
How to Implement Functional Components of Transformer and Mini-GPT Model from Scratch Using Tinygrad to Understand Deep Learning InternalsMarkTechPost In this tutorial, we explore how to build neural networks from scratch using Tinygrad while remaining fully hands-on with tensors, autograd, attention mechanisms, and transformer architectures. We progressively build every component ourselves, from basic tensor operations to multi-head attention, transformer blocks, and, finally, a working mini-GPT model. Through each stage, we observe how Tinygrad’s simplicity
The post How to Implement Functional Components of Transformer and Mini-GPT Model from Scratch Using Tinygrad to Understand Deep Learning Internals appeared first on MarkTechPost.
In this tutorial, we explore how to build neural networks from scratch using Tinygrad while remaining fully hands-on with tensors, autograd, attention mechanisms, and transformer architectures. We progressively build every component ourselves, from basic tensor operations to multi-head attention, transformer blocks, and, finally, a working mini-GPT model. Through each stage, we observe how Tinygrad’s simplicity
The post How to Implement Functional Components of Transformer and Mini-GPT Model from Scratch Using Tinygrad to Understand Deep Learning Internals appeared first on MarkTechPost. Read More
Find Them All: Unveiling MLLMs for Versatile Person Re-identificationcs.AI updates on arXiv.org arXiv:2508.06908v2 Announce Type: replace-cross
Abstract: Person re-identification (ReID) aims to retrieve images of a target person from the gallery set, with wide applications in medical rehabilitation and public security. However, traditional person ReID models are typically uni-modal, resulting in limited generalizability across heterogeneous data modalities. Recently, the emergence of multi-modal large language models (MLLMs) has shown a promising avenue for addressing this issue. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, leaving their capabilities in person ReID tasks largely unexplored. To bridge this gap, we introduce a novel benchmark for underline{textbf{V}}ersatile underline{textbf{P}}erson underline{textbf{Re}}-underline{textbf{ID}}entification, termed VP-ReID. The benchmark includes 257,310 multi-modal queries and gallery images, covering ten diverse person ReID tasks. In addition, we propose two task-oriented evaluation schemes for MLLM-based person ReID. Extensive experiments demonstrate the impressive versatility, effectiveness, and interpretability of MLLMs in various person ReID tasks. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope that VP-ReID can facilitate the community in developing more robust and generalizable cross-modal foundation models for person ReID.
arXiv:2508.06908v2 Announce Type: replace-cross
Abstract: Person re-identification (ReID) aims to retrieve images of a target person from the gallery set, with wide applications in medical rehabilitation and public security. However, traditional person ReID models are typically uni-modal, resulting in limited generalizability across heterogeneous data modalities. Recently, the emergence of multi-modal large language models (MLLMs) has shown a promising avenue for addressing this issue. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, leaving their capabilities in person ReID tasks largely unexplored. To bridge this gap, we introduce a novel benchmark for underline{textbf{V}}ersatile underline{textbf{P}}erson underline{textbf{Re}}-underline{textbf{ID}}entification, termed VP-ReID. The benchmark includes 257,310 multi-modal queries and gallery images, covering ten diverse person ReID tasks. In addition, we propose two task-oriented evaluation schemes for MLLM-based person ReID. Extensive experiments demonstrate the impressive versatility, effectiveness, and interpretability of MLLMs in various person ReID tasks. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope that VP-ReID can facilitate the community in developing more robust and generalizable cross-modal foundation models for person ReID. Read More
Comparative Study of UNet-based Architectures for Liver Tumor Segmentation in Multi-Phase Contrast-Enhanced Computed Tomographycs.AI updates on arXiv.org arXiv:2510.25522v4 Announce Type: replace-cross
Abstract: Segmentation of liver structures in multi-phase contrast-enhanced computed tomography (CECT) plays a crucial role in computer-aided diagnosis and treatment planning for liver diseases, including tumor detection. In this study, we investigate the performance of UNet-based architectures for liver tumor segmentation, starting from the original UNet and extending to UNet3+ with various backbone networks. We evaluate ResNet, Transformer-based, and State-space (Mamba) backbones, all initialized with pretrained weights. Surprisingly, despite the advances in modern architecture, ResNet-based models consistently outperform Transformer- and Mamba-based alternatives across multiple evaluation metrics. To further improve segmentation quality, we introduce attention mechanisms into the backbone and observe that incorporating the Convolutional Block Attention Module (CBAM) yields the best performance. ResNetUNet3+ with CBAM module not only produced the best overlap metrics with a Dice score of 0.755 and IoU of 0.662, but also achieved the most precise boundary delineation, evidenced by the lowest HD95 distance of 77.911. The model’s superiority was further cemented by its leading overall accuracy of 0.925 and specificity of 0.926, showcasing its robust capability in accurately identifying both lesion and healthy tissue. To further enhance interpretability, Grad-CAM visualizations were employed to highlight the region’s most influential predictions, providing insights into its decision-making process. These findings demonstrate that classical ResNet architecture, when combined with modern attention modules, remain highly competitive for medical image segmentation tasks, offering a promising direction for liver tumor detection in clinical practice.
arXiv:2510.25522v4 Announce Type: replace-cross
Abstract: Segmentation of liver structures in multi-phase contrast-enhanced computed tomography (CECT) plays a crucial role in computer-aided diagnosis and treatment planning for liver diseases, including tumor detection. In this study, we investigate the performance of UNet-based architectures for liver tumor segmentation, starting from the original UNet and extending to UNet3+ with various backbone networks. We evaluate ResNet, Transformer-based, and State-space (Mamba) backbones, all initialized with pretrained weights. Surprisingly, despite the advances in modern architecture, ResNet-based models consistently outperform Transformer- and Mamba-based alternatives across multiple evaluation metrics. To further improve segmentation quality, we introduce attention mechanisms into the backbone and observe that incorporating the Convolutional Block Attention Module (CBAM) yields the best performance. ResNetUNet3+ with CBAM module not only produced the best overlap metrics with a Dice score of 0.755 and IoU of 0.662, but also achieved the most precise boundary delineation, evidenced by the lowest HD95 distance of 77.911. The model’s superiority was further cemented by its leading overall accuracy of 0.925 and specificity of 0.926, showcasing its robust capability in accurately identifying both lesion and healthy tissue. To further enhance interpretability, Grad-CAM visualizations were employed to highlight the region’s most influential predictions, providing insights into its decision-making process. These findings demonstrate that classical ResNet architecture, when combined with modern attention modules, remain highly competitive for medical image segmentation tasks, offering a promising direction for liver tumor detection in clinical practice. Read More
Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Roboticscs.AI updates on arXiv.org arXiv:2501.10100v4 Announce Type: replace-cross
Abstract: Learning robust and generalizable world models is crucial for enabling efficient and scalable robotic control in real-world environments. In this work, we introduce a novel framework for learning world models that accurately capture complex, partially observable, and stochastic dynamics. The proposed method employs a dual-autoregressive mechanism and self-supervised training to achieve reliable long-horizon predictions without relying on domain-specific inductive biases, ensuring adaptability across diverse robotic tasks. We further propose a policy optimization framework that leverages world models for efficient training in imagined environments and seamless deployment in real-world systems. This work advances model-based reinforcement learning by addressing the challenges of long-horizon prediction, error accumulation, and sim-to-real transfer. By providing a scalable and robust framework, the introduced methods pave the way for adaptive and efficient robotic systems in real-world applications.
arXiv:2501.10100v4 Announce Type: replace-cross
Abstract: Learning robust and generalizable world models is crucial for enabling efficient and scalable robotic control in real-world environments. In this work, we introduce a novel framework for learning world models that accurately capture complex, partially observable, and stochastic dynamics. The proposed method employs a dual-autoregressive mechanism and self-supervised training to achieve reliable long-horizon predictions without relying on domain-specific inductive biases, ensuring adaptability across diverse robotic tasks. We further propose a policy optimization framework that leverages world models for efficient training in imagined environments and seamless deployment in real-world systems. This work advances model-based reinforcement learning by addressing the challenges of long-horizon prediction, error accumulation, and sim-to-real transfer. By providing a scalable and robust framework, the introduced methods pave the way for adaptive and efficient robotic systems in real-world applications. Read More
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Researchcs.AI updates on arXiv.org arXiv:2511.19399v1 Announce Type: cross
Abstract: Deep research models perform multi-step research to produce long-form, well-attributed answers. However, most open deep research models are trained on easily verifiable short-form QA tasks via reinforcement learning with verifiable rewards (RLVR), which does not extend to realistic long-form tasks. We address this with Reinforcement Learning with Evolving Rubrics (RLER), in which we construct and maintain rubrics that co-evolve with the policy model during training; this allows the rubrics to incorporate information that the model has newly explored and to provide discriminative, on-policy feedback. Using RLER, we develop Deep Research Tulu (DR Tulu-8B), the first open model that is directly trained for open-ended, long-form deep research. Across four long-form deep research benchmarks in science, healthcare and general domains, DR Tulu substantially outperforms existing open deep research models, and matches or exceeds proprietary deep research systems, while being significantly smaller and cheaper per query. To facilitate future research, we release all data, models, and code, including our new MCP-based agent infrastructure for deep research systems.
arXiv:2511.19399v1 Announce Type: cross
Abstract: Deep research models perform multi-step research to produce long-form, well-attributed answers. However, most open deep research models are trained on easily verifiable short-form QA tasks via reinforcement learning with verifiable rewards (RLVR), which does not extend to realistic long-form tasks. We address this with Reinforcement Learning with Evolving Rubrics (RLER), in which we construct and maintain rubrics that co-evolve with the policy model during training; this allows the rubrics to incorporate information that the model has newly explored and to provide discriminative, on-policy feedback. Using RLER, we develop Deep Research Tulu (DR Tulu-8B), the first open model that is directly trained for open-ended, long-form deep research. Across four long-form deep research benchmarks in science, healthcare and general domains, DR Tulu substantially outperforms existing open deep research models, and matches or exceeds proprietary deep research systems, while being significantly smaller and cheaper per query. To facilitate future research, we release all data, models, and code, including our new MCP-based agent infrastructure for deep research systems. Read More
MeteorPred: A Meteorological Multimodal Large Model and Dataset for Severe Weather Event Predictioncs.AI updates on arXiv.org arXiv:2508.06859v2 Announce Type: replace
Abstract: Timely and accurate forecasts of severe weather events are essential for early warning and for constraining downstream analysis and decision-making. Since severe weather events prediction still depends on subjective, time-consuming expert interpretation, end-to-end “AI weather station” systems are emerging but face three major challenges: (1) scarcity of severe weather event samples; (2) imperfect alignment between high-dimensional meteorological data and textual warnings; (3) current multimodal language models cannot effectively process high-dimensional meteorological inputs or capture their complex spatiotemporal dependencies. To address these challenges, we introduce MP-Bench, the first large-scale multimodal dataset for severe weather events prediction, comprising 421,363 pairs of raw multi-year meteorological data and corresponding text caption, covering a wide range of severe weather scenarios. On top of this dataset, we develop a Meteorology Multimodal Large Model (MMLM) that directly ingests 4D meteorological inputs. In addition, it is designed to accommodate the unique characteristics of 4D meteorological data flow, incorporating three plug-and-play adaptive fusion modules that enable dynamic feature extraction and integration across temporal sequences, vertical pressure layers, and spatial dimensions. Extensive experiments on MP-Bench show that MMLM achieves strong performance across multiple tasks, demonstrating effective severe weather understanding and representing a key step toward automated, AI-driven severe weather events forecasting systems. Our source code and dataset will be made publicly available.
arXiv:2508.06859v2 Announce Type: replace
Abstract: Timely and accurate forecasts of severe weather events are essential for early warning and for constraining downstream analysis and decision-making. Since severe weather events prediction still depends on subjective, time-consuming expert interpretation, end-to-end “AI weather station” systems are emerging but face three major challenges: (1) scarcity of severe weather event samples; (2) imperfect alignment between high-dimensional meteorological data and textual warnings; (3) current multimodal language models cannot effectively process high-dimensional meteorological inputs or capture their complex spatiotemporal dependencies. To address these challenges, we introduce MP-Bench, the first large-scale multimodal dataset for severe weather events prediction, comprising 421,363 pairs of raw multi-year meteorological data and corresponding text caption, covering a wide range of severe weather scenarios. On top of this dataset, we develop a Meteorology Multimodal Large Model (MMLM) that directly ingests 4D meteorological inputs. In addition, it is designed to accommodate the unique characteristics of 4D meteorological data flow, incorporating three plug-and-play adaptive fusion modules that enable dynamic feature extraction and integration across temporal sequences, vertical pressure layers, and spatial dimensions. Extensive experiments on MP-Bench show that MMLM achieves strong performance across multiple tasks, demonstrating effective severe weather understanding and representing a key step toward automated, AI-driven severe weather events forecasting systems. Our source code and dataset will be made publicly available. Read More

Are AI Browsers Any Good? A Day with Perplexity’s Comet and OpenAI’s AtlasKDnuggets Understanding the underlying technology helps explain why AI browsers exhibit such uneven performance.
Understanding the underlying technology helps explain why AI browsers exhibit such uneven performance. Read More
RISAT’s Silent Promise: Decoding Disasters with Synthetic Aperture RadarTowards Data Science The high-resolution physics turning microwave echoes into real-time flood intelligence
The post RISAT’s Silent Promise: Decoding Disasters with Synthetic Aperture Radar appeared first on Towards Data Science.
The high-resolution physics turning microwave echoes into real-time flood intelligence
The post RISAT’s Silent Promise: Decoding Disasters with Synthetic Aperture Radar appeared first on Towards Data Science. Read More

5 Excel AI Lessons I Learned the Hard WayKDnuggets This article transforms the unwelcome experiences into five comprehensive frameworks that will elevate your Excel-based machine learning work.
This article transforms the unwelcome experiences into five comprehensive frameworks that will elevate your Excel-based machine learning work. Read More
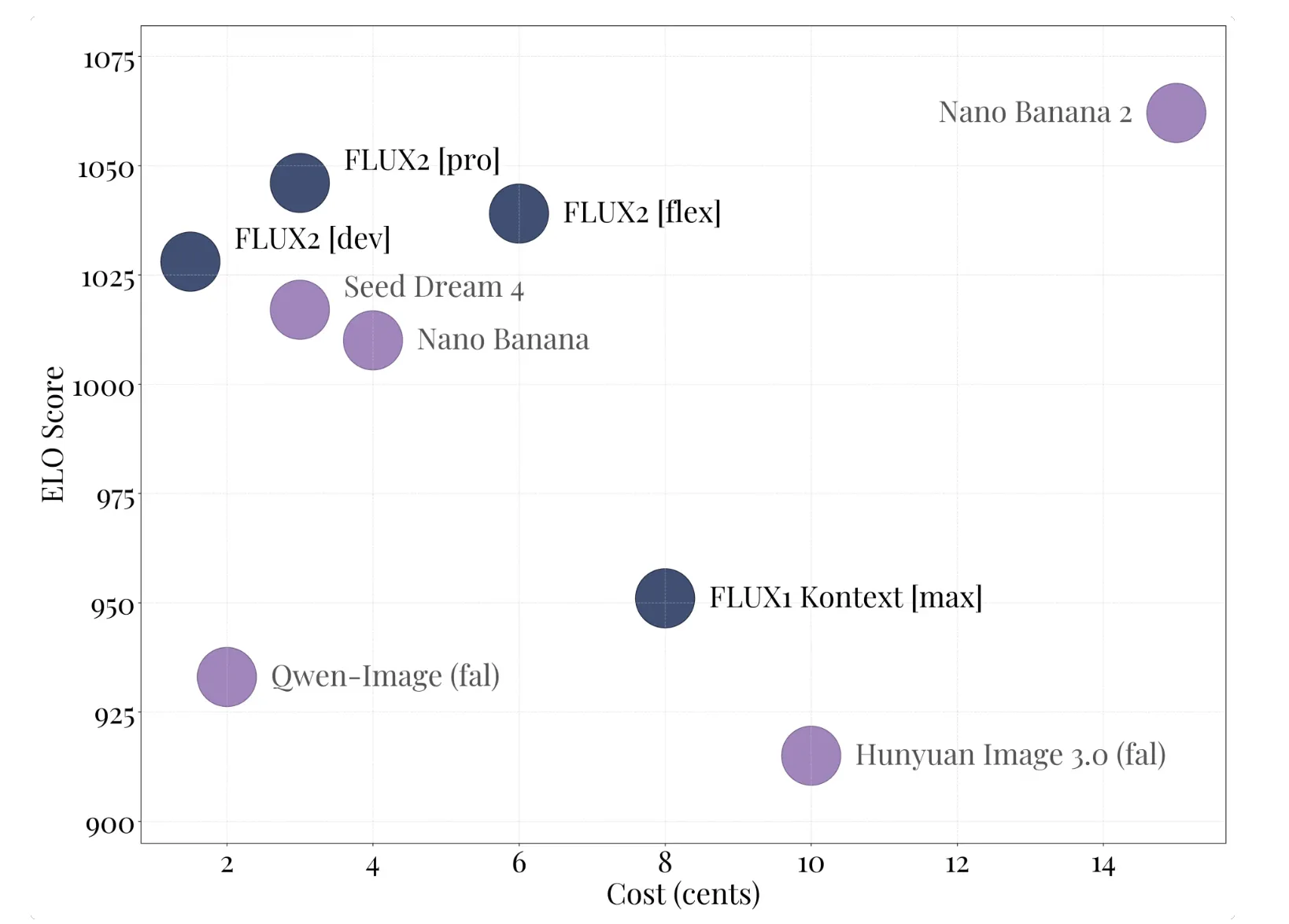
Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image PipelinesMarkTechPost Black Forest Labs has released FLUX.2, its second generation image generation and editing system. FLUX.2 targets real world creative workflows such as marketing assets, product photography, design layouts, and complex infographics, with editing support up to 4 megapixels and strong control over layout, logos, and typography. FLUX.2 product family and FLUX.2 [dev] The FLUX.2 family
The post Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image Pipelines appeared first on MarkTechPost.
Black Forest Labs has released FLUX.2, its second generation image generation and editing system. FLUX.2 targets real world creative workflows such as marketing assets, product photography, design layouts, and complex infographics, with editing support up to 4 megapixels and strong control over layout, logos, and typography. FLUX.2 product family and FLUX.2 [dev] The FLUX.2 family
The post Black Forest Labs Releases FLUX.2: A 32B Flow Matching Transformer for Production Image Pipelines appeared first on MarkTechPost. Read More