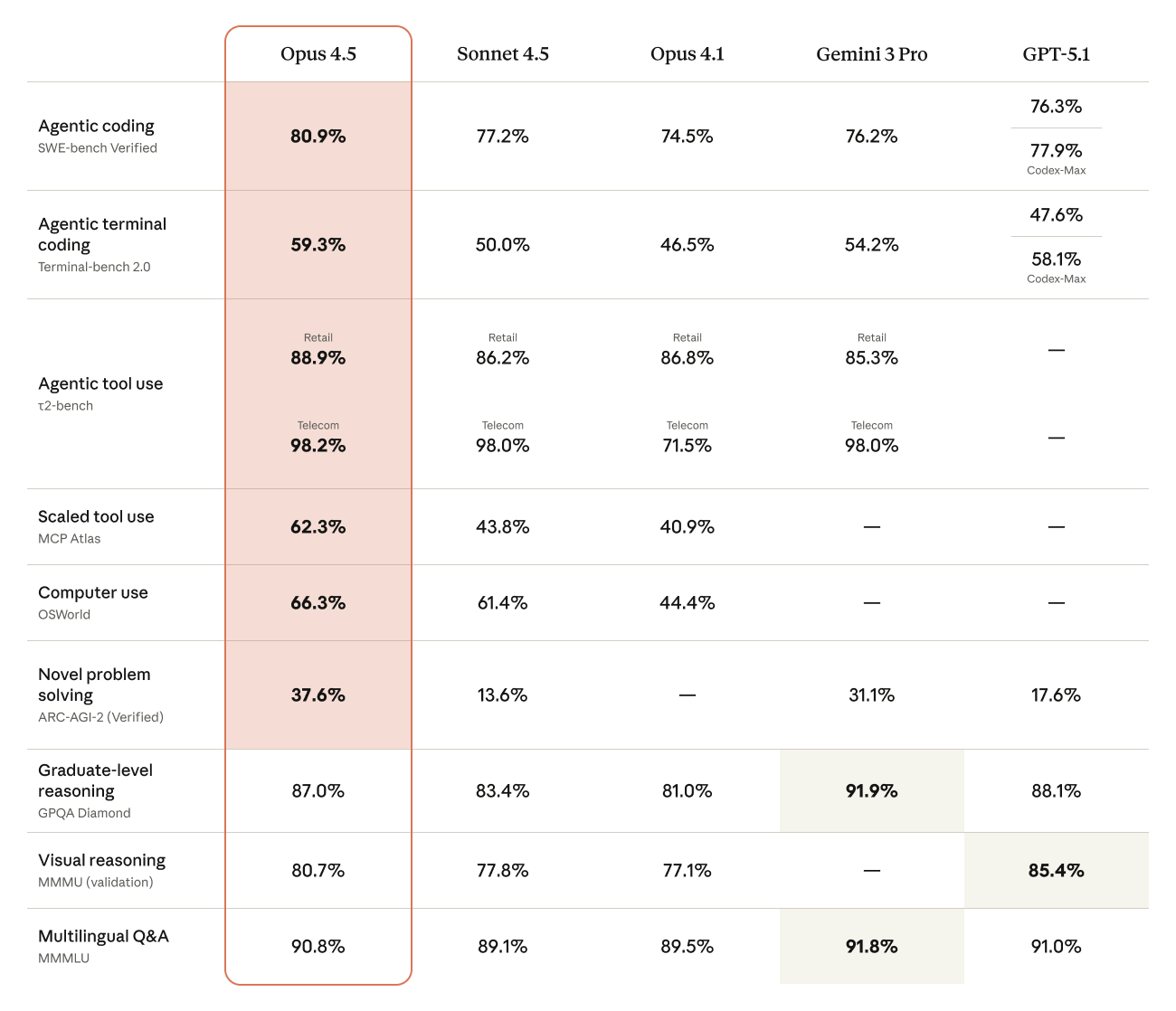
Claude Opus 4.5 now in Amazon BedrockArtificial Intelligence Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock.
Anthropic’s newest foundation model, Claude Opus 4.5, is now available in Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models from leading AI companies. In this post, I’ll show you what makes this model different, walk through key business applications, and demonstrate how to use Opus 4.5’s new tool use capabilities on Amazon Bedrock. Read More

ZAYA1: AI model using AMD GPUs for training hits milestoneAI News Zyphra, AMD, and IBM spent a year testing whether AMD’s GPUs and platform can support large-scale AI model training, and the result is ZAYA1. In partnership, the three companies trained ZAYA1 – described as the first major Mixture-of-Experts foundation model built entirely on AMD GPUs and networking – which they see as proof that the
The post ZAYA1: AI model using AMD GPUs for training hits milestone appeared first on AI News.
Zyphra, AMD, and IBM spent a year testing whether AMD’s GPUs and platform can support large-scale AI model training, and the result is ZAYA1. In partnership, the three companies trained ZAYA1 – described as the first major Mixture-of-Experts foundation model built entirely on AMD GPUs and networking – which they see as proof that the
The post ZAYA1: AI model using AMD GPUs for training hits milestone appeared first on AI News. Read More

My Honest Review on Abacus AI: ChatLLM, DeepAgent & EnterpriseKDnuggets Abacus AI offers the world’s first professional and enterprise AI Super Assistant. It’s an all-in-one AI platform for the top language, image, voic,e and video models along with all the tooling and infrastructure to support them. Abacus can connect to all YOUR data and apply AI to automate work.
Abacus AI offers the world’s first professional and enterprise AI Super Assistant. It’s an all-in-one AI platform for the top language, image, voic,e and video models along with all the tooling and infrastructure to support them. Abacus can connect to all YOUR data and apply AI to automate work. Read More
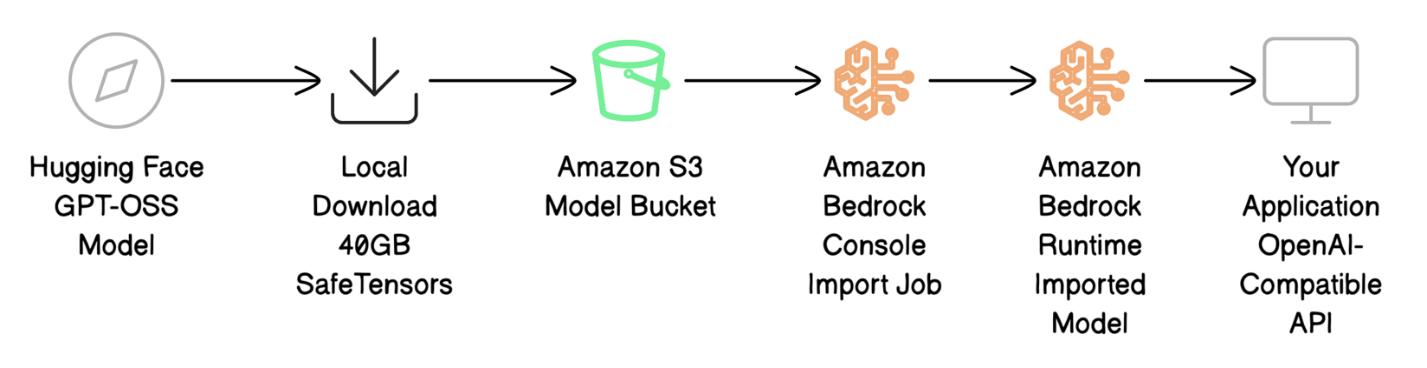
Deploy GPT-OSS models with Amazon Bedrock Custom Model ImportArtificial Intelligence In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications.
In this post, we show how to deploy the GPT-OSS-20B model on Amazon Bedrock using Custom Model Import while maintaining complete API compatibility with your current applications. Read More

Lux + Pandas: Auto-Visualizations for Lazy AnalystsKDnuggets Why write 10 lines of matplotlib code when Lux can show you what you need in one click?
Why write 10 lines of matplotlib code when Lux can show you what you need in one click? Read More

Make.com Automations for Saving Time as a Data ProfessionalKDnuggets Make.com enables data professionals to automate tedious tasks, such as data collection and reporting, without coding, saving hours weekly and enhancing accuracy.
Make.com enables data professionals to automate tedious tasks, such as data collection and reporting, without coding, saving hours weekly and enhancing accuracy. Read More

Preventing Shortcut Learning in Medical Image Analysis through Intermediate Layer Knowledge Distillation from Specialist Teacherscs.AI updates on arXiv.org arXiv:2511.17421v1 Announce Type: cross
Abstract: Deep learning models are prone to learning shortcut solutions to problems using spuriously correlated yet irrelevant features of their training data. In high-risk applications such as medical image analysis, this phenomenon may prevent models from using clinically meaningful features when making predictions, potentially leading to poor robustness and harm to patients. We demonstrate that different types of shortcuts (those that are diffuse and spread throughout the image, as well as those that are localized to specific areas) manifest distinctly across network layers and can, therefore, be more effectively targeted through mitigation strategies that target the intermediate layers. We propose a novel knowledge distillation framework that leverages a teacher network fine-tuned on a small subset of task-relevant data to mitigate shortcut learning in a student network trained on a large dataset corrupted with a bias feature. Through extensive experiments on CheXpert, ISIC 2017, and SimBA datasets using various architectures (ResNet-18, AlexNet, DenseNet-121, and 3D CNNs), we demonstrate consistent improvements over traditional Empirical Risk Minimization, augmentation-based bias-mitigation, and group-based bias-mitigation approaches. In many cases, we achieve comparable performance with a baseline model trained on bias-free data, even on out-of-distribution test data. Our results demonstrate the practical applicability of our approach to real-world medical imaging scenarios where bias annotations are limited and shortcut features are difficult to identify a priori.
arXiv:2511.17421v1 Announce Type: cross
Abstract: Deep learning models are prone to learning shortcut solutions to problems using spuriously correlated yet irrelevant features of their training data. In high-risk applications such as medical image analysis, this phenomenon may prevent models from using clinically meaningful features when making predictions, potentially leading to poor robustness and harm to patients. We demonstrate that different types of shortcuts (those that are diffuse and spread throughout the image, as well as those that are localized to specific areas) manifest distinctly across network layers and can, therefore, be more effectively targeted through mitigation strategies that target the intermediate layers. We propose a novel knowledge distillation framework that leverages a teacher network fine-tuned on a small subset of task-relevant data to mitigate shortcut learning in a student network trained on a large dataset corrupted with a bias feature. Through extensive experiments on CheXpert, ISIC 2017, and SimBA datasets using various architectures (ResNet-18, AlexNet, DenseNet-121, and 3D CNNs), we demonstrate consistent improvements over traditional Empirical Risk Minimization, augmentation-based bias-mitigation, and group-based bias-mitigation approaches. In many cases, we achieve comparable performance with a baseline model trained on bias-free data, even on out-of-distribution test data. Our results demonstrate the practical applicability of our approach to real-world medical imaging scenarios where bias annotations are limited and shortcut features are difficult to identify a priori. Read More
MusicAIR: A Multimodal AI Music Generation Framework Powered by an Algorithm-Driven Corecs.AI updates on arXiv.org arXiv:2511.17323v1 Announce Type: cross
Abstract: Recent advances in generative AI have made music generation a prominent research focus. However, many neural-based models rely on large datasets, raising concerns about copyright infringement and high-performance costs. In contrast, we propose MusicAIR, an innovative multimodal AI music generation framework powered by a novel algorithm-driven symbolic music core, effectively mitigating copyright infringement risks. The music core algorithms connect critical lyrical and rhythmic information to automatically derive musical features, creating a complete, coherent melodic score solely from the lyrics. The MusicAIR framework facilitates music generation from lyrics, text, and images. The generated score adheres to established principles of music theory, lyrical structure, and rhythmic conventions. We developed Generate AI Music (GenAIM), a web tool using MusicAIR for lyric-to-song, text-to-music, and image-to-music generation. In our experiments, we evaluated AI-generated music scores produced by the system using both standard music metrics and innovative analysis that compares these compositions with original works. The system achieves an average key confidence of 85%, outperforming human composers at 79%, and aligns closely with established music theory standards, demonstrating its ability to generate diverse, human-like compositions. As a co-pilot tool, GenAIM can serve as a reliable music composition assistant and a possible educational composition tutor while simultaneously lowering the entry barrier for all aspiring musicians, which is innovative and significantly contributes to AI for music generation.
arXiv:2511.17323v1 Announce Type: cross
Abstract: Recent advances in generative AI have made music generation a prominent research focus. However, many neural-based models rely on large datasets, raising concerns about copyright infringement and high-performance costs. In contrast, we propose MusicAIR, an innovative multimodal AI music generation framework powered by a novel algorithm-driven symbolic music core, effectively mitigating copyright infringement risks. The music core algorithms connect critical lyrical and rhythmic information to automatically derive musical features, creating a complete, coherent melodic score solely from the lyrics. The MusicAIR framework facilitates music generation from lyrics, text, and images. The generated score adheres to established principles of music theory, lyrical structure, and rhythmic conventions. We developed Generate AI Music (GenAIM), a web tool using MusicAIR for lyric-to-song, text-to-music, and image-to-music generation. In our experiments, we evaluated AI-generated music scores produced by the system using both standard music metrics and innovative analysis that compares these compositions with original works. The system achieves an average key confidence of 85%, outperforming human composers at 79%, and aligns closely with established music theory standards, demonstrating its ability to generate diverse, human-like compositions. As a co-pilot tool, GenAIM can serve as a reliable music composition assistant and a possible educational composition tutor while simultaneously lowering the entry barrier for all aspiring musicians, which is innovative and significantly contributes to AI for music generation. Read More
A lightweight detector for real-time detection of remote sensing imagescs.AI updates on arXiv.org arXiv:2511.17147v1 Announce Type: cross
Abstract: Remote sensing imagery is widely used across various fields, yet real-time detection remains challenging due to the prevalence of small objects and the need to balance accuracy with efficiency. To address this, we propose DMG-YOLO, a lightweight real-time detector tailored for small object detection in remote sensing images. Specifically, we design a Dual-branch Feature Extraction (DFE) module in the backbone, which partitions feature maps into two parallel branches: one extracts local features via depthwise separable convolutions, and the other captures global context using a vision transformer with a gating mechanism. Additionally, a Multi-scale Feature Fusion (MFF) module with dilated convolutions enhances multi-scale integration while preserving fine details. In the neck, we introduce the Global and Local Aggregate Feature Pyramid Network (GLAFPN) to further boost small object detection through global-local feature fusion. Extensive experiments on the VisDrone2019 and NWPU VHR-10 datasets show that DMG-YOLO achieves competitive performance in terms of mAP, model size, and other key metrics.
arXiv:2511.17147v1 Announce Type: cross
Abstract: Remote sensing imagery is widely used across various fields, yet real-time detection remains challenging due to the prevalence of small objects and the need to balance accuracy with efficiency. To address this, we propose DMG-YOLO, a lightweight real-time detector tailored for small object detection in remote sensing images. Specifically, we design a Dual-branch Feature Extraction (DFE) module in the backbone, which partitions feature maps into two parallel branches: one extracts local features via depthwise separable convolutions, and the other captures global context using a vision transformer with a gating mechanism. Additionally, a Multi-scale Feature Fusion (MFF) module with dilated convolutions enhances multi-scale integration while preserving fine details. In the neck, we introduce the Global and Local Aggregate Feature Pyramid Network (GLAFPN) to further boost small object detection through global-local feature fusion. Extensive experiments on the VisDrone2019 and NWPU VHR-10 datasets show that DMG-YOLO achieves competitive performance in terms of mAP, model size, and other key metrics. Read More
Platonic Representations for Poverty Mapping: Unified Vision-Language Codes or Agent-Induced Novelty?cs.AI updates on arXiv.org arXiv:2508.01109v2 Announce Type: replace
Abstract: We investigate whether socio-economic indicators like household wealth leave recoverable imprints in satellite imagery (capturing physical features) and Internet-sourced text (reflecting historical/economic narratives). Using Demographic and Health Survey (DHS) data from African neighborhoods, we pair Landsat images with LLM-generated textual descriptions conditioned on location/year and text retrieved by an AI search agent from web sources. We develop a multimodal framework predicting household wealth (International Wealth Index) through five pipelines: (i) vision model on satellite images, (ii) LLM using only location/year, (iii) AI agent searching/synthesizing web text, (iv) joint image-text encoder, (v) ensemble of all signals. Our framework yields three contributions. First, fusing vision and agent/LLM text outperforms vision-only baselines in wealth prediction (e.g., R-squared of 0.77 vs. 0.63 on out-of-sample splits), with LLM-internal knowledge proving more effective than agent-retrieved text, improving robustness to out-of-country and out-of-time generalization. Second, we find partial representational convergence: fused embeddings from vision/language modalities correlate moderately (median cosine similarity of 0.60 after alignment), suggesting a shared latent code of material well-being while retaining complementary details, consistent with the Platonic Representation Hypothesis. Although LLM-only text outperforms agent-retrieved data, challenging our Agent-Induced Novelty Hypothesis, modest gains from combining agent data in some splits weakly support the notion that agent-gathered information introduces unique representational structures not fully captured by static LLM knowledge. Third, we release a large-scale multimodal dataset comprising more than 60,000 DHS clusters linked to satellite images, LLM-generated descriptions, and agent-retrieved texts.
arXiv:2508.01109v2 Announce Type: replace
Abstract: We investigate whether socio-economic indicators like household wealth leave recoverable imprints in satellite imagery (capturing physical features) and Internet-sourced text (reflecting historical/economic narratives). Using Demographic and Health Survey (DHS) data from African neighborhoods, we pair Landsat images with LLM-generated textual descriptions conditioned on location/year and text retrieved by an AI search agent from web sources. We develop a multimodal framework predicting household wealth (International Wealth Index) through five pipelines: (i) vision model on satellite images, (ii) LLM using only location/year, (iii) AI agent searching/synthesizing web text, (iv) joint image-text encoder, (v) ensemble of all signals. Our framework yields three contributions. First, fusing vision and agent/LLM text outperforms vision-only baselines in wealth prediction (e.g., R-squared of 0.77 vs. 0.63 on out-of-sample splits), with LLM-internal knowledge proving more effective than agent-retrieved text, improving robustness to out-of-country and out-of-time generalization. Second, we find partial representational convergence: fused embeddings from vision/language modalities correlate moderately (median cosine similarity of 0.60 after alignment), suggesting a shared latent code of material well-being while retaining complementary details, consistent with the Platonic Representation Hypothesis. Although LLM-only text outperforms agent-retrieved data, challenging our Agent-Induced Novelty Hypothesis, modest gains from combining agent data in some splits weakly support the notion that agent-gathered information introduces unique representational structures not fully captured by static LLM knowledge. Third, we release a large-scale multimodal dataset comprising more than 60,000 DHS clusters linked to satellite images, LLM-generated descriptions, and agent-retrieved texts. Read More