
Top 7 Open Source AI Coding Models You Are Missing Out OnKDnuggets Stop sending your code to OpenAI or Anthropic. Run these 7 top-tier open-source coding models locally for privacy, control, and zero API costs.
Stop sending your code to OpenAI or Anthropic. Run these 7 top-tier open-source coding models locally for privacy, control, and zero API costs. Read More

Generative AI Will Redesign Cars, But Not the Way Automakers ThinkTowards Data Science Traditional manufacturers are using revolutionary technology for incremental optimization instead of fundamental re-imagination
The post Generative AI Will Redesign Cars, But Not the Way Automakers Think appeared first on Towards Data Science.
Traditional manufacturers are using revolutionary technology for incremental optimization instead of fundamental re-imagination
The post Generative AI Will Redesign Cars, But Not the Way Automakers Think appeared first on Towards Data Science. Read More
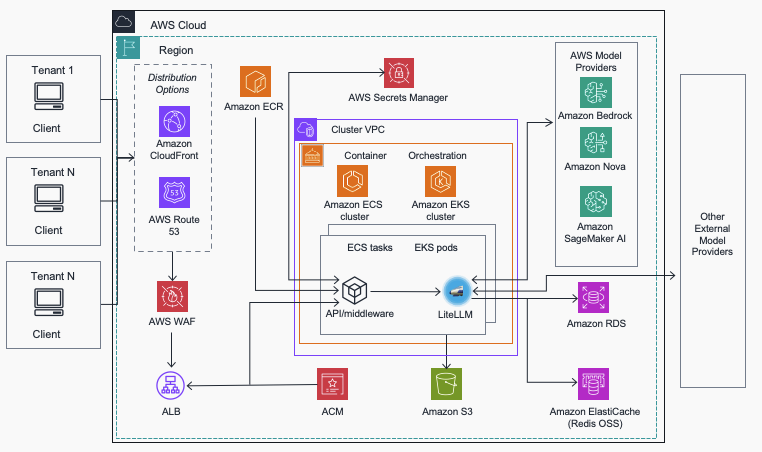
Streamline AI operations with the Multi-Provider Generative AI Gateway reference architectureArtificial Intelligence In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities.
In this post, we introduce the Multi-Provider Generative AI Gateway reference architecture, which provides guidance for deploying LiteLLM into an AWS environment to streamline the management and governance of production generative AI workloads across multiple model providers. This centralized gateway solution addresses common enterprise challenges including provider fragmentation, decentralized governance, operational complexity, and cost management by offering a unified interface that supports Amazon Bedrock, Amazon SageMaker AI, and external providers while maintaining comprehensive security, monitoring, and control capabilities. Read More

Deploy geospatial agents with Foursquare Spatial H3 Hub and Amazon SageMaker AIArtificial Intelligence In this post, you’ll learn how to deploy geospatial AI agents that can answer complex spatial questions in minutes instead of months. By combining Foursquare Spatial H3 Hub’s analysis-ready geospatial data with reasoning models deployed on Amazon SageMaker AI, you can build agents that enable nontechnical domain experts to perform sophisticated spatial analysis through natural language queries—without requiring geographic information system (GIS) expertise or custom data engineering pipelines.
In this post, you’ll learn how to deploy geospatial AI agents that can answer complex spatial questions in minutes instead of months. By combining Foursquare Spatial H3 Hub’s analysis-ready geospatial data with reasoning models deployed on Amazon SageMaker AI, you can build agents that enable nontechnical domain experts to perform sophisticated spatial analysis through natural language queries—without requiring geographic information system (GIS) expertise or custom data engineering pipelines. Read More
Modern DataFrames in Python: A Hands-On Tutorial with Polars and DuckDBTowards Data Science How I learned to handle growing datasets without slowing down my entire workflow
The post Modern DataFrames in Python: A Hands-On Tutorial with Polars and DuckDB appeared first on Towards Data Science.
How I learned to handle growing datasets without slowing down my entire workflow
The post Modern DataFrames in Python: A Hands-On Tutorial with Polars and DuckDB appeared first on Towards Data Science. Read More
How To Build a Graph-Based Recommendation Engine Using EDG and Neo4jTowards Data Science Use a shared taxonomy to connect RDF and property graphs—and power smarter recommendations with inferencing
The post How To Build a Graph-Based Recommendation Engine Using EDG and Neo4j appeared first on Towards Data Science.
Use a shared taxonomy to connect RDF and property graphs—and power smarter recommendations with inferencing
The post How To Build a Graph-Based Recommendation Engine Using EDG and Neo4j appeared first on Towards Data Science. Read More
Task Specific Sharpness Aware O-RAN Resource Management using Multi Agent Reinforcement Learningcs.AI updates on arXiv.org arXiv:2511.15002v1 Announce Type: new
Abstract: Next-generation networks utilize the Open Radio Access Network (O-RAN) architecture to enable dynamic resource management, facilitated by the RAN Intelligent Controller (RIC). While deep reinforcement learning (DRL) models show promise in optimizing network resources, they often struggle with robustness and generalizability in dynamic environments. This paper introduces a novel resource management approach that enhances the Soft Actor Critic (SAC) algorithm with Sharpness-Aware Minimization (SAM) in a distributed Multi-Agent RL (MARL) framework. Our method introduces an adaptive and selective SAM mechanism, where regularization is explicitly driven by temporal-difference (TD)-error variance, ensuring that only agents facing high environmental complexity are regularized. This targeted strategy reduces unnecessary overhead, improves training stability, and enhances generalization without sacrificing learning efficiency. We further incorporate a dynamic $rho$ scheduling scheme to refine the exploration-exploitation trade-off across agents. Experimental results show our method significantly outperforms conventional DRL approaches, yielding up to a $22%$ improvement in resource allocation efficiency and ensuring superior QoS satisfaction across diverse O-RAN slices.
arXiv:2511.15002v1 Announce Type: new
Abstract: Next-generation networks utilize the Open Radio Access Network (O-RAN) architecture to enable dynamic resource management, facilitated by the RAN Intelligent Controller (RIC). While deep reinforcement learning (DRL) models show promise in optimizing network resources, they often struggle with robustness and generalizability in dynamic environments. This paper introduces a novel resource management approach that enhances the Soft Actor Critic (SAC) algorithm with Sharpness-Aware Minimization (SAM) in a distributed Multi-Agent RL (MARL) framework. Our method introduces an adaptive and selective SAM mechanism, where regularization is explicitly driven by temporal-difference (TD)-error variance, ensuring that only agents facing high environmental complexity are regularized. This targeted strategy reduces unnecessary overhead, improves training stability, and enhances generalization without sacrificing learning efficiency. We further incorporate a dynamic $rho$ scheduling scheme to refine the exploration-exploitation trade-off across agents. Experimental results show our method significantly outperforms conventional DRL approaches, yielding up to a $22%$ improvement in resource allocation efficiency and ensuring superior QoS satisfaction across diverse O-RAN slices. Read More
Project Rachel: Can an AI Become a Scholarly Author?cs.AI updates on arXiv.org arXiv:2511.14819v1 Announce Type: new
Abstract: This paper documents Project Rachel, an action research study that created and tracked a complete AI academic identity named Rachel So. Through careful publication of AI-generated research papers, we investigate how the scholarly ecosystem responds to AI authorship. Rachel So published 10+ papers between March and October 2025, was cited, and received a peer review invitation. We discuss the implications of AI authorship on publishers, researchers, and the scientific system at large. This work contributes empirical action research data to the necessary debate about the future of scholarly communication with super human, hyper capable AI systems.
arXiv:2511.14819v1 Announce Type: new
Abstract: This paper documents Project Rachel, an action research study that created and tracked a complete AI academic identity named Rachel So. Through careful publication of AI-generated research papers, we investigate how the scholarly ecosystem responds to AI authorship. Rachel So published 10+ papers between March and October 2025, was cited, and received a peer review invitation. We discuss the implications of AI authorship on publishers, researchers, and the scientific system at large. This work contributes empirical action research data to the necessary debate about the future of scholarly communication with super human, hyper capable AI systems. Read More
Multi-Aspect Cross-modal Quantization for Generative Recommendationcs.AI updates on arXiv.org arXiv:2511.15122v1 Announce Type: cross
Abstract: Generative Recommendation (GR) has emerged as a new paradigm in recommender systems. This approach relies on quantized representations to discretize item features, modeling users’ historical interactions as sequences of discrete tokens. Based on these tokenized sequences, GR predicts the next item by employing next-token prediction methods. The challenges of GR lie in constructing high-quality semantic identifiers (IDs) that are hierarchically organized, minimally conflicting, and conducive to effective generative model training. However, current approaches remain limited in their ability to harness multimodal information and to capture the deep and intricate interactions among diverse modalities, both of which are essential for learning high-quality semantic IDs and for effectively training GR models. To address this, we propose Multi-Aspect Cross-modal quantization for generative Recommendation (MACRec), which introduces multimodal information and incorporates it into both semantic ID learning and generative model training from different aspects. Specifically, we first introduce cross-modal quantization during the ID learning process, which effectively reduces conflict rates and thus improves codebook usability through the complementary integration of multimodal information. In addition, to further enhance the generative ability of our GR model, we incorporate multi-aspect cross-modal alignments, including the implicit and explicit alignments. Finally, we conduct extensive experiments on three well-known recommendation datasets to demonstrate the effectiveness of our proposed method.
arXiv:2511.15122v1 Announce Type: cross
Abstract: Generative Recommendation (GR) has emerged as a new paradigm in recommender systems. This approach relies on quantized representations to discretize item features, modeling users’ historical interactions as sequences of discrete tokens. Based on these tokenized sequences, GR predicts the next item by employing next-token prediction methods. The challenges of GR lie in constructing high-quality semantic identifiers (IDs) that are hierarchically organized, minimally conflicting, and conducive to effective generative model training. However, current approaches remain limited in their ability to harness multimodal information and to capture the deep and intricate interactions among diverse modalities, both of which are essential for learning high-quality semantic IDs and for effectively training GR models. To address this, we propose Multi-Aspect Cross-modal quantization for generative Recommendation (MACRec), which introduces multimodal information and incorporates it into both semantic ID learning and generative model training from different aspects. Specifically, we first introduce cross-modal quantization during the ID learning process, which effectively reduces conflict rates and thus improves codebook usability through the complementary integration of multimodal information. In addition, to further enhance the generative ability of our GR model, we incorporate multi-aspect cross-modal alignments, including the implicit and explicit alignments. Finally, we conduct extensive experiments on three well-known recommendation datasets to demonstrate the effectiveness of our proposed method. Read More
Learning Human-Like RL Agents Through Trajectory Optimization With Action Quantizationcs.AI updates on arXiv.org arXiv:2511.15055v1 Announce Type: new
Abstract: Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ.
arXiv:2511.15055v1 Announce Type: new
Abstract: Human-like agents have long been one of the goals in pursuing artificial intelligence. Although reinforcement learning (RL) has achieved superhuman performance in many domains, relatively little attention has been focused on designing human-like RL agents. As a result, many reward-driven RL agents often exhibit unnatural behaviors compared to humans, raising concerns for both interpretability and trustworthiness. To achieve human-like behavior in RL, this paper first formulates human-likeness as trajectory optimization, where the objective is to find an action sequence that closely aligns with human behavior while also maximizing rewards, and adapts the classic receding-horizon control to human-like learning as a tractable and efficient implementation. To achieve this, we introduce Macro Action Quantization (MAQ), a human-like RL framework that distills human demonstrations into macro actions via Vector-Quantized VAE. Experiments on D4RL Adroit benchmarks show that MAQ significantly improves human-likeness, increasing trajectory similarity scores, and achieving the highest human-likeness rankings among all RL agents in the human evaluation study. Our results also demonstrate that MAQ can be easily integrated into various off-the-shelf RL algorithms, opening a promising direction for learning human-like RL agents. Our code is available at https://rlg.iis.sinica.edu.tw/papers/MAQ. Read More