
TDS Newsletter: The Theory and Practice of Using AI EffectivelyTowards Data Science When we encounter a new technology — say, LLM applications — some of us tend to jump right in, sleeves rolled up, impatient to start tinkering. Others prefer a more cautious approach: reading a few relevant research papers, or browsing through a bunch of blog posts, with the goal of understanding the context in which these tools
The post TDS Newsletter: The Theory and Practice of Using AI Effectively appeared first on Towards Data Science.
When we encounter a new technology — say, LLM applications — some of us tend to jump right in, sleeves rolled up, impatient to start tinkering. Others prefer a more cautious approach: reading a few relevant research papers, or browsing through a bunch of blog posts, with the goal of understanding the context in which these tools
The post TDS Newsletter: The Theory and Practice of Using AI Effectively appeared first on Towards Data Science. Read More

Free AI and Data Courses with 365 Data Science— 100% Unlimited Access until Nov 21KDnuggets Begin your AI and data journey for free at 365 Data Science.
Begin your AI and data journey for free at 365 Data Science. Read More
Transform your MCP architecture: Unite MCP servers through AgentCore Gateway Artificial Intelligence
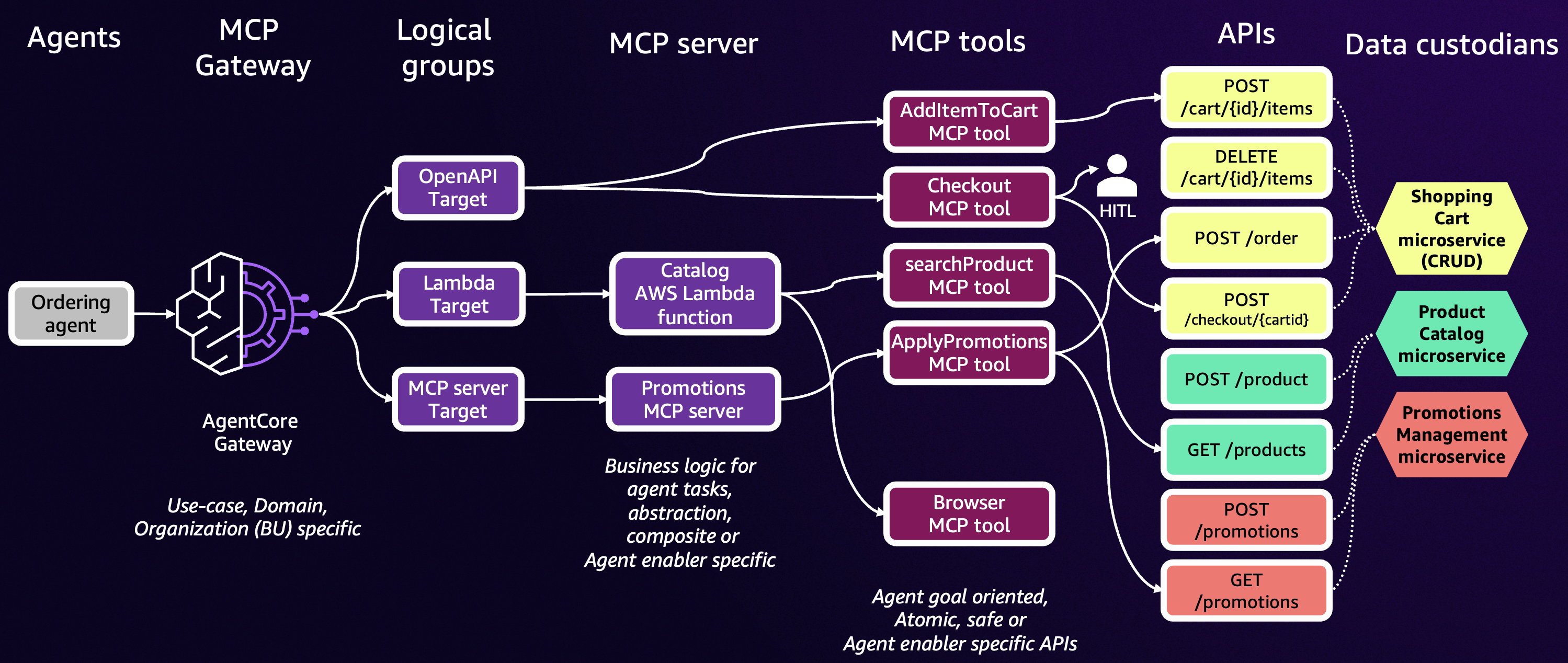
Transform your MCP architecture: Unite MCP servers through AgentCore GatewayArtificial Intelligence Earlier this year, we introduced Amazon Bedrock AgentCore Gateway, a fully managed service that serves as a centralized MCP tool server, providing a unified interface where agents can discover, access, and invoke tools. Today, we’re extending support for existing MCP servers as a new target type in AgentCore Gateway. With this capability, you can group multiple task-specific MCP servers aligned to agent goals behind a single, manageable MCP gateway interface. This reduces the operational complexity of maintaining separate gateways, while providing the same centralized tool and authentication management that existed for REST APIs and AWS Lambda functions.
Earlier this year, we introduced Amazon Bedrock AgentCore Gateway, a fully managed service that serves as a centralized MCP tool server, providing a unified interface where agents can discover, access, and invoke tools. Today, we’re extending support for existing MCP servers as a new target type in AgentCore Gateway. With this capability, you can group multiple task-specific MCP servers aligned to agent goals behind a single, manageable MCP gateway interface. This reduces the operational complexity of maintaining separate gateways, while providing the same centralized tool and authentication management that existed for REST APIs and AWS Lambda functions. Read More

Exclusive: Dubai’s Digital Government chief says speed trumps spending in AI efficiency race AI News
Exclusive: Dubai’s Digital Government chief says speed trumps spending in AI efficiency raceAI News When Dubai launched its State of AI Report in April 2025, revealing over 100 high-impact AI use cases, the emirate wasn’t just showcasing technological prowess—it was making a calculated bet that speed, not spending, would determine which cities win the global race for AI-powered governance. In an exclusive interview, Matar Al Hemeiri, Chief Executive of Digital Dubai
The post Exclusive: Dubai’s Digital Government chief says speed trumps spending in AI efficiency race appeared first on AI News.
When Dubai launched its State of AI Report in April 2025, revealing over 100 high-impact AI use cases, the emirate wasn’t just showcasing technological prowess—it was making a calculated bet that speed, not spending, would determine which cities win the global race for AI-powered governance. In an exclusive interview, Matar Al Hemeiri, Chief Executive of Digital Dubai
The post Exclusive: Dubai’s Digital Government chief says speed trumps spending in AI efficiency race appeared first on AI News. Read More
Expected Value Analysis in AI Product ManagementTowards Data Science An introduction to key concepts and practical applications
The post Expected Value Analysis in AI Product Management appeared first on Towards Data Science.
An introduction to key concepts and practical applications
The post Expected Value Analysis in AI Product Management appeared first on Towards Data Science. Read More

Using NotebookLM to Tackle Tough Questions: Interview Smarter, Not HarderKDnuggets Turn one interview question into a complete learning experience with NotebookLM.
Turn one interview question into a complete learning experience with NotebookLM. Read More

Is AI in a bubble? Succeed despite a market correctionAI News Amid pressure to deploy generative and agentic solutions, a familiar question is surfacing: “Is there an AI bubble, and is it about to burst?” For many organisations, this new wave of generative and agentic AI is still very much in experimental stages. The primary focus, and the low-hanging fruit, has been internal. Most businesses are
The post Is AI in a bubble? Succeed despite a market correction appeared first on AI News.
Amid pressure to deploy generative and agentic solutions, a familiar question is surfacing: “Is there an AI bubble, and is it about to burst?” For many organisations, this new wave of generative and agentic AI is still very much in experimental stages. The primary focus, and the low-hanging fruit, has been internal. Most businesses are
The post Is AI in a bubble? Succeed despite a market correction appeared first on AI News. Read More
The Reinforcement Learning Handbook: A Guide to Foundational QuestionsTowards Data Science Simplifying all the concepts required to master reinforcement learning
The post The Reinforcement Learning Handbook: A Guide to Foundational Questions appeared first on Towards Data Science.
Simplifying all the concepts required to master reinforcement learning
The post The Reinforcement Learning Handbook: A Guide to Foundational Questions appeared first on Towards Data Science. Read More
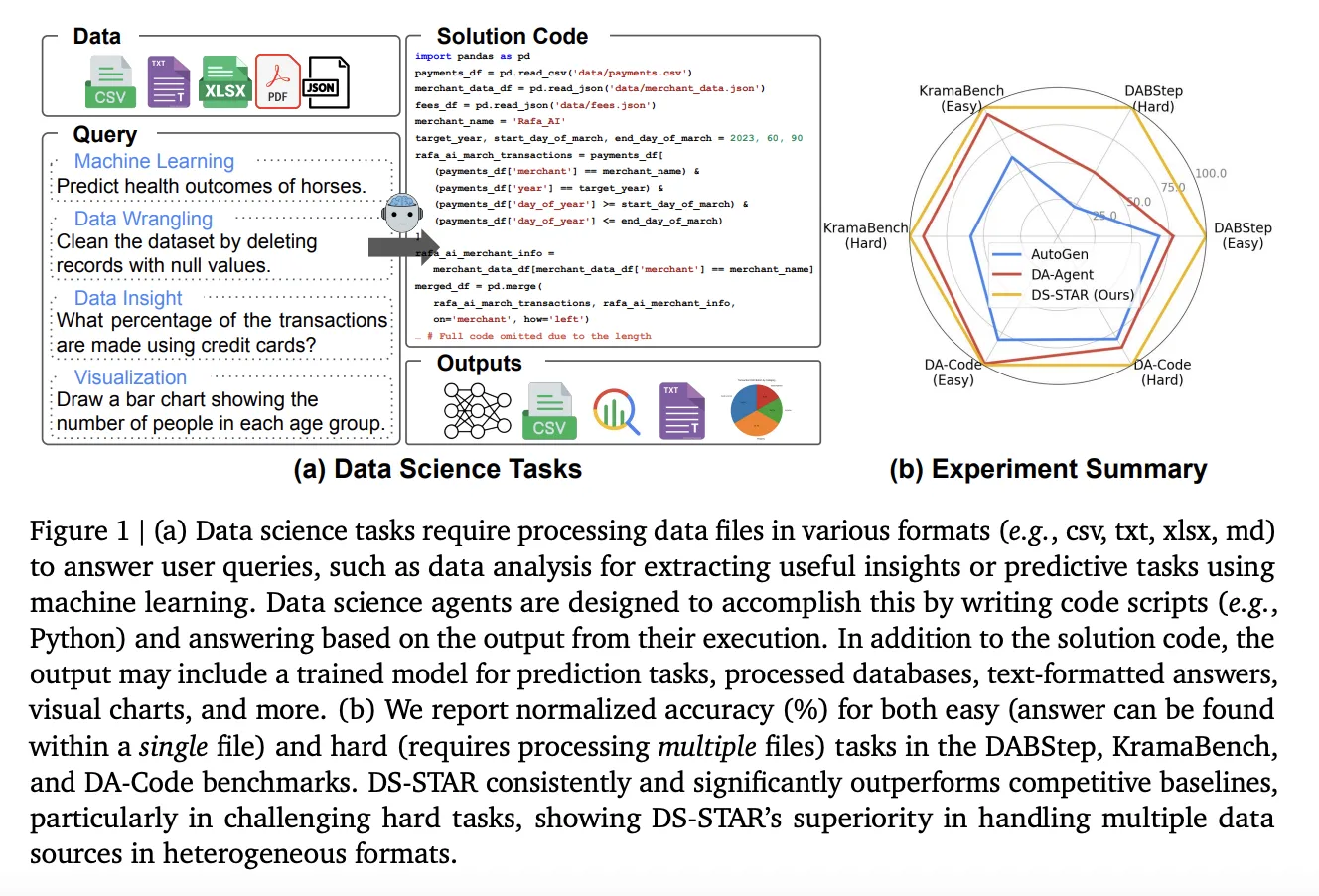
Google AI Introduces DS STAR: A Multi Agent Data Science System That Plans, Codes And Verifies End To End AnalyticsMarkTechPost How do you turn a vague business style question over messy folders of CSV, JSON and text into reliable Python code without a human analyst in the loop? Google researchers introduce DS STAR (Data Science Agent via Iterative Planning and Verification), a multi agent framework that turns open ended data science questions into executable Python
The post Google AI Introduces DS STAR: A Multi Agent Data Science System That Plans, Codes And Verifies End To End Analytics appeared first on MarkTechPost.
How do you turn a vague business style question over messy folders of CSV, JSON and text into reliable Python code without a human analyst in the loop? Google researchers introduce DS STAR (Data Science Agent via Iterative Planning and Verification), a multi agent framework that turns open ended data science questions into executable Python
The post Google AI Introduces DS STAR: A Multi Agent Data Science System That Plans, Codes And Verifies End To End Analytics appeared first on MarkTechPost. Read More

Comparing the Top 6 Inference Runtimes for LLM Serving in 2025MarkTechPost Large language models are now limited less by training and more by how fast and cheaply we can serve tokens under real traffic. That comes down to three implementation details: how the runtime batches requests, how it overlaps prefill and decode, and how it stores and reuses the KV cache. Different engines make different tradeoffs
The post Comparing the Top 6 Inference Runtimes for LLM Serving in 2025 appeared first on MarkTechPost.
Large language models are now limited less by training and more by how fast and cheaply we can serve tokens under real traffic. That comes down to three implementation details: how the runtime batches requests, how it overlaps prefill and decode, and how it stores and reuses the KV cache. Different engines make different tradeoffs
The post Comparing the Top 6 Inference Runtimes for LLM Serving in 2025 appeared first on MarkTechPost. Read More