
What Building My First Dashboard Taught Me About Data StorytellingTowards Data Science Why clarity beats complexity when turning data into stories people actually understand
The post What Building My First Dashboard Taught Me About Data Storytelling appeared first on Towards Data Science.
Why clarity beats complexity when turning data into stories people actually understand
The post What Building My First Dashboard Taught Me About Data Storytelling appeared first on Towards Data Science. Read More
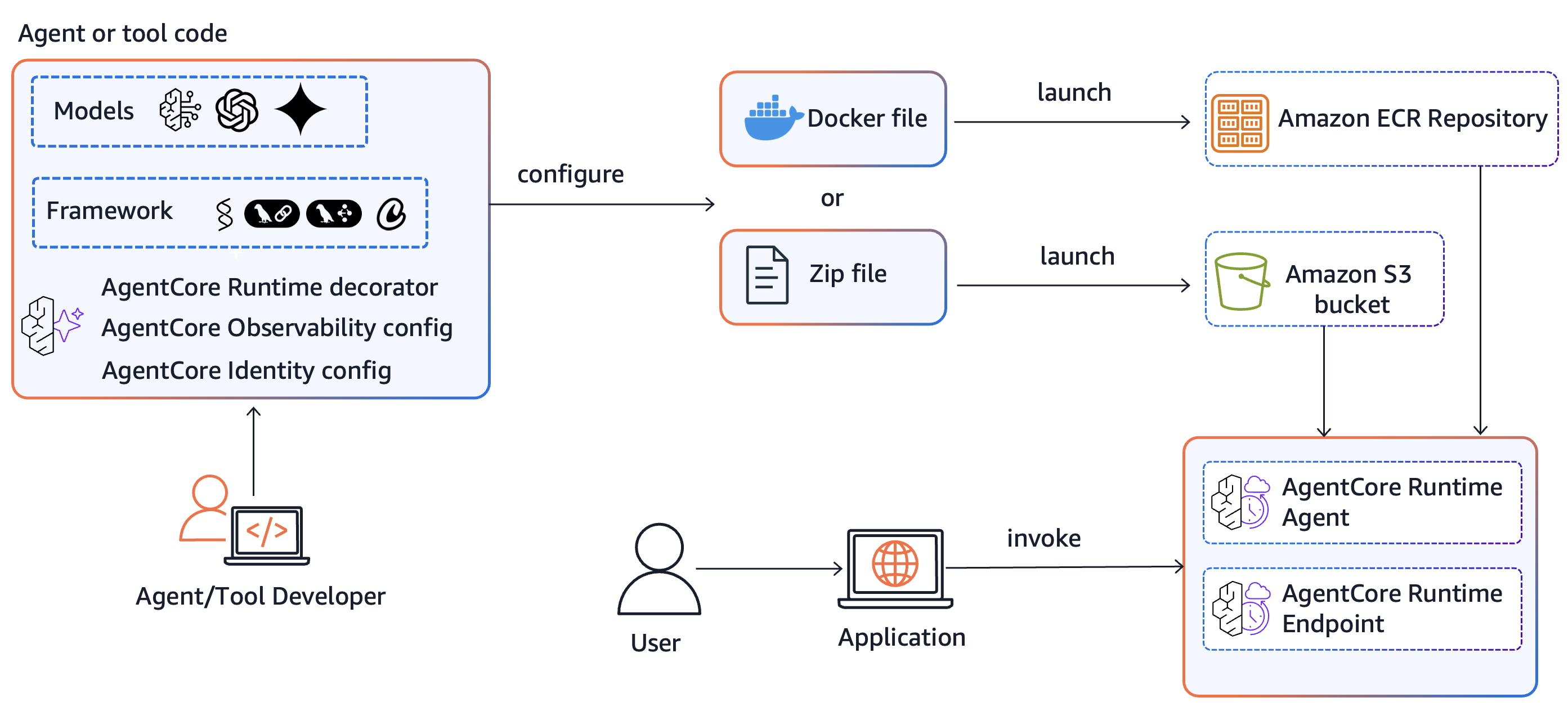
Iterate faster with Amazon Bedrock AgentCore Runtime direct code deploymentArtificial Intelligence Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. Amazon Bedrock AgentCore Runtime is a fully managed service of Bedrock AgentCore, which provides low latency serverless environments to deploy agents and tools. It provides session isolation, supports multiple agent frameworks including popular open-source frameworks, and handles multimodal
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. Amazon Bedrock AgentCore Runtime is a fully managed service of Bedrock AgentCore, which provides low latency serverless environments to deploy agents and tools. It provides session isolation, supports multiple agent frameworks including popular open-source frameworks, and handles multimodal Read More
What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later Towards Data Science
What to Do When Your Credit Risk Model Works Today, but Breaks Six Months LaterTowards Data Science Here’s why it happens — and how to fix it
The post What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later appeared first on Towards Data Science.
Here’s why it happens — and how to fix it
The post What to Do When Your Credit Risk Model Works Today, but Breaks Six Months Later appeared first on Towards Data Science. Read More
Train a Humanoid Robot with AI and PythonTowards Data Science 3D simulations and Reinforcement Learning with MuJoCo and Gym
The post Train a Humanoid Robot with AI and Python appeared first on Towards Data Science.
3D simulations and Reinforcement Learning with MuJoCo and Gym
The post Train a Humanoid Robot with AI and Python appeared first on Towards Data Science. Read More

Beginner’s Guide to Data Extraction with LangExtract and LLMsKDnuggets If you need to pull specific data from text, LangExtract offers a fast, flexible, and beginner‑friendly way to do it.
If you need to pull specific data from text, LangExtract offers a fast, flexible, and beginner‑friendly way to do it. Read More

Cloud 101 for Business Owners (Sponsored)KDnuggets If you’ve been hearing about “the cloud” for years but still aren’t sure what it means for your business, we get it. Let’s cut through the noise.
If you’ve been hearing about “the cloud” for years but still aren’t sure what it means for your business, we get it. Let’s cut through the noise. Read More
Elastic Architecture Search for Efficient Language Modelscs.AI updates on arXiv.org arXiv:2510.27037v1 Announce Type: cross
Abstract: As large pre-trained language models become increasingly critical to natural language understanding (NLU) tasks, their substantial computational and memory requirements have raised significant economic and environmental concerns. Addressing these challenges, this paper introduces the Elastic Language Model (ELM), a novel neural architecture search (NAS) method optimized for compact language models. ELM extends existing NAS approaches by introducing a flexible search space with efficient transformer blocks and dynamic modules for dimension and head number adjustment. These innovations enhance the efficiency and flexibility of the search process, which facilitates more thorough and effective exploration of model architectures. We also introduce novel knowledge distillation losses that preserve the unique characteristics of each block, in order to improve the discrimination between architectural choices during the search process. Experiments on masked language modeling and causal language modeling tasks demonstrate that models discovered by ELM significantly outperform existing methods.
arXiv:2510.27037v1 Announce Type: cross
Abstract: As large pre-trained language models become increasingly critical to natural language understanding (NLU) tasks, their substantial computational and memory requirements have raised significant economic and environmental concerns. Addressing these challenges, this paper introduces the Elastic Language Model (ELM), a novel neural architecture search (NAS) method optimized for compact language models. ELM extends existing NAS approaches by introducing a flexible search space with efficient transformer blocks and dynamic modules for dimension and head number adjustment. These innovations enhance the efficiency and flexibility of the search process, which facilitates more thorough and effective exploration of model architectures. We also introduce novel knowledge distillation losses that preserve the unique characteristics of each block, in order to improve the discrimination between architectural choices during the search process. Experiments on masked language modeling and causal language modeling tasks demonstrate that models discovered by ELM significantly outperform existing methods. Read More
A Systematic Literature Review of Spatio-Temporal Graph Neural Network Models for Time Series Forecasting and Classificationcs.AI updates on arXiv.org arXiv:2410.22377v3 Announce Type: replace-cross
Abstract: In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture, at once, dependencies among variables and across time points. The objective of this systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and 366 papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive review of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in their studies. To the best of our knowledge, this is the first and broadest systematic literature review presenting a detailed comparison of results from current spatio-temporal GNN models applied to different domains. In its final part, this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability. This paper is complemented by a GitHub repository at https://github.com/FlaGer99/SLR-Spatio-Temporal-GNN.git providing additional interactive tools to further explore the presented findings.
arXiv:2410.22377v3 Announce Type: replace-cross
Abstract: In recent years, spatio-temporal graph neural networks (GNNs) have attracted considerable interest in the field of time series analysis, due to their ability to capture, at once, dependencies among variables and across time points. The objective of this systematic literature review is hence to provide a comprehensive overview of the various modeling approaches and application domains of GNNs for time series classification and forecasting. A database search was conducted, and 366 papers were selected for a detailed examination of the current state-of-the-art in the field. This examination is intended to offer to the reader a comprehensive review of proposed models, links to related source code, available datasets, benchmark models, and fitting results. All this information is hoped to assist researchers in their studies. To the best of our knowledge, this is the first and broadest systematic literature review presenting a detailed comparison of results from current spatio-temporal GNN models applied to different domains. In its final part, this review discusses current limitations and challenges in the application of spatio-temporal GNNs, such as comparability, reproducibility, explainability, poor information capacity, and scalability. This paper is complemented by a GitHub repository at https://github.com/FlaGer99/SLR-Spatio-Temporal-GNN.git providing additional interactive tools to further explore the presented findings. Read More

Data Observability in Analytics: Tools, Techniques, and Why It MattersKDnuggets Data analytics without observability is nothing. Learn about its importance, techniques, and tools for implementation.
Data analytics without observability is nothing. Learn about its importance, techniques, and tools for implementation. Read More
Artificial Empathy: AI based Mental Healthcs.AI updates on arXiv.org arXiv:2506.00081v2 Announce Type: replace-cross
Abstract: Many people suffer from mental health problems but not everyone seeks professional help or has access to mental health care. AI chatbots have increasingly become a go-to for individuals who either have mental disorders or simply want someone to talk to. This paper presents a study on participants who have previously used chatbots and a scenario-based testing of large language model (LLM) chatbots. Our findings indicate that AI chatbots were primarily utilized as a “Five minute therapist” or as a non-judgmental companion. Participants appreciated the anonymity and lack of judgment from chatbots. However, there were concerns about privacy and the security of sensitive information. The scenario-based testing of LLM chatbots highlighted additional issues. Some chatbots were consistently reassuring, used emojis and names to add a personal touch, and were quick to suggest seeking professional help. However, there were limitations such as inconsistent tone, occasional inappropriate responses (e.g., casual or romantic), and a lack of crisis sensitivity, particularly in recognizing red flag language and escalating responses appropriately. These findings can inform both the technology and mental health care industries on how to better utilize AI chatbots to support individuals during challenging emotional periods.
arXiv:2506.00081v2 Announce Type: replace-cross
Abstract: Many people suffer from mental health problems but not everyone seeks professional help or has access to mental health care. AI chatbots have increasingly become a go-to for individuals who either have mental disorders or simply want someone to talk to. This paper presents a study on participants who have previously used chatbots and a scenario-based testing of large language model (LLM) chatbots. Our findings indicate that AI chatbots were primarily utilized as a “Five minute therapist” or as a non-judgmental companion. Participants appreciated the anonymity and lack of judgment from chatbots. However, there were concerns about privacy and the security of sensitive information. The scenario-based testing of LLM chatbots highlighted additional issues. Some chatbots were consistently reassuring, used emojis and names to add a personal touch, and were quick to suggest seeking professional help. However, there were limitations such as inconsistent tone, occasional inappropriate responses (e.g., casual or romantic), and a lack of crisis sensitivity, particularly in recognizing red flag language and escalating responses appropriately. These findings can inform both the technology and mental health care industries on how to better utilize AI chatbots to support individuals during challenging emotional periods. Read More