
WISE: Weighted Iterative Society-of-Experts for Robust Multimodal Multi-Agent Debatecs.AI updates on arXiv.org arXiv:2512.02405v1 Announce Type: cross
Abstract: Recent large language models (LLMs) are trained on diverse corpora and tasks, leading them to develop complementary strengths. Multi-agent debate (MAD) has emerged as a popular way to leverage these strengths for robust reasoning, though it has mostly been applied to language-only tasks, leaving its efficacy on multimodal problems underexplored. In this paper, we study MAD for solving vision-and-language reasoning problems. Our setup enables generalizing the debate protocol with heterogeneous experts that possess single- and multi-modal capabilities. To this end, we present Weighted Iterative Society-of-Experts (WISE), a generalized and modular MAD framework that partitions the agents into Solvers, that generate solutions, and Reflectors, that verify correctness, assign weights, and provide natural language feedback. To aggregate the agents’ solutions across debate rounds, while accounting for variance in their responses and the feedback weights, we present a modified Dawid-Skene algorithm for post-processing that integrates our two-stage debate model. We evaluate WISE on SMART-840, VisualPuzzles, EvoChart-QA, and a new SMART-840++ dataset with programmatically generated problem instances of controlled difficulty. Our results show that WISE consistently improves accuracy by 2-7% over the state-of-the-art MAD setups and aggregation methods across diverse multimodal tasks and LLM configurations.
arXiv:2512.02405v1 Announce Type: cross
Abstract: Recent large language models (LLMs) are trained on diverse corpora and tasks, leading them to develop complementary strengths. Multi-agent debate (MAD) has emerged as a popular way to leverage these strengths for robust reasoning, though it has mostly been applied to language-only tasks, leaving its efficacy on multimodal problems underexplored. In this paper, we study MAD for solving vision-and-language reasoning problems. Our setup enables generalizing the debate protocol with heterogeneous experts that possess single- and multi-modal capabilities. To this end, we present Weighted Iterative Society-of-Experts (WISE), a generalized and modular MAD framework that partitions the agents into Solvers, that generate solutions, and Reflectors, that verify correctness, assign weights, and provide natural language feedback. To aggregate the agents’ solutions across debate rounds, while accounting for variance in their responses and the feedback weights, we present a modified Dawid-Skene algorithm for post-processing that integrates our two-stage debate model. We evaluate WISE on SMART-840, VisualPuzzles, EvoChart-QA, and a new SMART-840++ dataset with programmatically generated problem instances of controlled difficulty. Our results show that WISE consistently improves accuracy by 2-7% over the state-of-the-art MAD setups and aggregation methods across diverse multimodal tasks and LLM configurations. Read More
Boosting Medical Vision-Language Pretraining via Momentum Self-Distillation under Limited Computing Resourcescs.AI updates on arXiv.org arXiv:2512.02438v1 Announce Type: cross
Abstract: In medical healthcare, obtaining detailed annotations is challenging, highlighting the need for robust Vision-Language Models (VLMs). Pretrained VLMs enable fine-tuning on small datasets or zero-shot inference, achieving performance comparable to task-specific models. Contrastive learning (CL) is a key paradigm for training VLMs but inherently requires large batch sizes for effective learning, making it computationally demanding and often limited to well-resourced institutions. Moreover, with limited data in healthcare, it is important to prioritize knowledge extraction from both data and models during training to improve performance. Therefore, we focus on leveraging the momentum method combined with distillation to simultaneously address computational efficiency and knowledge exploitation. Our contributions can be summarized as follows: (1) leveraging momentum self-distillation to enhance multimodal learning, and (2) integrating momentum mechanisms with gradient accumulation to enlarge the effective batch size without increasing resource consumption. Our method attains competitive performance with state-of-the-art (SOTA) approaches in zero-shot classification, while providing a substantial boost in the few-shot adaption, achieving over 90% AUC-ROC and improving retrieval tasks by 2-3%. Importantly, our method achieves high training efficiency with a single GPU while maintaining reasonable training time. Our approach aims to advance efficient multimodal learning by reducing resource requirements while improving performance over SOTA methods. The implementation of our method is available at https://github.com/phphuc612/MSD .
arXiv:2512.02438v1 Announce Type: cross
Abstract: In medical healthcare, obtaining detailed annotations is challenging, highlighting the need for robust Vision-Language Models (VLMs). Pretrained VLMs enable fine-tuning on small datasets or zero-shot inference, achieving performance comparable to task-specific models. Contrastive learning (CL) is a key paradigm for training VLMs but inherently requires large batch sizes for effective learning, making it computationally demanding and often limited to well-resourced institutions. Moreover, with limited data in healthcare, it is important to prioritize knowledge extraction from both data and models during training to improve performance. Therefore, we focus on leveraging the momentum method combined with distillation to simultaneously address computational efficiency and knowledge exploitation. Our contributions can be summarized as follows: (1) leveraging momentum self-distillation to enhance multimodal learning, and (2) integrating momentum mechanisms with gradient accumulation to enlarge the effective batch size without increasing resource consumption. Our method attains competitive performance with state-of-the-art (SOTA) approaches in zero-shot classification, while providing a substantial boost in the few-shot adaption, achieving over 90% AUC-ROC and improving retrieval tasks by 2-3%. Importantly, our method achieves high training efficiency with a single GPU while maintaining reasonable training time. Our approach aims to advance efficient multimodal learning by reducing resource requirements while improving performance over SOTA methods. The implementation of our method is available at https://github.com/phphuc612/MSD . Read More
Video Diffusion Models Excel at Tracking Similar-Looking Objects Without Supervisioncs.AI updates on arXiv.org arXiv:2512.02339v1 Announce Type: cross
Abstract: Distinguishing visually similar objects by their motion remains a critical challenge in computer vision. Although supervised trackers show promise, contemporary self-supervised trackers struggle when visual cues become ambiguous, limiting their scalability and generalization without extensive labeled data. We find that pre-trained video diffusion models inherently learn motion representations suitable for tracking without task-specific training. This ability arises because their denoising process isolates motion in early, high-noise stages, distinct from later appearance refinement. Capitalizing on this discovery, our self-supervised tracker significantly improves performance in distinguishing visually similar objects, an underexplored failure point for existing methods. Our method achieves up to a 6-point improvement over recent self-supervised approaches on established benchmarks and our newly introduced tests focused on tracking visually similar items. Visualizations confirm that these diffusion-derived motion representations enable robust tracking of even identical objects across challenging viewpoint changes and deformations.
arXiv:2512.02339v1 Announce Type: cross
Abstract: Distinguishing visually similar objects by their motion remains a critical challenge in computer vision. Although supervised trackers show promise, contemporary self-supervised trackers struggle when visual cues become ambiguous, limiting their scalability and generalization without extensive labeled data. We find that pre-trained video diffusion models inherently learn motion representations suitable for tracking without task-specific training. This ability arises because their denoising process isolates motion in early, high-noise stages, distinct from later appearance refinement. Capitalizing on this discovery, our self-supervised tracker significantly improves performance in distinguishing visually similar objects, an underexplored failure point for existing methods. Our method achieves up to a 6-point improvement over recent self-supervised approaches on established benchmarks and our newly introduced tests focused on tracking visually similar items. Visualizations confirm that these diffusion-derived motion representations enable robust tracking of even identical objects across challenging viewpoint changes and deformations. Read More
Model Recovery at the Edge under Resource Constraints for Physical AIcs.AI updates on arXiv.org arXiv:2512.02283v1 Announce Type: new
Abstract: Model Recovery (MR) enables safe, explainable decision making in mission-critical autonomous systems (MCAS) by learning governing dynamical equations, but its deployment on edge devices is hindered by the iterative nature of neural ordinary differential equations (NODEs), which are inefficient on FPGAs. Memory and energy consumption are the main concerns when applying MR on edge devices for real-time operation. We propose MERINDA, a novel FPGA-accelerated MR framework that replaces iterative solvers with a parallelizable neural architecture equivalent to NODEs. MERINDA achieves nearly 11x lower DRAM usage and 2.2x faster runtime compared to mobile GPUs. Experiments reveal an inverse relationship between memory and energy at fixed accuracy, highlighting MERINDA’s suitability for resource-constrained, real-time MCAS.
arXiv:2512.02283v1 Announce Type: new
Abstract: Model Recovery (MR) enables safe, explainable decision making in mission-critical autonomous systems (MCAS) by learning governing dynamical equations, but its deployment on edge devices is hindered by the iterative nature of neural ordinary differential equations (NODEs), which are inefficient on FPGAs. Memory and energy consumption are the main concerns when applying MR on edge devices for real-time operation. We propose MERINDA, a novel FPGA-accelerated MR framework that replaces iterative solvers with a parallelizable neural architecture equivalent to NODEs. MERINDA achieves nearly 11x lower DRAM usage and 2.2x faster runtime compared to mobile GPUs. Experiments reveal an inverse relationship between memory and energy at fixed accuracy, highlighting MERINDA’s suitability for resource-constrained, real-time MCAS. Read More
GRAFT: GRaPH and Table Reasoning for Textual Alignment — A Benchmark for Structured Instruction Following and Visual Reasoningcs.AI updates on arXiv.org arXiv:2508.15690v4 Announce Type: replace
Abstract: GRAFT is a structured multimodal benchmark designed to probe how well LLMs handle instruction following, visual reasoning, and tasks requiring tight visual textual alignment. The dataset is built around programmatically generated charts and synthetically rendered tables, each paired with a carefully constructed, multi step analytical question that depends solely on what can be inferred from the image itself. Responses are formatted in structured outputs such as JSON or YAML, enabling consistent and fine grained evaluation of both reasoning processes and adherence to output specifications. The benchmark further introduces a taxonomy of reasoning operations ranging from comparison and trend identification to ranking, aggregation, proportional estimation, and anomaly detection to support a comprehensive assessment of model capabilities. Taken together, GRAFT provides a unified and scalable framework for evaluating multimodal LLMs on visually grounded, structured reasoning tasks, offering a more rigorous standard for future benchmarking efforts.
arXiv:2508.15690v4 Announce Type: replace
Abstract: GRAFT is a structured multimodal benchmark designed to probe how well LLMs handle instruction following, visual reasoning, and tasks requiring tight visual textual alignment. The dataset is built around programmatically generated charts and synthetically rendered tables, each paired with a carefully constructed, multi step analytical question that depends solely on what can be inferred from the image itself. Responses are formatted in structured outputs such as JSON or YAML, enabling consistent and fine grained evaluation of both reasoning processes and adherence to output specifications. The benchmark further introduces a taxonomy of reasoning operations ranging from comparison and trend identification to ranking, aggregation, proportional estimation, and anomaly detection to support a comprehensive assessment of model capabilities. Taken together, GRAFT provides a unified and scalable framework for evaluating multimodal LLMs on visually grounded, structured reasoning tasks, offering a more rigorous standard for future benchmarking efforts. Read More
LORE: A Large Generative Model for Search Relevancecs.AI updates on arXiv.org arXiv:2512.03025v1 Announce Type: cross
Abstract: Achievement. We introduce LORE, a systematic framework for Large Generative Model-based relevance in e-commerce search. Deployed and iterated over three years, LORE achieves a cumulative +27% improvement in online GoodRate metrics. This report shares the valuable experience gained throughout its development lifecycle, spanning data, features, training, evaluation, and deployment. Insight. While existing works apply Chain-of-Thought (CoT) to enhance relevance, they often hit a performance ceiling. We argue this stems from treating relevance as a monolithic task, lacking principled deconstruction. Our key insight is that relevance comprises distinct capabilities: knowledge and reasoning, multi-modal matching, and rule adherence. We contend that a qualitative-driven decomposition is essential for breaking through current performance bottlenecks. Contributions. LORE provides a complete blueprint for the LLM relevance lifecycle. Key contributions include: (1) A two-stage training paradigm combining progressive CoT synthesis via SFT with human preference alignment via RL. (2) A comprehensive benchmark, RAIR, designed to evaluate these core capabilities. (3) A query frequency-stratified deployment strategy that efficiently transfers offline LLM capabilities to the online system. LORE serves as both a practical solution and a methodological reference for other vertical domains.
arXiv:2512.03025v1 Announce Type: cross
Abstract: Achievement. We introduce LORE, a systematic framework for Large Generative Model-based relevance in e-commerce search. Deployed and iterated over three years, LORE achieves a cumulative +27% improvement in online GoodRate metrics. This report shares the valuable experience gained throughout its development lifecycle, spanning data, features, training, evaluation, and deployment. Insight. While existing works apply Chain-of-Thought (CoT) to enhance relevance, they often hit a performance ceiling. We argue this stems from treating relevance as a monolithic task, lacking principled deconstruction. Our key insight is that relevance comprises distinct capabilities: knowledge and reasoning, multi-modal matching, and rule adherence. We contend that a qualitative-driven decomposition is essential for breaking through current performance bottlenecks. Contributions. LORE provides a complete blueprint for the LLM relevance lifecycle. Key contributions include: (1) A two-stage training paradigm combining progressive CoT synthesis via SFT with human preference alignment via RL. (2) A comprehensive benchmark, RAIR, designed to evaluate these core capabilities. (3) A query frequency-stratified deployment strategy that efficiently transfers offline LLM capabilities to the online system. LORE serves as both a practical solution and a methodological reference for other vertical domains. Read More
Fine-tuning of lightweight large language models for sentiment classification on heterogeneous financial textual datacs.AI updates on arXiv.org arXiv:2512.00946v1 Announce Type: cross
Abstract: Large language models (LLMs) play an increasingly important role in finan- cial markets analysis by capturing signals from complex and heterogeneous textual data sources, such as tweets, news articles, reports, and microblogs. However, their performance is dependent on large computational resources and proprietary datasets, which are costly, restricted, and therefore inacces- sible to many researchers and practitioners. To reflect realistic situations we investigate the ability of lightweight open-source LLMs – smaller and publicly available models designed to operate with limited computational resources – to generalize sentiment understanding from financial datasets of varying sizes, sources, formats, and languages. We compare the benchmark finance natural language processing (NLP) model, FinBERT, and three open-source lightweight LLMs, DeepSeek-LLM 7B, Llama3 8B Instruct, and Qwen3 8B on five publicly available datasets: FinancialPhraseBank, Financial Question Answering, Gold News Sentiment, Twitter Sentiment and Chinese Finance Sentiment. We find that LLMs, specially Qwen3 8B and Llama3 8B, perform best in most scenarios, even from using only 5% of the available training data. These results hold in zero-shot and few-shot learning scenarios. Our findings indicate that lightweight, open-source large language models (LLMs) consti- tute a cost-effective option, as they can achieve competitive performance on heterogeneous textual data even when trained on only a limited subset of the extensive annotated corpora that are typically deemed necessary.
arXiv:2512.00946v1 Announce Type: cross
Abstract: Large language models (LLMs) play an increasingly important role in finan- cial markets analysis by capturing signals from complex and heterogeneous textual data sources, such as tweets, news articles, reports, and microblogs. However, their performance is dependent on large computational resources and proprietary datasets, which are costly, restricted, and therefore inacces- sible to many researchers and practitioners. To reflect realistic situations we investigate the ability of lightweight open-source LLMs – smaller and publicly available models designed to operate with limited computational resources – to generalize sentiment understanding from financial datasets of varying sizes, sources, formats, and languages. We compare the benchmark finance natural language processing (NLP) model, FinBERT, and three open-source lightweight LLMs, DeepSeek-LLM 7B, Llama3 8B Instruct, and Qwen3 8B on five publicly available datasets: FinancialPhraseBank, Financial Question Answering, Gold News Sentiment, Twitter Sentiment and Chinese Finance Sentiment. We find that LLMs, specially Qwen3 8B and Llama3 8B, perform best in most scenarios, even from using only 5% of the available training data. These results hold in zero-shot and few-shot learning scenarios. Our findings indicate that lightweight, open-source large language models (LLMs) consti- tute a cost-effective option, as they can achieve competitive performance on heterogeneous textual data even when trained on only a limited subset of the extensive annotated corpora that are typically deemed necessary. Read More
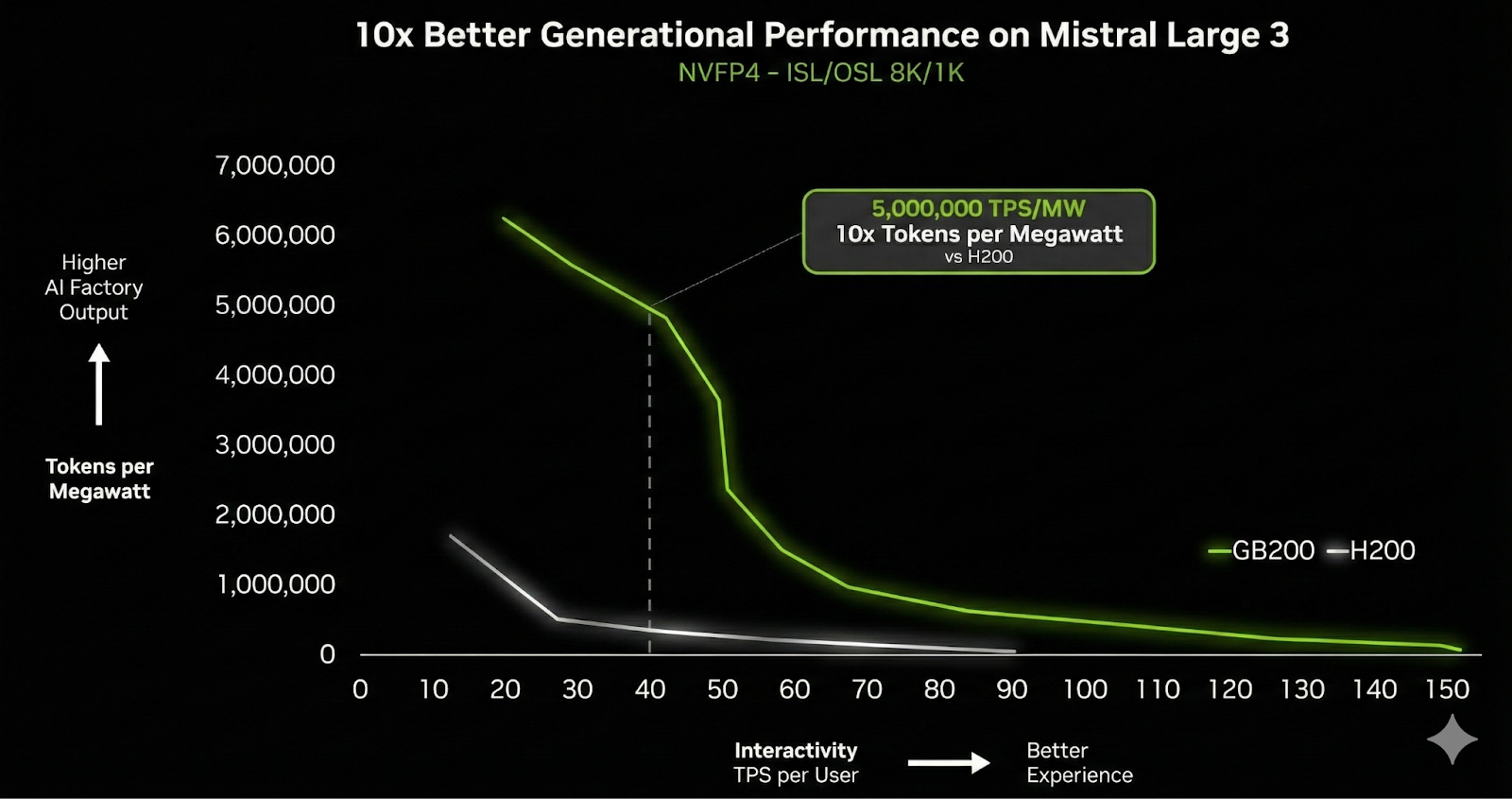
NVIDIA and Mistral AI Bring 10x Faster Inference for the Mistral 3 Family on GB200 NVL72 GPU SystemsMarkTechPost NVIDIA announced today a significant expansion of its strategic collaboration with Mistral AI. This partnership coincides with the release of the new Mistral 3 frontier open model family, marking a pivotal moment where hardware acceleration and open-source model architecture have converged to redefine performance benchmarks. This collaboration is a massive leap in inference speed: the
The post NVIDIA and Mistral AI Bring 10x Faster Inference for the Mistral 3 Family on GB200 NVL72 GPU Systems appeared first on MarkTechPost.
NVIDIA announced today a significant expansion of its strategic collaboration with Mistral AI. This partnership coincides with the release of the new Mistral 3 frontier open model family, marking a pivotal moment where hardware acceleration and open-source model architecture have converged to redefine performance benchmarks. This collaboration is a massive leap in inference speed: the
The post NVIDIA and Mistral AI Bring 10x Faster Inference for the Mistral 3 Family on GB200 NVL72 GPU Systems appeared first on MarkTechPost. Read More

Frontier AI research lab tackles enterprise deployment challengesAI News Thomson Reuters and Imperial College London have established a frontier AI research lab to overcome historic deployment challenges. Speed and scale have defined the current AI boom. But for enterprises, the primary obstacles to deployment are different: trust, accuracy, and lineage. Addressing these barriers, Thomson Reuters and Imperial College London have announced a five-year partnership
The post Frontier AI research lab tackles enterprise deployment challenges appeared first on AI News.
Thomson Reuters and Imperial College London have established a frontier AI research lab to overcome historic deployment challenges. Speed and scale have defined the current AI boom. But for enterprises, the primary obstacles to deployment are different: trust, accuracy, and lineage. Addressing these barriers, Thomson Reuters and Imperial College London have announced a five-year partnership
The post Frontier AI research lab tackles enterprise deployment challenges appeared first on AI News. Read More
Toward a benchmark for CTR prediction in online advertising: datasets, evaluation protocols and perspectivescs.AI updates on arXiv.org arXiv:2512.01179v1 Announce Type: cross
Abstract: This research designs a unified architecture of CTR prediction benchmark (Bench-CTR) platform that offers flexible interfaces with datasets and components of a wide range of CTR prediction models. Moreover, we construct a comprehensive system of evaluation protocols encompassing real-world and synthetic datasets, a taxonomy of metrics, standardized procedures and experimental guidelines for calibrating the performance of CTR prediction models. Furthermore, we implement the proposed benchmark platform and conduct a comparative study to evaluate a wide range of state-of-the-art models from traditional multivariate statistical to modern large language model (LLM)-based approaches on three public datasets and two synthetic datasets. Experimental results reveal that, (1) high-order models largely outperform low-order models, though such advantage varies in terms of metrics and on different datasets; (2) LLM-based models demonstrate a remarkable data efficiency, i.e., achieving the comparable performance to other models while using only 2% of the training data; (3) the performance of CTR prediction models has achieved significant improvements from 2015 to 2016, then reached a stage with slow progress, which is consistent across various datasets. This benchmark is expected to facilitate model development and evaluation and enhance practitioners’ understanding of the underlying mechanisms of models in the area of CTR prediction. Code is available at https://github.com/NuriaNinja/Bench-CTR.
arXiv:2512.01179v1 Announce Type: cross
Abstract: This research designs a unified architecture of CTR prediction benchmark (Bench-CTR) platform that offers flexible interfaces with datasets and components of a wide range of CTR prediction models. Moreover, we construct a comprehensive system of evaluation protocols encompassing real-world and synthetic datasets, a taxonomy of metrics, standardized procedures and experimental guidelines for calibrating the performance of CTR prediction models. Furthermore, we implement the proposed benchmark platform and conduct a comparative study to evaluate a wide range of state-of-the-art models from traditional multivariate statistical to modern large language model (LLM)-based approaches on three public datasets and two synthetic datasets. Experimental results reveal that, (1) high-order models largely outperform low-order models, though such advantage varies in terms of metrics and on different datasets; (2) LLM-based models demonstrate a remarkable data efficiency, i.e., achieving the comparable performance to other models while using only 2% of the training data; (3) the performance of CTR prediction models has achieved significant improvements from 2015 to 2016, then reached a stage with slow progress, which is consistent across various datasets. This benchmark is expected to facilitate model development and evaluation and enhance practitioners’ understanding of the underlying mechanisms of models in the area of CTR prediction. Code is available at https://github.com/NuriaNinja/Bench-CTR. Read More