
ComboBench: Can LLMs Manipulate Physical Devices to Play Virtual Reality Games?cs.AI updates on arXiv.org arXiv:2510.24706v1 Announce Type: cross
Abstract: Virtual Reality (VR) games require players to translate high-level semantic actions into precise device manipulations using controllers and head-mounted displays (HMDs). While humans intuitively perform this translation based on common sense and embodied understanding, whether Large Language Models (LLMs) can effectively replicate this ability remains underexplored. This paper introduces a benchmark, ComboBench, evaluating LLMs’ capability to translate semantic actions into VR device manipulation sequences across 262 scenarios from four popular VR games: Half-Life: Alyx, Into the Radius, Moss: Book II, and Vivecraft. We evaluate seven LLMs, including GPT-3.5, GPT-4, GPT-4o, Gemini-1.5-Pro, LLaMA-3-8B, Mixtral-8x7B, and GLM-4-Flash, compared against annotated ground truth and human performance. Our results reveal that while top-performing models like Gemini-1.5-Pro demonstrate strong task decomposition capabilities, they still struggle with procedural reasoning and spatial understanding compared to humans. Performance varies significantly across games, suggesting sensitivity to interaction complexity. Few-shot examples substantially improve performance, indicating potential for targeted enhancement of LLMs’ VR manipulation capabilities. We release all materials at https://sites.google.com/view/combobench.
arXiv:2510.24706v1 Announce Type: cross
Abstract: Virtual Reality (VR) games require players to translate high-level semantic actions into precise device manipulations using controllers and head-mounted displays (HMDs). While humans intuitively perform this translation based on common sense and embodied understanding, whether Large Language Models (LLMs) can effectively replicate this ability remains underexplored. This paper introduces a benchmark, ComboBench, evaluating LLMs’ capability to translate semantic actions into VR device manipulation sequences across 262 scenarios from four popular VR games: Half-Life: Alyx, Into the Radius, Moss: Book II, and Vivecraft. We evaluate seven LLMs, including GPT-3.5, GPT-4, GPT-4o, Gemini-1.5-Pro, LLaMA-3-8B, Mixtral-8x7B, and GLM-4-Flash, compared against annotated ground truth and human performance. Our results reveal that while top-performing models like Gemini-1.5-Pro demonstrate strong task decomposition capabilities, they still struggle with procedural reasoning and spatial understanding compared to humans. Performance varies significantly across games, suggesting sensitivity to interaction complexity. Few-shot examples substantially improve performance, indicating potential for targeted enhancement of LLMs’ VR manipulation capabilities. We release all materials at https://sites.google.com/view/combobench. Read More
Metadata-Driven Retrieval-Augmented Generation for Financial Question Answeringcs.AI updates on arXiv.org arXiv:2510.24402v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) struggles on long, structured financial filings where relevant evidence is sparse and cross-referenced. This paper presents a systematic investigation of advanced metadata-driven Retrieval-Augmented Generation (RAG) techniques, proposing and evaluating a novel, multi-stage RAG architecture that leverages LLM-generated metadata. We introduce a sophisticated indexing pipeline to create contextually rich document chunks and benchmark a spectrum of enhancements, including pre-retrieval filtering, post-retrieval reranking, and enriched embeddings, benchmarked on the FinanceBench dataset. Our results reveal that while a powerful reranker is essential for precision, the most significant performance gains come from embedding chunk metadata directly with text (“contextual chunks”). Our proposed optimal architecture combines LLM-driven pre-retrieval optimizations with these contextual embeddings to achieve superior performance. Additionally, we present a custom metadata reranker that offers a compelling, cost-effective alternative to commercial solutions, highlighting a practical trade-off between peak performance and operational efficiency. This study provides a blueprint for building robust, metadata-aware RAG systems for financial document analysis.
arXiv:2510.24402v1 Announce Type: cross
Abstract: Retrieval-Augmented Generation (RAG) struggles on long, structured financial filings where relevant evidence is sparse and cross-referenced. This paper presents a systematic investigation of advanced metadata-driven Retrieval-Augmented Generation (RAG) techniques, proposing and evaluating a novel, multi-stage RAG architecture that leverages LLM-generated metadata. We introduce a sophisticated indexing pipeline to create contextually rich document chunks and benchmark a spectrum of enhancements, including pre-retrieval filtering, post-retrieval reranking, and enriched embeddings, benchmarked on the FinanceBench dataset. Our results reveal that while a powerful reranker is essential for precision, the most significant performance gains come from embedding chunk metadata directly with text (“contextual chunks”). Our proposed optimal architecture combines LLM-driven pre-retrieval optimizations with these contextual embeddings to achieve superior performance. Additionally, we present a custom metadata reranker that offers a compelling, cost-effective alternative to commercial solutions, highlighting a practical trade-off between peak performance and operational efficiency. This study provides a blueprint for building robust, metadata-aware RAG systems for financial document analysis. Read More
HyPerNav: Hybrid Perception for Object-Oriented Navigation in Unknown Environmentcs.AI updates on arXiv.org arXiv:2510.22917v2 Announce Type: replace-cross
Abstract: Objective-oriented navigation(ObjNav) enables robot to navigate to target object directly and autonomously in an unknown environment. Effective perception in navigation in unknown environment is critical for autonomous robots. While egocentric observations from RGB-D sensors provide abundant local information, real-time top-down maps offer valuable global context for ObjNav. Nevertheless, the majority of existing studies focus on a single source, seldom integrating these two complementary perceptual modalities, despite the fact that humans naturally attend to both. With the rapid advancement of Vision-Language Models(VLMs), we propose Hybrid Perception Navigation (HyPerNav), leveraging VLMs’ strong reasoning and vision-language understanding capabilities to jointly perceive both local and global information to enhance the effectiveness and intelligence of navigation in unknown environments. In both massive simulation evaluation and real-world validation, our methods achieved state-of-the-art performance against popular baselines. Benefiting from hybrid perception approach, our method captures richer cues and finds the objects more effectively, by simultaneously leveraging information understanding from egocentric observations and the top-down map. Our ablation study further proved that either of the hybrid perception contributes to the navigation performance.
arXiv:2510.22917v2 Announce Type: replace-cross
Abstract: Objective-oriented navigation(ObjNav) enables robot to navigate to target object directly and autonomously in an unknown environment. Effective perception in navigation in unknown environment is critical for autonomous robots. While egocentric observations from RGB-D sensors provide abundant local information, real-time top-down maps offer valuable global context for ObjNav. Nevertheless, the majority of existing studies focus on a single source, seldom integrating these two complementary perceptual modalities, despite the fact that humans naturally attend to both. With the rapid advancement of Vision-Language Models(VLMs), we propose Hybrid Perception Navigation (HyPerNav), leveraging VLMs’ strong reasoning and vision-language understanding capabilities to jointly perceive both local and global information to enhance the effectiveness and intelligence of navigation in unknown environments. In both massive simulation evaluation and real-world validation, our methods achieved state-of-the-art performance against popular baselines. Benefiting from hybrid perception approach, our method captures richer cues and finds the objects more effectively, by simultaneously leveraging information understanding from egocentric observations and the top-down map. Our ablation study further proved that either of the hybrid perception contributes to the navigation performance. Read More
Test-Time Tuned Language Models Enable End-to-end De Novo Molecular Structure Generation from MS/MS Spectracs.AI updates on arXiv.org arXiv:2510.23746v1 Announce Type: new
Abstract: Tandem Mass Spectrometry enables the identification of unknown compounds in crucial fields such as metabolomics, natural product discovery and environmental analysis. However, current methods rely on database matching from previously observed molecules, or on multi-step pipelines that require intermediate fragment or fingerprint prediction. This makes finding the correct molecule highly challenging, particularly for compounds absent from reference databases. We introduce a framework that, by leveraging test-time tuning, enhances the learning of a pre-trained transformer model to address this gap, enabling end-to-end de novo molecular structure generation directly from the tandem mass spectra and molecular formulae, bypassing manual annotations and intermediate steps. We surpass the de-facto state-of-the-art approach DiffMS on two popular benchmarks NPLIB1 and MassSpecGym by 100% and 20%, respectively. Test-time tuning on experimental spectra allows the model to dynamically adapt to novel spectra, and the relative performance gain over conventional fine-tuning is of 62% on MassSpecGym. When predictions deviate from the ground truth, the generated molecular candidates remain structurally accurate, providing valuable guidance for human interpretation and more reliable identification.
arXiv:2510.23746v1 Announce Type: new
Abstract: Tandem Mass Spectrometry enables the identification of unknown compounds in crucial fields such as metabolomics, natural product discovery and environmental analysis. However, current methods rely on database matching from previously observed molecules, or on multi-step pipelines that require intermediate fragment or fingerprint prediction. This makes finding the correct molecule highly challenging, particularly for compounds absent from reference databases. We introduce a framework that, by leveraging test-time tuning, enhances the learning of a pre-trained transformer model to address this gap, enabling end-to-end de novo molecular structure generation directly from the tandem mass spectra and molecular formulae, bypassing manual annotations and intermediate steps. We surpass the de-facto state-of-the-art approach DiffMS on two popular benchmarks NPLIB1 and MassSpecGym by 100% and 20%, respectively. Test-time tuning on experimental spectra allows the model to dynamically adapt to novel spectra, and the relative performance gain over conventional fine-tuning is of 62% on MassSpecGym. When predictions deviate from the ground truth, the generated molecular candidates remain structurally accurate, providing valuable guidance for human interpretation and more reliable identification. Read More
Evaluating In Silico Creativity: An Expert Review of AI Chess Compositionscs.AI updates on arXiv.org arXiv:2510.23772v1 Announce Type: new
Abstract: The rapid advancement of Generative AI has raised significant questions regarding its ability to produce creative and novel outputs. Our recent work investigates this question within the domain of chess puzzles and presents an AI system designed to generate puzzles characterized by aesthetic appeal, novelty, counter-intuitive and unique solutions. We briefly discuss our method below and refer the reader to the technical paper for more details. To assess our system’s creativity, we presented a curated booklet of AI-generated puzzles to three world-renowned experts: International Master for chess compositions Amatzia Avni, Grandmaster Jonathan Levitt, and Grandmaster Matthew Sadler. All three are noted authors on chess aesthetics and the evolving role of computers in the game. They were asked to select their favorites and explain what made them appealing, considering qualities such as their creativity, level of challenge, or aesthetic design.
arXiv:2510.23772v1 Announce Type: new
Abstract: The rapid advancement of Generative AI has raised significant questions regarding its ability to produce creative and novel outputs. Our recent work investigates this question within the domain of chess puzzles and presents an AI system designed to generate puzzles characterized by aesthetic appeal, novelty, counter-intuitive and unique solutions. We briefly discuss our method below and refer the reader to the technical paper for more details. To assess our system’s creativity, we presented a curated booklet of AI-generated puzzles to three world-renowned experts: International Master for chess compositions Amatzia Avni, Grandmaster Jonathan Levitt, and Grandmaster Matthew Sadler. All three are noted authors on chess aesthetics and the evolving role of computers in the game. They were asked to select their favorites and explain what made them appealing, considering qualities such as their creativity, level of challenge, or aesthetic design. Read More
Built to benefit everyoneOpenAI News OpenAI’s recapitalization strengthens mission-focused governance, expanding resources to ensure AI benefits everyone while advancing innovation responsibly.
OpenAI’s recapitalization strengthens mission-focused governance, expanding resources to ensure AI benefits everyone while advancing innovation responsibly. Read More
Taming Silent Failures: A Framework for Verifiable AI Reliabilitycs.AI updates on arXiv.org arXiv:2510.22224v1 Announce Type: cross
Abstract: The integration of Artificial Intelligence (AI) into safety-critical systems introduces a new reliability paradigm: silent failures, where AI produces confident but incorrect outputs that can be dangerous. This paper introduces the Formal Assurance and Monitoring Environment (FAME), a novel framework that confronts this challenge. FAME synergizes the mathematical rigor of offline formal synthesis with the vigilance of online runtime monitoring to create a verifiable safety net around opaque AI components. We demonstrate its efficacy in an autonomous vehicle perception system, where FAME successfully detected 93.5% of critical safety violations that were otherwise silent. By contextualizing our framework within the ISO 26262 and ISO/PAS 8800 standards, we provide reliability engineers with a practical, certifiable pathway for deploying trustworthy AI. FAME represents a crucial shift from accepting probabilistic performance to enforcing provable safety in next-generation systems.
arXiv:2510.22224v1 Announce Type: cross
Abstract: The integration of Artificial Intelligence (AI) into safety-critical systems introduces a new reliability paradigm: silent failures, where AI produces confident but incorrect outputs that can be dangerous. This paper introduces the Formal Assurance and Monitoring Environment (FAME), a novel framework that confronts this challenge. FAME synergizes the mathematical rigor of offline formal synthesis with the vigilance of online runtime monitoring to create a verifiable safety net around opaque AI components. We demonstrate its efficacy in an autonomous vehicle perception system, where FAME successfully detected 93.5% of critical safety violations that were otherwise silent. By contextualizing our framework within the ISO 26262 and ISO/PAS 8800 standards, we provide reliability engineers with a practical, certifiable pathway for deploying trustworthy AI. FAME represents a crucial shift from accepting probabilistic performance to enforcing provable safety in next-generation systems. Read More
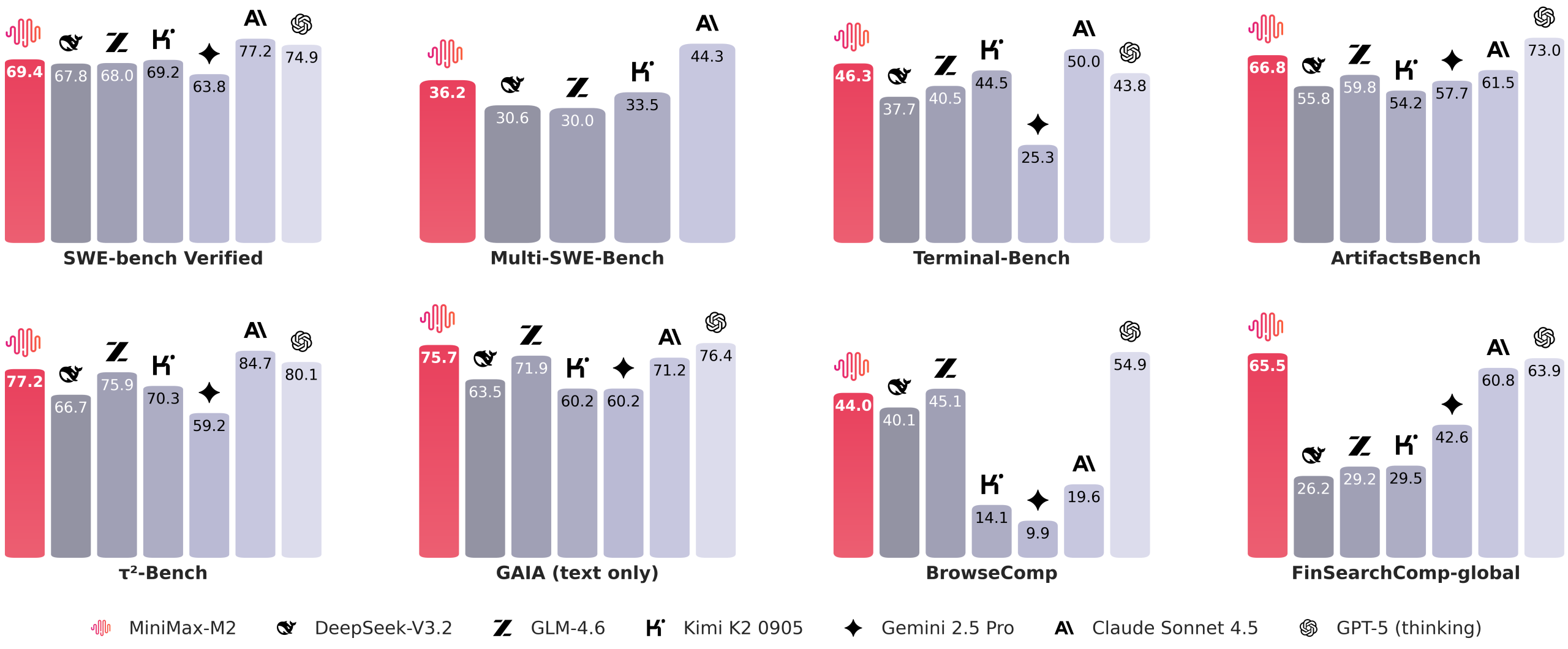
MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x FasterMarkTechPost Can an open source MoE truly power agentic coding workflows at a fraction of flagship model costs while sustaining long-horizon tool use across MCP, shell, browser, retrieval, and code? MiniMax team has just released MiniMax-M2, a mixture of experts MoE model optimized for coding and agent workflows. The weights are published on Hugging Face under
The post MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster appeared first on MarkTechPost.
Can an open source MoE truly power agentic coding workflows at a fraction of flagship model costs while sustaining long-horizon tool use across MCP, shell, browser, retrieval, and code? MiniMax team has just released MiniMax-M2, a mixture of experts MoE model optimized for coding and agent workflows. The weights are published on Hugging Face under
The post MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster appeared first on MarkTechPost. Read More
Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood)Towards Data Science Can I use NumPy to figure out how my habits affect my mood and productivity?
The post Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood) appeared first on Towards Data Science.
Can I use NumPy to figure out how my habits affect my mood and productivity?
The post Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood) appeared first on Towards Data Science. Read More
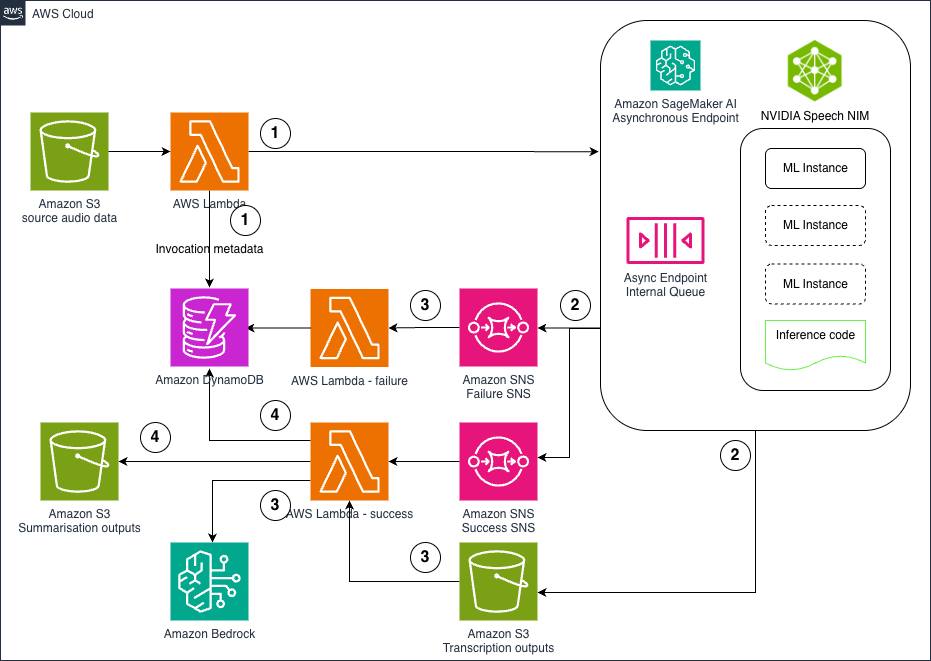
Hosting NVIDIA speech NIM models on Amazon SageMaker AI: Parakeet ASRArtificial Intelligence In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale .
In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale . Read More