
Building a Gmail Inbox Management Agent in n8nKDnuggets Learn to create an intelligent email automation system that analyzes, scores, and routes messages based on priority.
Learn to create an intelligent email automation system that analyzes, scores, and routes messages based on priority. Read More

Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the HypeTowards Data Science A perspective on GraphRAG design best practices, challenges and learnings
The post Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the Hype appeared first on Towards Data Science.
A perspective on GraphRAG design best practices, challenges and learnings
The post Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the Hype appeared first on Towards Data Science. Read More
The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example)Towards Data Science A practical use case to describe how the data scientist job changed across three generations of machine learning
The post The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example) appeared first on Towards Data Science.
A practical use case to describe how the data scientist job changed across three generations of machine learning
The post The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example) appeared first on Towards Data Science. Read More

From Hustle to Structure: How to Build Repeatable Processes in Your Business (Sponsored)KDnuggets Transitioning from reactive hustle to proactive structure by building simple, repeatable processes. If you are looking for practical ways to get started in the shift from hustle to structure, this article has you covered.
Transitioning from reactive hustle to proactive structure by building simple, repeatable processes. If you are looking for practical ways to get started in the shift from hustle to structure, this article has you covered. Read More

Top 7 ChatGPT Alternatives You Can Try For FreeKDnuggets Here are the free ChatGPT alternatives I genuinely recommend. They are fast, reliable, and useful for research, coding, brainstorming, and creative work.
Here are the free ChatGPT alternatives I genuinely recommend. They are fast, reliable, and useful for research, coding, brainstorming, and creative work. Read More

The Complete Guide to Building Data Pipelines That Don’t BreakKDnuggets A practical guide to building reliable data pipelines that stay up and running. Learn what breaks them and how to avoid it.
A practical guide to building reliable data pipelines that stay up and running. Learn what breaks them and how to avoid it. Read More
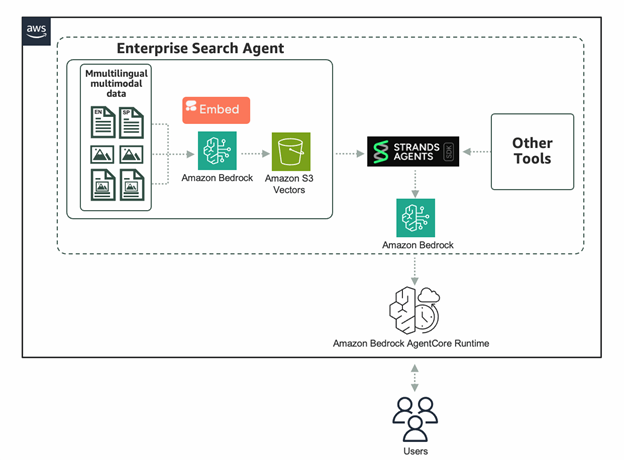
Powering enterprise search with the Cohere Embed 4 multimodal embeddings model in Amazon BedrockArtificial Intelligence The Cohere Embed 4 multimodal embeddings model is now available as a fully managed, serverless option in Amazon Bedrock. In this post, we dive into the benefits and unique capabilities of Embed 4 for enterprise search use cases. We’ll show you how to quickly get started using Embed 4 on Amazon Bedrock, taking advantage of integrations with Strands Agents, S3 Vectors, and Amazon Bedrock AgentCore to build powerful agentic retrieval-augmented generation (RAG) workflows.
The Cohere Embed 4 multimodal embeddings model is now available as a fully managed, serverless option in Amazon Bedrock. In this post, we dive into the benefits and unique capabilities of Embed 4 for enterprise search use cases. We’ll show you how to quickly get started using Embed 4 on Amazon Bedrock, taking advantage of integrations with Strands Agents, S3 Vectors, and Amazon Bedrock AgentCore to build powerful agentic retrieval-augmented generation (RAG) workflows. Read More
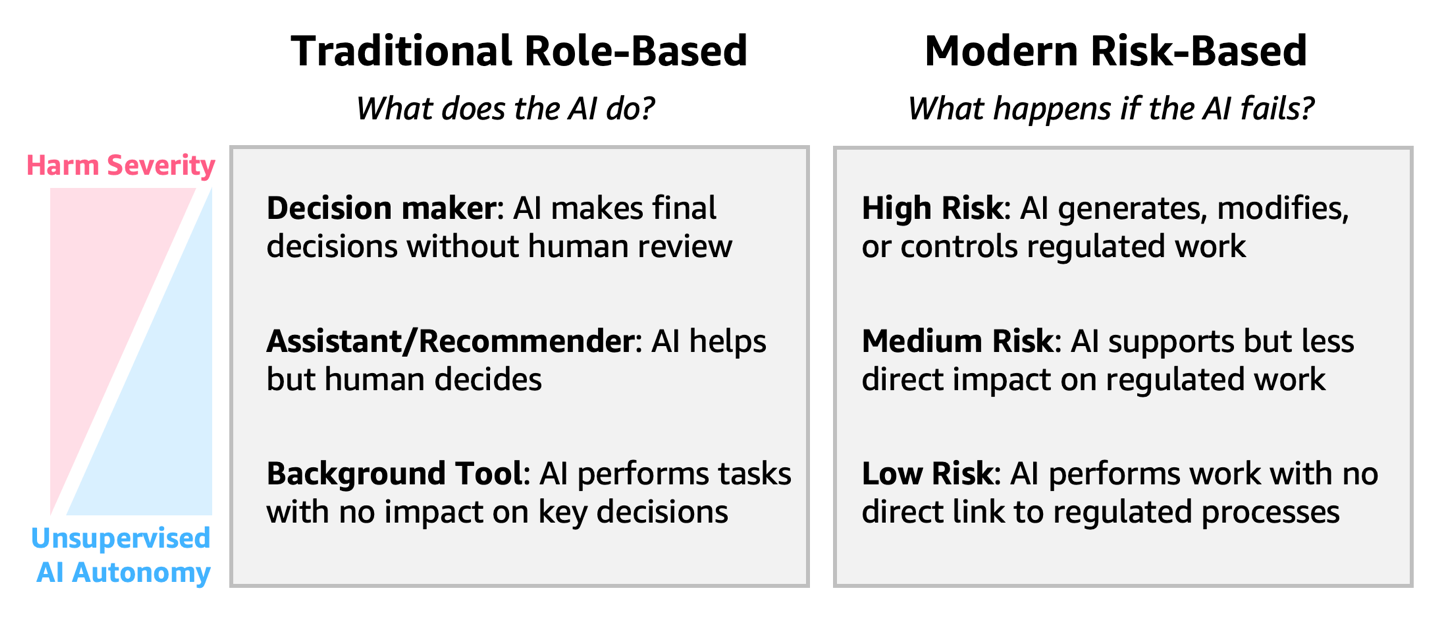
A guide to building AI agents in GxP environmentsArtificial Intelligence The regulatory landscape for GxP compliance is evolving to address the unique characteristics of AI. Traditional Computer System Validation (CSV) approaches, often with uniform validation strategies, are being supplemented by Computer Software Assurance (CSA) frameworks that emphasize flexible risk-based validation methods tailored to each system’s actual impact and complexity (FDA latest guidance). In this post, we cover a risk-based implementation, practical implementation considerations across different risk levels, the AWS shared responsibility model for compliance, and concrete examples of risk mitigation strategies.
The regulatory landscape for GxP compliance is evolving to address the unique characteristics of AI. Traditional Computer System Validation (CSV) approaches, often with uniform validation strategies, are being supplemented by Computer Software Assurance (CSA) frameworks that emphasize flexible risk-based validation methods tailored to each system’s actual impact and complexity (FDA latest guidance). In this post, we cover a risk-based implementation, practical implementation considerations across different risk levels, the AWS shared responsibility model for compliance, and concrete examples of risk mitigation strategies. Read More
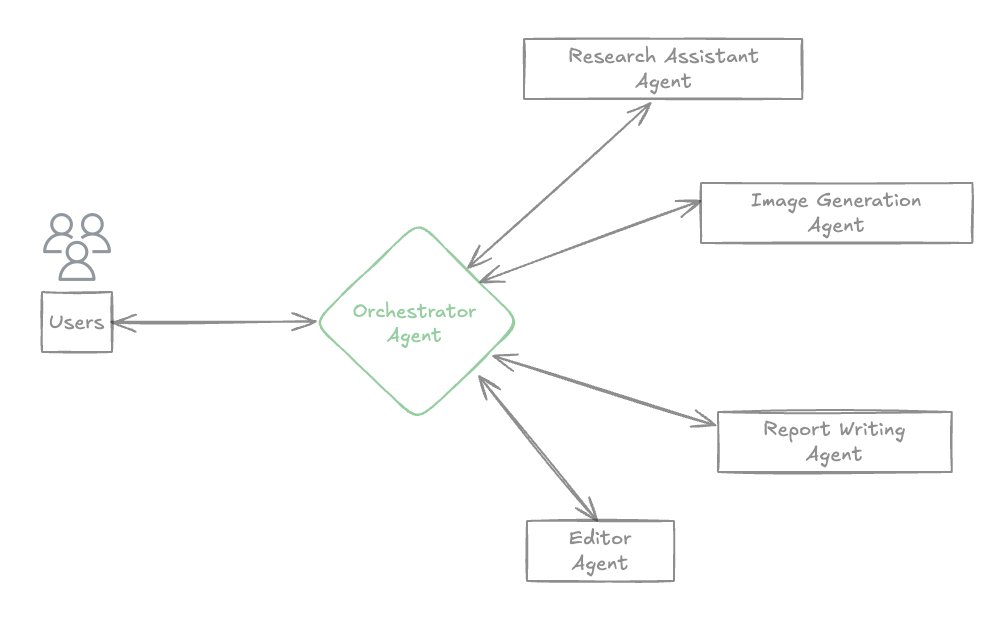
Multi-Agent collaboration patterns with Strands Agents and Amazon NovaArtificial Intelligence In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models.
In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models. Read More

Transform Raw Data Into Real ImpactKDnuggets If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science.
If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science. Read More