
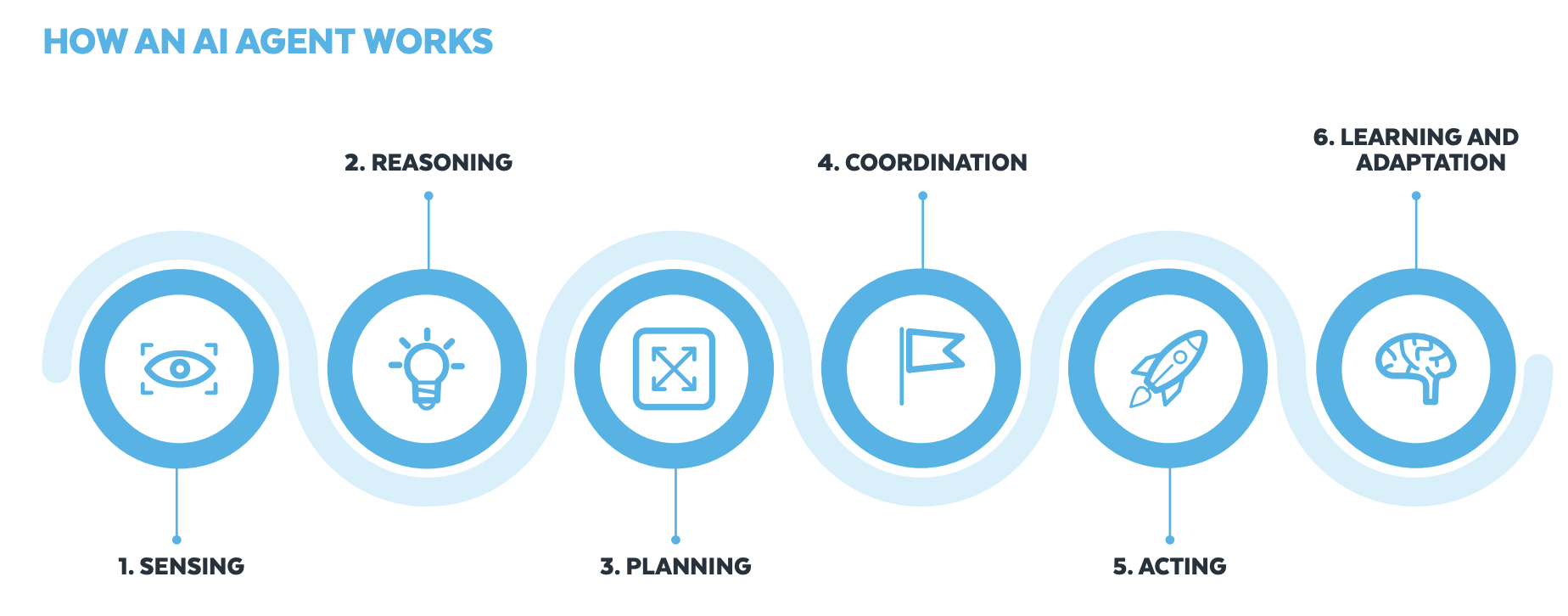
How to Perform Agentic Information RetrievalTowards Data Science Learn how to utilize AI agents to find information in your document corpus
The post How to Perform Agentic Information Retrieval appeared first on Towards Data Science.
Learn how to utilize AI agents to find information in your document corpus
The post How to Perform Agentic Information Retrieval appeared first on Towards Data Science. Read More
Build an agentic solution with Amazon Nova, Snowflake, and LangGraphArtificial Intelligence In this post, we cover how you can use tools from Snowflake AI Data Cloud and Amazon Web Services (AWS) to build generative AI solutions that organizations can use to make data-driven decisions, increase operational efficiency, and ultimately gain a competitive edge.
In this post, we cover how you can use tools from Snowflake AI Data Cloud and Amazon Web Services (AWS) to build generative AI solutions that organizations can use to make data-driven decisions, increase operational efficiency, and ultimately gain a competitive edge. Read More
Developing Human Sexuality in the Age of AITowards Data Science How we learn is changing with generative AI — what does that mean for sex education, consent, and responsibility?
The post Developing Human Sexuality in the Age of AI appeared first on Towards Data Science.
How we learn is changing with generative AI — what does that mean for sex education, consent, and responsibility?
The post Developing Human Sexuality in the Age of AI appeared first on Towards Data Science. Read More
Using Spectrum fine-tuning to improve FM training efficiency on Amazon SageMaker AIArtificial Intelligence In this post you will learn how to use Spectrum to optimize resource use and shorten training times without sacrificing quality, as well as how to implement Spectrum fine-tuning with Amazon SageMaker AI training jobs. We will also discuss the tradeoff between QLoRA and Spectrum fine-tuning, showing that while QLoRA is more resource efficient, Spectrum results in higher performance overall.
In this post you will learn how to use Spectrum to optimize resource use and shorten training times without sacrificing quality, as well as how to implement Spectrum fine-tuning with Amazon SageMaker AI training jobs. We will also discuss the tradeoff between QLoRA and Spectrum fine-tuning, showing that while QLoRA is more resource efficient, Spectrum results in higher performance overall. Read More

An Introduction to Zapier Automations for Data ScientistsKDnuggets Zapier Automations connect your favorite tools and services so that routine tasks don’t eat into your day.
Zapier Automations connect your favorite tools and services so that routine tasks don’t eat into your day. Read More

SC25 showcases the next phase of Dell and NVIDIA’s AI partnershipAI News At SC25, Dell Technologies and NVIDIA introduced new updates to their joint AI platform, aiming to make it easier for organisations to run a wider range of AI workloads, from older models to newer agent-style systems. As more companies scale their AI plans, many run into the same issues. They need to manage a growing
The post SC25 showcases the next phase of Dell and NVIDIA’s AI partnership appeared first on AI News.
At SC25, Dell Technologies and NVIDIA introduced new updates to their joint AI platform, aiming to make it easier for organisations to run a wider range of AI workloads, from older models to newer agent-style systems. As more companies scale their AI plans, many run into the same issues. They need to manage a growing
The post SC25 showcases the next phase of Dell and NVIDIA’s AI partnership appeared first on AI News. Read More
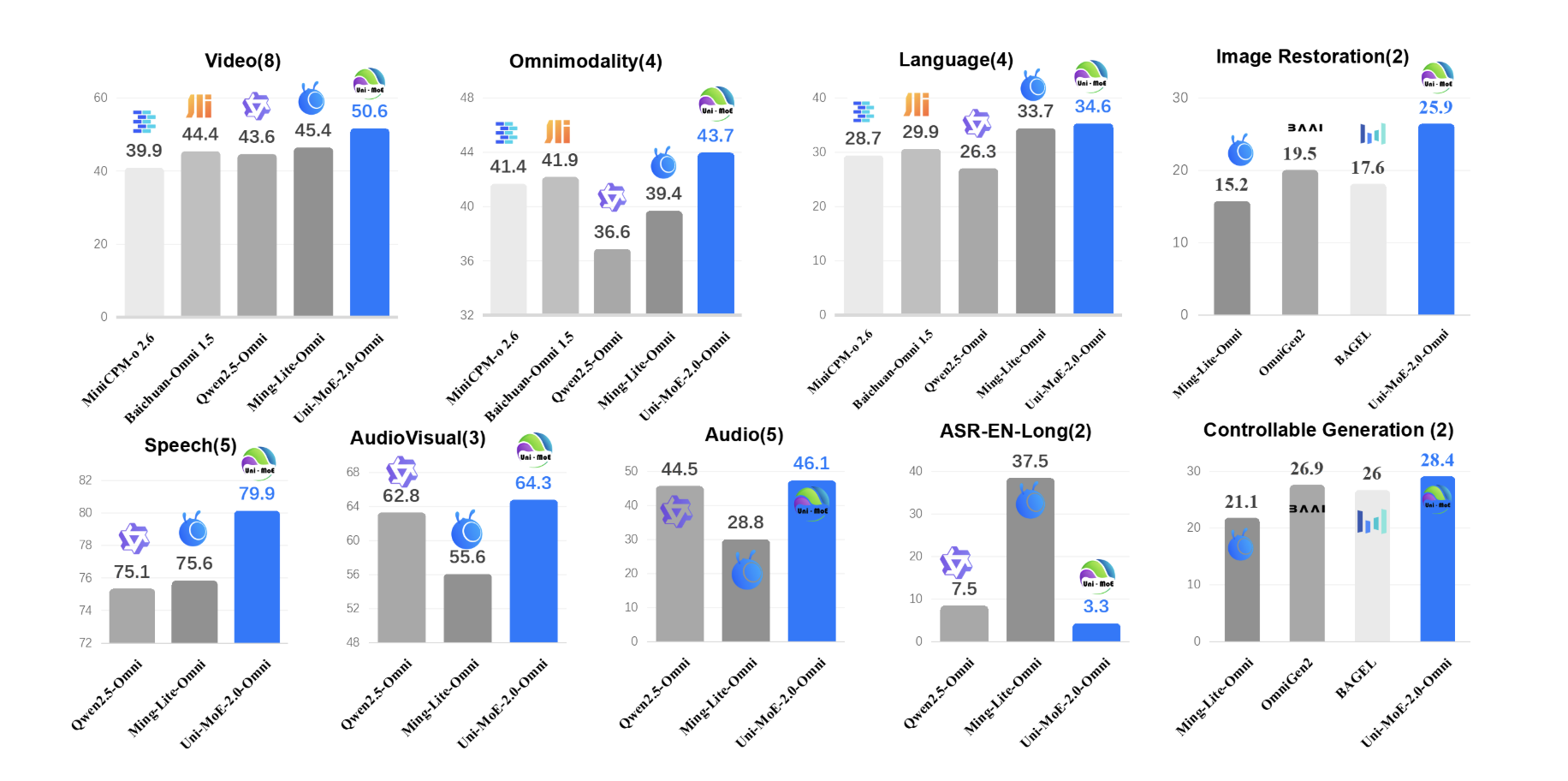
Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video UnderstandingMarkTechPost How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on
The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost.
How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on
The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost. Read More

Build or Buy Your Cybersecurity? Weighing the Pros and Cons (Sponsored)KDnuggets The new million-dollar question for cybersecurity doesn’t have anything to do with fending off the latest type of attack or adopting yet another AI-powered tool.
The new million-dollar question for cybersecurity doesn’t have anything to do with fending off the latest type of attack or adopting yet another AI-powered tool. Read More

AI web search risks: Mitigating business data accuracy threatsAI News Over half of us now use AI to search the web, yet the stubbornly low data accuracy of common tools creates new business risks. While generative AI (GenAI) offers undeniable efficiency gains, a new investigation highlights a disparity between user trust and technical accuracy that poses specific risks to corporate compliance, legal standing, and financial
The post AI web search risks: Mitigating business data accuracy threats appeared first on AI News.
Over half of us now use AI to search the web, yet the stubbornly low data accuracy of common tools creates new business risks. While generative AI (GenAI) offers undeniable efficiency gains, a new investigation highlights a disparity between user trust and technical accuracy that poses specific risks to corporate compliance, legal standing, and financial
The post AI web search risks: Mitigating business data accuracy threats appeared first on AI News. Read More
Introducing Google’s File Search ToolTowards Data Science The search giant fires its latest salvo against traditional RAG processing.
The post Introducing Google’s File Search Tool appeared first on Towards Data Science.
The search giant fires its latest salvo against traditional RAG processing.
The post Introducing Google’s File Search Tool appeared first on Towards Data Science. Read More