
Meet Pyversity Library: How to Improve Retrieval Systems by Diversifying the Results Using Pyversity?MarkTechPost Pyversity is a fast, lightweight Python library designed to improve the diversity of results from retrieval systems. Retrieval often returns items that are very similar, leading to redundancy. Pyversity efficiently re-ranks these results to surface relevant but less redundant items. It offers a clear, unified API for several popular diversification strategies, including Maximal Marginal Relevance
The post Meet Pyversity Library: How to Improve Retrieval Systems by Diversifying the Results Using Pyversity? appeared first on MarkTechPost.
Pyversity is a fast, lightweight Python library designed to improve the diversity of results from retrieval systems. Retrieval often returns items that are very similar, leading to redundancy. Pyversity efficiently re-ranks these results to surface relevant but less redundant items. It offers a clear, unified API for several popular diversification strategies, including Maximal Marginal Relevance
The post Meet Pyversity Library: How to Improve Retrieval Systems by Diversifying the Results Using Pyversity? appeared first on MarkTechPost. Read More

How to Build a Fully Interactive, Real-Time Visualization Dashboard Using Bokeh and Custom JavaScript?MarkTechPost In this tutorial, we create a fully interactive, visually compelling data visualization dashboard using Bokeh. We start by turning raw data into insightful plots, then enhance them with features such as linked brushing, color gradients, and real-time filters powered by dropdowns and sliders. As we progress, we bring our dashboard to life with Custom JavaScript
The post How to Build a Fully Interactive, Real-Time Visualization Dashboard Using Bokeh and Custom JavaScript? appeared first on MarkTechPost.
In this tutorial, we create a fully interactive, visually compelling data visualization dashboard using Bokeh. We start by turning raw data into insightful plots, then enhance them with features such as linked brushing, color gradients, and real-time filters powered by dropdowns and sliders. As we progress, we bring our dashboard to life with Custom JavaScript
The post How to Build a Fully Interactive, Real-Time Visualization Dashboard Using Bokeh and Custom JavaScript? appeared first on MarkTechPost. Read More
Identifying Trustworthiness Challenges in Deep Learning Models for Continental-Scale Water Quality Predictioncs.AI updates on arXiv.org arXiv:2503.09947v3 Announce Type: replace-cross
Abstract: Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning offers transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes operational decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges, including performance disparity, robustness, uncertainty, interpretability, generalizability, and reproducibility. In this work, we present a multi-dimensional, quantitative evaluation of trustworthiness benchmarking three state-of-the-art deep learning architectures: recurrent (LSTM), operator-learning (DeepONet), and transformer-based (Informer), trained on 37 years of data from 482 U.S. basins to predict 20 water quality variables. Our investigation reveals systematic performance disparities tied to process complexity, data availability, and basin heterogeneity. Management-critical variables remain the least predictable and most uncertain. Robustness tests reveal pronounced sensitivity to outliers and corrupted targets; notably, the architecture with the strongest baseline performance (LSTM) proves most vulnerable under data corruption. Attribution analyses align for simple variables but diverge for nutrients, underscoring the need for multi-method interpretability. Spatial generalization to ungauged basins remains poor across all models. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management.
arXiv:2503.09947v3 Announce Type: replace-cross
Abstract: Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning offers transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes operational decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges, including performance disparity, robustness, uncertainty, interpretability, generalizability, and reproducibility. In this work, we present a multi-dimensional, quantitative evaluation of trustworthiness benchmarking three state-of-the-art deep learning architectures: recurrent (LSTM), operator-learning (DeepONet), and transformer-based (Informer), trained on 37 years of data from 482 U.S. basins to predict 20 water quality variables. Our investigation reveals systematic performance disparities tied to process complexity, data availability, and basin heterogeneity. Management-critical variables remain the least predictable and most uncertain. Robustness tests reveal pronounced sensitivity to outliers and corrupted targets; notably, the architecture with the strongest baseline performance (LSTM) proves most vulnerable under data corruption. Attribution analyses align for simple variables but diverge for nutrients, underscoring the need for multi-method interpretability. Spatial generalization to ungauged basins remains poor across all models. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management. Read More
Can Large Language Models Unlock Novel Scientific Research Ideas?cs.AI updates on arXiv.org arXiv:2409.06185v2 Announce Type: replace-cross
Abstract: The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT have marked a significant turning point in the integration of Artificial Intelligence (AI) into people’s everyday lives. This study examines the ability of Large Language Models (LLMs) to generate future research ideas from scientific papers. Unlike tasks such as summarization or translation, idea generation lacks a clearly defined reference set or structure, making manual evaluation the default standard. However, human evaluation in this setting is extremely challenging ie: it requires substantial domain expertise, contextual understanding of the paper, and awareness of the current research landscape. This makes it time-consuming, costly, and fundamentally non-scalable, particularly as new LLMs are being released at a rapid pace. Currently, there is no automated evaluation metric specifically designed for this task. To address this gap, we propose two automated evaluation metrics: Idea Alignment Score (IAScore) and Idea Distinctness Index. We further conducted human evaluation to assess the novelty, relevance, and feasibility of the generated future research ideas. This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available
arXiv:2409.06185v2 Announce Type: replace-cross
Abstract: The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT have marked a significant turning point in the integration of Artificial Intelligence (AI) into people’s everyday lives. This study examines the ability of Large Language Models (LLMs) to generate future research ideas from scientific papers. Unlike tasks such as summarization or translation, idea generation lacks a clearly defined reference set or structure, making manual evaluation the default standard. However, human evaluation in this setting is extremely challenging ie: it requires substantial domain expertise, contextual understanding of the paper, and awareness of the current research landscape. This makes it time-consuming, costly, and fundamentally non-scalable, particularly as new LLMs are being released at a rapid pace. Currently, there is no automated evaluation metric specifically designed for this task. To address this gap, we propose two automated evaluation metrics: Idea Alignment Score (IAScore) and Idea Distinctness Index. We further conducted human evaluation to assess the novelty, relevance, and feasibility of the generated future research ideas. This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available Read More
Correct Reasoning Paths Visit Shared Decision Pivotscs.AI updates on arXiv.org arXiv:2509.21549v2 Announce Type: replace
Abstract: Chain-of-thought (CoT) reasoning exposes the intermediate thinking process of large language models (LLMs), yet verifying those traces at scale remains unsolved. In response, we introduce the idea of decision pivots-minimal, verifiable checkpoints that any correct reasoning path must visit. We hypothesize that correct reasoning, though stylistically diverse, converge on the same pivot set, while incorrect ones violate at least one pivot. Leveraging this property, we propose a self-training pipeline that (i) samples diverse reasoning paths and mines shared decision pivots, (ii) compresses each trace into pivot-focused short-path reasoning using an auxiliary verifier, and (iii) post-trains the model using its self-generated outputs. The proposed method aligns reasoning without ground truth reasoning data or external metrics. Experiments on standard benchmarks such as LogiQA, MedQA, and MATH500 show the effectiveness of our method.
arXiv:2509.21549v2 Announce Type: replace
Abstract: Chain-of-thought (CoT) reasoning exposes the intermediate thinking process of large language models (LLMs), yet verifying those traces at scale remains unsolved. In response, we introduce the idea of decision pivots-minimal, verifiable checkpoints that any correct reasoning path must visit. We hypothesize that correct reasoning, though stylistically diverse, converge on the same pivot set, while incorrect ones violate at least one pivot. Leveraging this property, we propose a self-training pipeline that (i) samples diverse reasoning paths and mines shared decision pivots, (ii) compresses each trace into pivot-focused short-path reasoning using an auxiliary verifier, and (iii) post-trains the model using its self-generated outputs. The proposed method aligns reasoning without ground truth reasoning data or external metrics. Experiments on standard benchmarks such as LogiQA, MedQA, and MATH500 show the effectiveness of our method. Read More
Faster Reinforcement Learning by Freezing Slow Statescs.AI updates on arXiv.org arXiv:2301.00922v4 Announce Type: replace
Abstract: We study infinite horizon Markov decision processes (MDPs) with “fast-slow” structure, where some state variables evolve rapidly (“fast states”) while others change more gradually (“slow states”). This structure commonly arises in practice when decisions must be made at high frequencies over long horizons, and where slowly changing information still plays a critical role in determining optimal actions. Examples include inventory control under slowly changing demand indicators or dynamic pricing with gradually shifting consumer behavior. Modeling the problem at the natural decision frequency leads to MDPs with discount factors close to one, making them computationally challenging. We propose a novel approximation strategy that “freezes” slow states during phases of lower-level planning and subsequently applies value iteration to an auxiliary upper-level MDP that evolves on a slower timescale. Freezing states for short periods of time leads to easier-to-solve lower-level problems, while a slower upper-level timescale allows for a more favorable discount factor. On the theoretical side, we analyze the regret incurred by our frozen-state approach, which leads to simple insights on how to trade off regret versus computational cost. Empirically, we benchmark our new frozen-state methods on three domains, (i) inventory control with fixed order costs, (ii) a gridworld problem with spatial tasks, and (iii) dynamic pricing with reference-price effects. We demonstrate that the new methods produce high-quality policies with significantly less computation, and we show that simply omitting slow states is often a poor heuristic.
arXiv:2301.00922v4 Announce Type: replace
Abstract: We study infinite horizon Markov decision processes (MDPs) with “fast-slow” structure, where some state variables evolve rapidly (“fast states”) while others change more gradually (“slow states”). This structure commonly arises in practice when decisions must be made at high frequencies over long horizons, and where slowly changing information still plays a critical role in determining optimal actions. Examples include inventory control under slowly changing demand indicators or dynamic pricing with gradually shifting consumer behavior. Modeling the problem at the natural decision frequency leads to MDPs with discount factors close to one, making them computationally challenging. We propose a novel approximation strategy that “freezes” slow states during phases of lower-level planning and subsequently applies value iteration to an auxiliary upper-level MDP that evolves on a slower timescale. Freezing states for short periods of time leads to easier-to-solve lower-level problems, while a slower upper-level timescale allows for a more favorable discount factor. On the theoretical side, we analyze the regret incurred by our frozen-state approach, which leads to simple insights on how to trade off regret versus computational cost. Empirically, we benchmark our new frozen-state methods on three domains, (i) inventory control with fixed order costs, (ii) a gridworld problem with spatial tasks, and (iii) dynamic pricing with reference-price effects. We demonstrate that the new methods produce high-quality policies with significantly less computation, and we show that simply omitting slow states is often a poor heuristic. Read More
Smartphone-based iris recognition through high-quality visible-spectrum iris image capture.V2cs.AI updates on arXiv.org arXiv:2510.06170v2 Announce Type: replace-cross
Abstract: Smartphone-based iris recognition in the visible spectrum (VIS) remains difficult due to illumination variability, pigmentation differences, and the absence of standardized capture controls. This work presents a compact end-to-end pipeline that enforces ISO/IEC 29794-6 quality compliance at acquisition and demonstrates that accurate VIS iris recognition is feasible on commodity devices. Using a custom Android application performing real-time framing, sharpness evaluation, and feedback, we introduce the CUVIRIS dataset of 752 compliant images from 47 subjects. A lightweight MobileNetV3-based multi-task segmentation network (LightIrisNet) is developed for efficient on-device processing, and a transformer matcher (IrisFormer) is adapted to the VIS domain. Under a standardized protocol and comparative benchmarking against prior CNN baselines, OSIRIS attains a TAR of 97.9% at FAR=0.01 (EER=0.76%), while IrisFormer, trained only on UBIRIS.v2, achieves an EER of 0.057% on CUVIRIS. The acquisition app, trained models, and a public subset of the dataset are released to support reproducibility. These results confirm that standardized capture and VIS-adapted lightweight models enable accurate and practical iris recognition on smartphones.
arXiv:2510.06170v2 Announce Type: replace-cross
Abstract: Smartphone-based iris recognition in the visible spectrum (VIS) remains difficult due to illumination variability, pigmentation differences, and the absence of standardized capture controls. This work presents a compact end-to-end pipeline that enforces ISO/IEC 29794-6 quality compliance at acquisition and demonstrates that accurate VIS iris recognition is feasible on commodity devices. Using a custom Android application performing real-time framing, sharpness evaluation, and feedback, we introduce the CUVIRIS dataset of 752 compliant images from 47 subjects. A lightweight MobileNetV3-based multi-task segmentation network (LightIrisNet) is developed for efficient on-device processing, and a transformer matcher (IrisFormer) is adapted to the VIS domain. Under a standardized protocol and comparative benchmarking against prior CNN baselines, OSIRIS attains a TAR of 97.9% at FAR=0.01 (EER=0.76%), while IrisFormer, trained only on UBIRIS.v2, achieves an EER of 0.057% on CUVIRIS. The acquisition app, trained models, and a public subset of the dataset are released to support reproducibility. These results confirm that standardized capture and VIS-adapted lightweight models enable accurate and practical iris recognition on smartphones. Read More
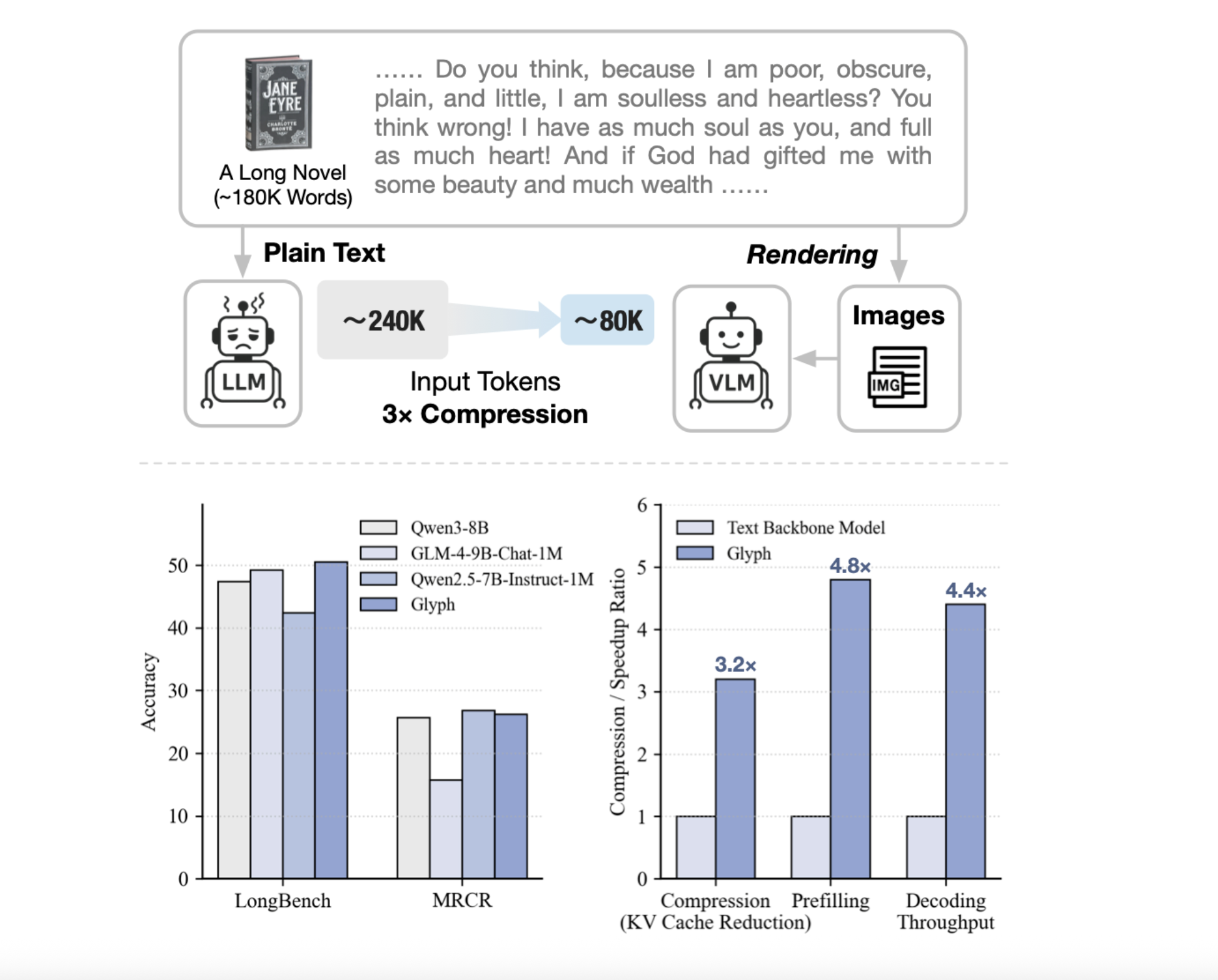
Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text CompressionMarkTechPost Can we render long texts as images and use a VLM to achieve 3–4× token compression, preserving accuracy while scaling a 128K context toward 1M-token workloads? A team of researchers from Zhipu AI release Glyph, an AI framework for scaling the context length through visual-text compression. It renders long textual sequences into images and processes
The post Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression appeared first on MarkTechPost.
Can we render long texts as images and use a VLM to achieve 3–4× token compression, preserving accuracy while scaling a 128K context toward 1M-token workloads? A team of researchers from Zhipu AI release Glyph, an AI framework for scaling the context length through visual-text compression. It renders long textual sequences into images and processes
The post Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression appeared first on MarkTechPost. Read More
Accelerating Eigenvalue Dataset Generation via Chebyshev Subspace Filtercs.AI updates on arXiv.org arXiv:2510.23215v1 Announce Type: cross
Abstract: Eigenvalue problems are among the most important topics in many scientific disciplines. With the recent surge and development of machine learning, neural eigenvalue methods have attracted significant attention as a forward pass of inference requires only a tiny fraction of the computation time compared to traditional solvers. However, a key limitation is the requirement for large amounts of labeled data in training, including operators and their eigenvalues. To tackle this limitation, we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators — a factor overlooked by existing methods. Specifically, SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations. To the best of our knowledge, SCSF is the first method to accelerate eigenvalue data generation. Experimental results show that SCSF achieves up to a $3.5times$ speedup compared to various numerical solvers.
arXiv:2510.23215v1 Announce Type: cross
Abstract: Eigenvalue problems are among the most important topics in many scientific disciplines. With the recent surge and development of machine learning, neural eigenvalue methods have attracted significant attention as a forward pass of inference requires only a tiny fraction of the computation time compared to traditional solvers. However, a key limitation is the requirement for large amounts of labeled data in training, including operators and their eigenvalues. To tackle this limitation, we propose a novel method, named Sorting Chebyshev Subspace Filter (SCSF), which significantly accelerates eigenvalue data generation by leveraging similarities between operators — a factor overlooked by existing methods. Specifically, SCSF employs truncated fast Fourier transform sorting to group operators with similar eigenvalue distributions and constructs a Chebyshev subspace filter that leverages eigenpairs from previously solved problems to assist in solving subsequent ones, reducing redundant computations. To the best of our knowledge, SCSF is the first method to accelerate eigenvalue data generation. Experimental results show that SCSF achieves up to a $3.5times$ speedup compared to various numerical solvers. Read More
Computational Hardness of Reinforcement Learning with Partial $q^{pi}$-Realizabilitycs.AI updates on arXiv.org arXiv:2510.21888v1 Announce Type: new
Abstract: This paper investigates the computational complexity of reinforcement learning in a novel linear function approximation regime, termed partial $q^{pi}$-realizability. In this framework, the objective is to learn an $epsilon$-optimal policy with respect to a predefined policy set $Pi$, under the assumption that all value functions for policies in $Pi$ are linearly realizable. The assumptions of this framework are weaker than those in $q^{pi}$-realizability but stronger than those in $q^*$-realizability, providing a practical model where function approximation naturally arises. We prove that learning an $epsilon$-optimal policy in this setting is computationally hard. Specifically, we establish NP-hardness under a parameterized greedy policy set (argmax) and show that – unless NP = RP – an exponential lower bound (in feature vector dimension) holds when the policy set contains softmax policies, under the Randomized Exponential Time Hypothesis. Our hardness results mirror those in $q^*$-realizability and suggest computational difficulty persists even when $Pi$ is expanded beyond the optimal policy. To establish this, we reduce from two complexity problems, $delta$-Max-3SAT and $delta$-Max-3SAT(b), to instances of GLinear-$kappa$-RL (greedy policy) and SLinear-$kappa$-RL (softmax policy). Our findings indicate that positive computational results are generally unattainable in partial $q^{pi}$-realizability, in contrast to $q^{pi}$-realizability under a generative access model.
arXiv:2510.21888v1 Announce Type: new
Abstract: This paper investigates the computational complexity of reinforcement learning in a novel linear function approximation regime, termed partial $q^{pi}$-realizability. In this framework, the objective is to learn an $epsilon$-optimal policy with respect to a predefined policy set $Pi$, under the assumption that all value functions for policies in $Pi$ are linearly realizable. The assumptions of this framework are weaker than those in $q^{pi}$-realizability but stronger than those in $q^*$-realizability, providing a practical model where function approximation naturally arises. We prove that learning an $epsilon$-optimal policy in this setting is computationally hard. Specifically, we establish NP-hardness under a parameterized greedy policy set (argmax) and show that – unless NP = RP – an exponential lower bound (in feature vector dimension) holds when the policy set contains softmax policies, under the Randomized Exponential Time Hypothesis. Our hardness results mirror those in $q^*$-realizability and suggest computational difficulty persists even when $Pi$ is expanded beyond the optimal policy. To establish this, we reduce from two complexity problems, $delta$-Max-3SAT and $delta$-Max-3SAT(b), to instances of GLinear-$kappa$-RL (greedy policy) and SLinear-$kappa$-RL (softmax policy). Our findings indicate that positive computational results are generally unattainable in partial $q^{pi}$-realizability, in contrast to $q^{pi}$-realizability under a generative access model. Read More