed, and memory efficiency. Yet these improvements have not fully transferred to Chinese, where tokenization and morphology differ markedly from English. We introduce Chinese ModernBERT, a from-scratch Chinese encoder that couples: (i) a hardware-aware 32k BPE vocabulary tailored to frequent Chinese affixes/compounds, lowering the embedding budget; (ii) whole-word masking (WWM) with a dynamic masking curriculum (30% -> 15%) to align task difficulty with training progress; (iii) a two-stage pre-training pipeline that extends the native context from 1,024 to 8,192 tokens using RoPE and alternating local/global attention; and (iv) a damped-cosine learning-rate schedule for stable long-horizon optimization. We pre-train on ~1.2T Chinese tokens from CCI3-HQ, CCI4 (Chinese), and Cosmopedia-Chinese. On CLUE, Chinese ModernBERT is competitive with strong Chinese encoders under a unified fine-tuning protocol. Under bf16 it achieves high long-sequence throughput while maintaining strong short-sequence speed, reflecting benefits from budget allocation and attention design. To probe retrieval-oriented quality, we add a small amount of open contrastive data: fine-tuning on SimCLUE (~3M pairs) improves further when adding T2Ranking (~2M), reaching 0.505 (Pearson) / 0.537 (Spearman) on the SimCLUE test set. Under this open-data setting, Chinese ModernBERT surpasses Qwen-0.6B-embedding on SimCLUE, suggesting a clear scaling path for STS with additional curated pairs. We will release tokenizer and weights to facilitate reproducible research.
arXiv:2510.12285v1 Announce Type: cross
Abstract: Encoder-only Transformers have advanced along three axes — architecture, data, and systems — yielding Pareto gains in accuracy, speed, and memory efficiency. Yet these improvements have not fully transferred to Chinese, where tokenization and morphology differ markedly from English. We introduce Chinese ModernBERT, a from-scratch Chinese encoder that couples: (i) a hardware-aware 32k BPE vocabulary tailored to frequent Chinese affixes/compounds, lowering the embedding budget; (ii) whole-word masking (WWM) with a dynamic masking curriculum (30% -> 15%) to align task difficulty with training progress; (iii) a two-stage pre-training pipeline that extends the native context from 1,024 to 8,192 tokens using RoPE and alternating local/global attention; and (iv) a damped-cosine learning-rate schedule for stable long-horizon optimization. We pre-train on ~1.2T Chinese tokens from CCI3-HQ, CCI4 (Chinese), and Cosmopedia-Chinese. On CLUE, Chinese ModernBERT is competitive with strong Chinese encoders under a unified fine-tuning protocol. Under bf16 it achieves high long-sequence throughput while maintaining strong short-sequence speed, reflecting benefits from budget allocation and attention design. To probe retrieval-oriented quality, we add a small amount of open contrastive data: fine-tuning on SimCLUE (~3M pairs) improves further when adding T2Ranking (~2M), reaching 0.505 (Pearson) / 0.537 (Spearman) on the SimCLUE test set. Under this open-data setting, Chinese ModernBERT surpasses Qwen-0.6B-embedding on SimCLUE, suggesting a clear scaling path for STS with additional curated pairs. We will release tokenizer and weights to facilitate reproducible research. Read More
Credal Transformer: A Principled Approach for Quantifying and Mitigating Hallucinations in Large Language Modelscs.AI updates on arXiv.org arXiv:2510.12137v1 Announce Type: cross
Abstract: Large Language Models (LLMs) hallucinate, generating factually incorrect yet confident assertions. We argue this stems from the Transformer’s Softmax function, which creates “Artificial Certainty” by collapsing ambiguous attention scores into a single probability distribution, discarding uncertainty information at each layer. To fix this, we introduce the Credal Transformer, which replaces standard attention with a Credal Attention Mechanism (CAM) based on evidential theory. CAM produces a “credal set” (a set of distributions) instead of a single attention vector, with the set’s size directly measuring model uncertainty. We implement this by re-conceptualizing attention scores as evidence masses for a Dirichlet distribution: sufficient evidence recovers standard attention, while insufficient evidence yields a diffuse distribution, representing ambiguity. Empirically, the Credal Transformer identifies out-of-distribution inputs, quantifies ambiguity, and significantly reduces confident errors on unanswerable questions by abstaining. Our contribution is a new architecture to mitigate hallucinations and a design paradigm that integrates uncertainty quantification directly into the model, providing a foundation for more reliable AI.
arXiv:2510.12137v1 Announce Type: cross
Abstract: Large Language Models (LLMs) hallucinate, generating factually incorrect yet confident assertions. We argue this stems from the Transformer’s Softmax function, which creates “Artificial Certainty” by collapsing ambiguous attention scores into a single probability distribution, discarding uncertainty information at each layer. To fix this, we introduce the Credal Transformer, which replaces standard attention with a Credal Attention Mechanism (CAM) based on evidential theory. CAM produces a “credal set” (a set of distributions) instead of a single attention vector, with the set’s size directly measuring model uncertainty. We implement this by re-conceptualizing attention scores as evidence masses for a Dirichlet distribution: sufficient evidence recovers standard attention, while insufficient evidence yields a diffuse distribution, representing ambiguity. Empirically, the Credal Transformer identifies out-of-distribution inputs, quantifies ambiguity, and significantly reduces confident errors on unanswerable questions by abstaining. Our contribution is a new architecture to mitigate hallucinations and a design paradigm that integrates uncertainty quantification directly into the model, providing a foundation for more reliable AI. Read More
Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluationcs.AI updates on arXiv.org arXiv:2510.11977v1 Announce Type: new
Abstract: AI agents have been developed for complex real-world tasks from coding to customer service. But AI agent evaluations suffer from many challenges that undermine our understanding of how well agents really work. We introduce the Holistic Agent Leaderboard (HAL) to address these challenges. We make three main contributions. First, we provide a standardized evaluation harness that orchestrates parallel evaluations across hundreds of VMs, reducing evaluation time from weeks to hours while eliminating common implementation bugs. Second, we conduct three-dimensional analysis spanning models, scaffolds, and benchmarks. We validate the harness by conducting 21,730 agent rollouts across 9 models and 9 benchmarks in coding, web navigation, science, and customer service with a total cost of about $40,000. Our analysis reveals surprising insights, such as higher reasoning effort reducing accuracy in the majority of runs. Third, we use LLM-aided log inspection to uncover previously unreported behaviors, such as searching for the benchmark on HuggingFace instead of solving a task, or misusing credit cards in flight booking tasks. We share all agent logs, comprising 2.5B tokens of language model calls, to incentivize further research into agent behavior. By standardizing how the field evaluates agents and addressing common pitfalls in agent evaluation, we hope to shift the focus from agents that ace benchmarks to agents that work reliably in the real world.
arXiv:2510.11977v1 Announce Type: new
Abstract: AI agents have been developed for complex real-world tasks from coding to customer service. But AI agent evaluations suffer from many challenges that undermine our understanding of how well agents really work. We introduce the Holistic Agent Leaderboard (HAL) to address these challenges. We make three main contributions. First, we provide a standardized evaluation harness that orchestrates parallel evaluations across hundreds of VMs, reducing evaluation time from weeks to hours while eliminating common implementation bugs. Second, we conduct three-dimensional analysis spanning models, scaffolds, and benchmarks. We validate the harness by conducting 21,730 agent rollouts across 9 models and 9 benchmarks in coding, web navigation, science, and customer service with a total cost of about $40,000. Our analysis reveals surprising insights, such as higher reasoning effort reducing accuracy in the majority of runs. Third, we use LLM-aided log inspection to uncover previously unreported behaviors, such as searching for the benchmark on HuggingFace instead of solving a task, or misusing credit cards in flight booking tasks. We share all agent logs, comprising 2.5B tokens of language model calls, to incentivize further research into agent behavior. By standardizing how the field evaluates agents and addressing common pitfalls in agent evaluation, we hope to shift the focus from agents that ace benchmarks to agents that work reliably in the real world. Read More
Conjecturing: An Overlooked Step in Formal Mathematical Reasoningcs.AI updates on arXiv.org arXiv:2510.11986v1 Announce Type: cross
Abstract: Autoformalisation, the task of expressing informal mathematical statements in formal language, is often viewed as a direct translation process. This, however, disregards a critical preceding step: conjecturing. Many mathematical problems cannot be formalised directly without first conjecturing a conclusion such as an explicit answer, or a specific bound. Since Large Language Models (LLMs) already struggle with autoformalisation, and the evaluation of their conjecturing ability is limited and often entangled within autoformalisation or proof, it is particularly challenging to understand its effect. To address this gap, we augment existing datasets to create ConjectureBench, and redesign the evaluation framework and metric specifically to measure the conjecturing capabilities of LLMs both as a distinct task and within the autoformalisation pipeline. Our evaluation of foundational models, including GPT-4.1 and DeepSeek-V3.1, reveals that their autoformalisation performance is substantially overestimated when the conjecture is accounted for during evaluation. However, the conjecture should not be assumed to be provided. We design an inference-time method, Lean-FIRe to improve conjecturing and autoformalisation, which, to the best of our knowledge, achieves the first successful end-to-end autoformalisation of 13 PutnamBench problems with GPT-4.1 and 7 with DeepSeek-V3.1. We demonstrate that while LLMs possess the requisite knowledge to generate accurate conjectures, improving autoformalisation performance requires treating conjecturing as an independent task, and investigating further how to correctly integrate it within autoformalisation. Finally, we provide forward-looking guidance to steer future research toward improving conjecturing, an overlooked step of formal mathematical reasoning.
arXiv:2510.11986v1 Announce Type: cross
Abstract: Autoformalisation, the task of expressing informal mathematical statements in formal language, is often viewed as a direct translation process. This, however, disregards a critical preceding step: conjecturing. Many mathematical problems cannot be formalised directly without first conjecturing a conclusion such as an explicit answer, or a specific bound. Since Large Language Models (LLMs) already struggle with autoformalisation, and the evaluation of their conjecturing ability is limited and often entangled within autoformalisation or proof, it is particularly challenging to understand its effect. To address this gap, we augment existing datasets to create ConjectureBench, and redesign the evaluation framework and metric specifically to measure the conjecturing capabilities of LLMs both as a distinct task and within the autoformalisation pipeline. Our evaluation of foundational models, including GPT-4.1 and DeepSeek-V3.1, reveals that their autoformalisation performance is substantially overestimated when the conjecture is accounted for during evaluation. However, the conjecture should not be assumed to be provided. We design an inference-time method, Lean-FIRe to improve conjecturing and autoformalisation, which, to the best of our knowledge, achieves the first successful end-to-end autoformalisation of 13 PutnamBench problems with GPT-4.1 and 7 with DeepSeek-V3.1. We demonstrate that while LLMs possess the requisite knowledge to generate accurate conjectures, improving autoformalisation performance requires treating conjecturing as an independent task, and investigating further how to correctly integrate it within autoformalisation. Finally, we provide forward-looking guidance to steer future research toward improving conjecturing, an overlooked step of formal mathematical reasoning. Read More
Asking Clarifying Questions for Preference Elicitation With Large Language Modelscs.AI updates on arXiv.org arXiv:2510.12015v1 Announce Type: new
Abstract: Large Language Models (LLMs) have made it possible for recommendation systems to interact with users in open-ended conversational interfaces. In order to personalize LLM responses, it is crucial to elicit user preferences, especially when there is limited user history. One way to get more information is to present clarifying questions to the user. However, generating effective sequential clarifying questions across various domains remains a challenge. To address this, we introduce a novel approach for training LLMs to ask sequential questions that reveal user preferences. Our method follows a two-stage process inspired by diffusion models. Starting from a user profile, the forward process generates clarifying questions to obtain answers and then removes those answers step by step, serving as a way to add “noise” to the user profile. The reverse process involves training a model to “denoise” the user profile by learning to ask effective clarifying questions. Our results show that our method significantly improves the LLM’s proficiency in asking funnel questions and eliciting user preferences effectively.
arXiv:2510.12015v1 Announce Type: new
Abstract: Large Language Models (LLMs) have made it possible for recommendation systems to interact with users in open-ended conversational interfaces. In order to personalize LLM responses, it is crucial to elicit user preferences, especially when there is limited user history. One way to get more information is to present clarifying questions to the user. However, generating effective sequential clarifying questions across various domains remains a challenge. To address this, we introduce a novel approach for training LLMs to ask sequential questions that reveal user preferences. Our method follows a two-stage process inspired by diffusion models. Starting from a user profile, the forward process generates clarifying questions to obtain answers and then removes those answers step by step, serving as a way to add “noise” to the user profile. The reverse process involves training a model to “denoise” the user profile by learning to ask effective clarifying questions. Our results show that our method significantly improves the LLM’s proficiency in asking funnel questions and eliciting user preferences effectively. Read More
CGBench: Benchmarking Language Model Scientific Reasoning for Clinical Genetics Researchcs.AI updates on arXiv.org arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly.
arXiv:2510.11985v1 Announce Type: new
Abstract: Variant and gene interpretation are fundamental to personalized medicine and translational biomedicine. However, traditional approaches are manual and labor-intensive. Generative language models (LMs) can facilitate this process, accelerating the translation of fundamental research into clinically-actionable insights. While existing benchmarks have attempted to quantify the capabilities of LMs for interpreting scientific data, these studies focus on narrow tasks that do not translate to real-world research. To meet these challenges, we introduce CGBench, a robust benchmark that tests reasoning capabilities of LMs on scientific publications. CGBench is built from ClinGen, a resource of expert-curated literature interpretations in clinical genetics. CGBench measures the ability to 1) extract relevant experimental results following precise protocols and guidelines, 2) judge the strength of evidence, and 3) categorize and describe the relevant outcome of experiments. We test 8 different LMs and find that while models show promise, substantial gaps exist in literature interpretation, especially on fine-grained instructions. Reasoning models excel in fine-grained tasks but non-reasoning models are better at high-level interpretations. Finally, we measure LM explanations against human explanations with an LM judge approach, revealing that models often hallucinate or misinterpret results even when correctly classifying evidence. CGBench reveals strengths and weaknesses of LMs for precise interpretation of scientific publications, opening avenues for future research in AI for clinical genetics and science more broadly. Read More