
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Modelscs.AI updates on arXiv.org arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space.
arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space. Read More
Adaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvementcs.AI updates on arXiv.org arXiv:2510.27051v1 Announce Type: new
Abstract: Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA’s Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25%) and query rephrasal errors (3.2%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96% accuracy, a 10x reduction in model size, and 70% latency improvement. For query rephrasal, fine-tuning yielded a 3.7% gain in accuracy and a 40% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale.
arXiv:2510.27051v1 Announce Type: new
Abstract: Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA’s Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25%) and query rephrasal errors (3.2%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96% accuracy, a 10x reduction in model size, and 70% latency improvement. For query rephrasal, fine-tuning yielded a 3.7% gain in accuracy and a 40% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale. Read More
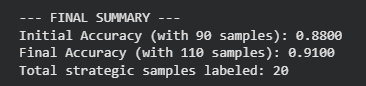
How to Build Supervised AI Models When You Don’t Have Annotated DataMarkTechPost One of the biggest challenges in real-world machine learning is that supervised models require labeled data—yet in many practical scenarios, the data you start with is almost always unlabeled. Manually annotating thousands of samples isn’t just slow; it’s expensive, tedious, and often impractical. This is where active learning becomes a game-changer. Active learning is a
The post How to Build Supervised AI Models When You Don’t Have Annotated Data appeared first on MarkTechPost.
One of the biggest challenges in real-world machine learning is that supervised models require labeled data—yet in many practical scenarios, the data you start with is almost always unlabeled. Manually annotating thousands of samples isn’t just slow; it’s expensive, tedious, and often impractical. This is where active learning becomes a game-changer. Active learning is a
The post How to Build Supervised AI Models When You Don’t Have Annotated Data appeared first on MarkTechPost. Read More
Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU ClustersMarkTechPost How can AI teams run Tinker style reinforcement learning on large language models using their own infrastructure with a single unified engine? Anyscale and NovaSky (UC Berkeley) Team releases SkyRL tx v0.1.0 that gives developers a way to run a Tinker compatible training and inference engine directly on their own hardware, while keeping the same
The post Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU Clusters appeared first on MarkTechPost.
How can AI teams run Tinker style reinforcement learning on large language models using their own infrastructure with a single unified engine? Anyscale and NovaSky (UC Berkeley) Team releases SkyRL tx v0.1.0 that gives developers a way to run a Tinker compatible training and inference engine directly on their own hardware, while keeping the same
The post Anyscale and NovaSky Team Releases SkyRL tx v0.1.0: Bringing Tinker Compatible Reinforcement Learning RL Engine To Local GPU Clusters appeared first on MarkTechPost. Read More
AWS and OpenAI announce multi-year strategic partnershipOpenAI News OpenAI and AWS have entered a multi-year, $38 billion partnership to scale advanced AI workloads. AWS will provide world-class infrastructure and compute capacity to power OpenAI’s next generation of models.
OpenAI and AWS have entered a multi-year, $38 billion partnership to scale advanced AI workloads. AWS will provide world-class infrastructure and compute capacity to power OpenAI’s next generation of models. Read More

AI browsers are a significant security threatAI News Among the explosion of AI systems, AI web browsers such as Fellou and Comet from Perplexity have begun to make appearances on the corporate desktop. Such applications are described as the next evolution of the humble browser, and come with AI features built in; they can read and summarise web pages – and, at their
The post AI browsers are a significant security threat appeared first on AI News.
Among the explosion of AI systems, AI web browsers such as Fellou and Comet from Perplexity have begun to make appearances on the corporate desktop. Such applications are described as the next evolution of the humble browser, and come with AI features built in; they can read and summarise web pages – and, at their
The post AI browsers are a significant security threat appeared first on AI News. Read More

The Complete Guide to Using Google AI StudioKDnuggets Google AI Studio offers an intuitive, web-based platform for prototyping and deploying AI solutions with the latest Gemini models. It streamlines the development process, allowing users to experiment with prompts, analyze outputs, and export production-ready code effortlessly.
Google AI Studio offers an intuitive, web-based platform for prototyping and deploying AI solutions with the latest Gemini models. It streamlines the development process, allowing users to experiment with prompts, analyze outputs, and export production-ready code effortlessly. Read More
Building a Multimodal RAG That Responds with Text, Images, and Tables from SourcesTowards Data Science Why do few chatbots return figures from source documents in their responses?
The post Building a Multimodal RAG That Responds with Text, Images, and Tables from Sources appeared first on Towards Data Science.
Why do few chatbots return figures from source documents in their responses?
The post Building a Multimodal RAG That Responds with Text, Images, and Tables from Sources appeared first on Towards Data Science. Read More
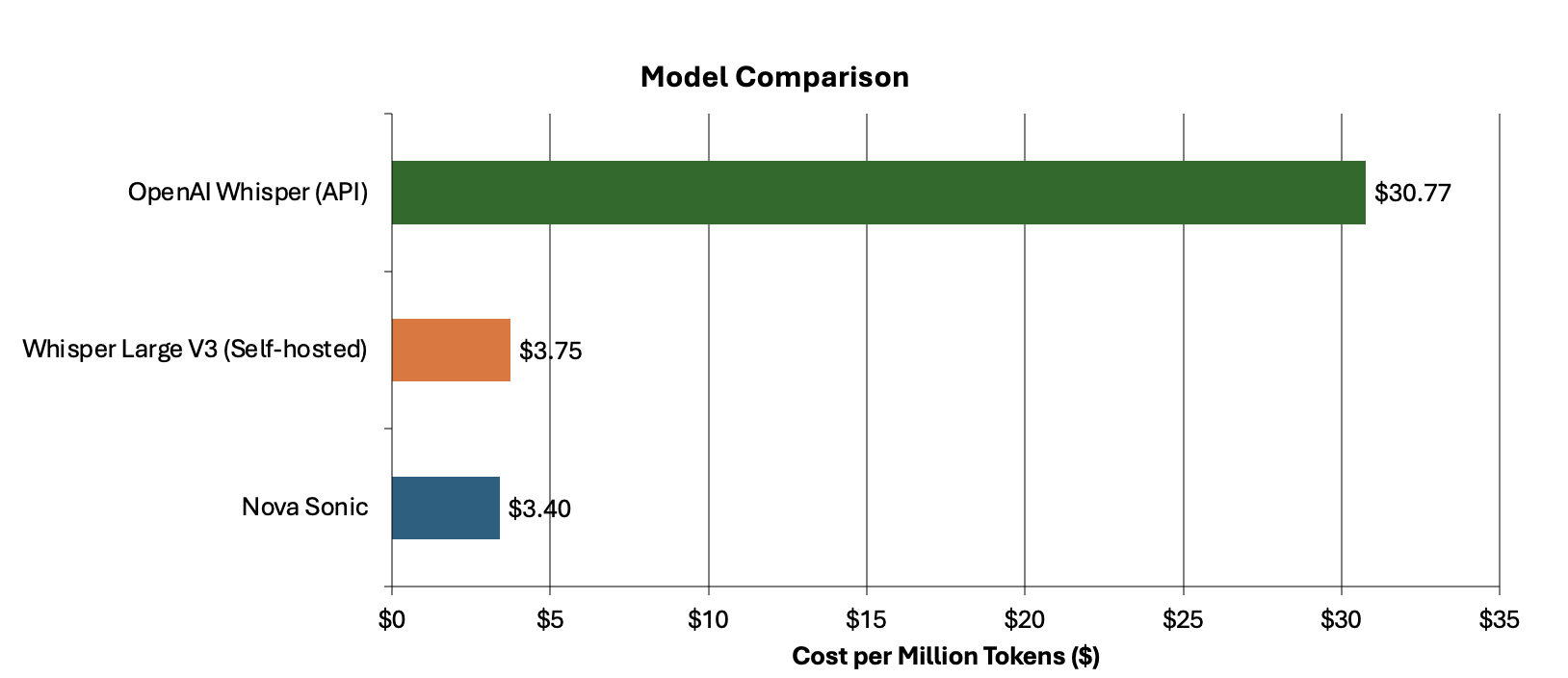
How Switchboard, MD automates real-time call transcription in clinical contact centers with Amazon Nova SonicArtificial Intelligence In this post, we examine the specific challenges Switchboard, MD faced with scaling transcription accuracy and cost-effectiveness in clinical environments, their evaluation process for selecting the right transcription solution, and the technical architecture they implemented using Amazon Connect and Amazon Kinesis Video Streams. This post details the impressive results achieved and demonstrates how they were able to use this foundation to automate EMR matching and give healthcare staff more time to focus on patient care.
In this post, we examine the specific challenges Switchboard, MD faced with scaling transcription accuracy and cost-effectiveness in clinical environments, their evaluation process for selecting the right transcription solution, and the technical architecture they implemented using Amazon Connect and Amazon Kinesis Video Streams. This post details the impressive results achieved and demonstrates how they were able to use this foundation to automate EMR matching and give healthcare staff more time to focus on patient care. Read More

What’s on My Bookmarks Bar: Data Science EditionKDnuggets Save time by keeping top resources and tools at your fingertips.
Save time by keeping top resources and tools at your fingertips. Read More