
The Best Web Scraping APIs for AI Models in 2026KDnuggets For powering next-generation AI models in 2026, Bright Data’s Web Scraper API delivers on all fronts: dynamic site support, anti-bot automation, structured output, and global reach.
For powering next-generation AI models in 2026, Bright Data’s Web Scraper API delivers on all fronts: dynamic site support, anti-bot automation, structured output, and global reach. Read More

Microsoft AI Releases VibeVoice-Realtime: A Lightweight Real‑Time Text-to-Speech Model Supporting Streaming Text Input and Robust Long-Form Speech GenerationMarkTechPost Microsoft has released VibeVoice-Realtime-0.5B, a real time text to speech model that works with streaming text input and long form speech output, aimed at agent style applications and live data narration. The model can start producing audible speech in about 300 ms, which is critical when a language model is still generating the rest of
The post Microsoft AI Releases VibeVoice-Realtime: A Lightweight Real‑Time Text-to-Speech Model Supporting Streaming Text Input and Robust Long-Form Speech Generation appeared first on MarkTechPost.
Microsoft has released VibeVoice-Realtime-0.5B, a real time text to speech model that works with streaming text input and long form speech output, aimed at agent style applications and live data narration. The model can start producing audible speech in about 300 ms, which is critical when a language model is still generating the rest of
The post Microsoft AI Releases VibeVoice-Realtime: A Lightweight Real‑Time Text-to-Speech Model Supporting Streaming Text Input and Robust Long-Form Speech Generation appeared first on MarkTechPost. Read More
Reading Research Papers in the Age of LLMsTowards Data Science How I keep up with papers with a mix of manual and AI-assisted reading
The post Reading Research Papers in the Age of LLMs appeared first on Towards Data Science.
How I keep up with papers with a mix of manual and AI-assisted reading
The post Reading Research Papers in the Age of LLMs appeared first on Towards Data Science. Read More
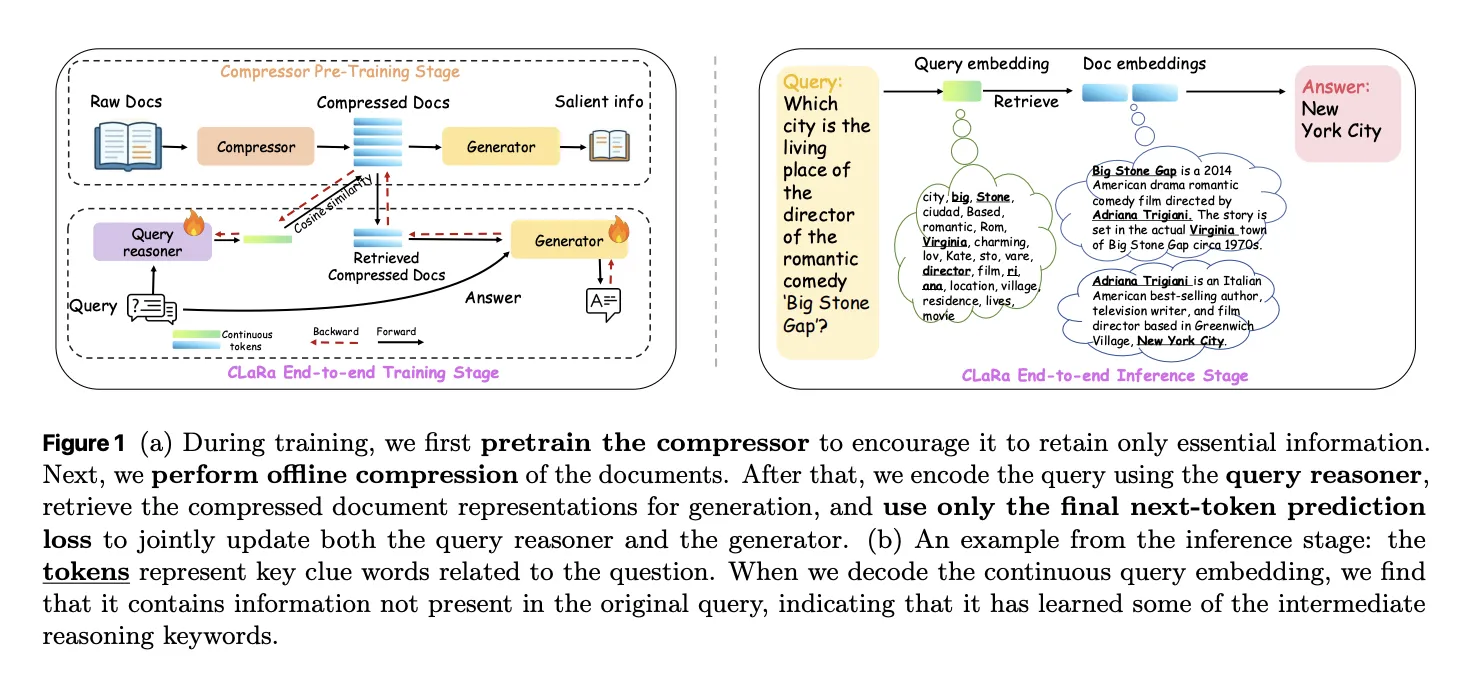
Apple Researchers Release CLaRa: A Continuous Latent Reasoning Framework for Compression‑Native RAG with 16x–128x Semantic Document CompressionMarkTechPost How do you keep RAG systems accurate and efficient when every query tries to stuff thousands of tokens into the context window and the retriever and generator are still optimized as 2 separate, disconnected systems? A team of researchers from Apple and University of Edinburgh released CLaRa, Continuous Latent Reasoning, (CLaRa-7B-Base, CLaRa-7B-Instruct and CLaRa-7B-E2E) a
The post Apple Researchers Release CLaRa: A Continuous Latent Reasoning Framework for Compression‑Native RAG with 16x–128x Semantic Document Compression appeared first on MarkTechPost.
How do you keep RAG systems accurate and efficient when every query tries to stuff thousands of tokens into the context window and the retriever and generator are still optimized as 2 separate, disconnected systems? A team of researchers from Apple and University of Edinburgh released CLaRa, Continuous Latent Reasoning, (CLaRa-7B-Base, CLaRa-7B-Instruct and CLaRa-7B-E2E) a
The post Apple Researchers Release CLaRa: A Continuous Latent Reasoning Framework for Compression‑Native RAG with 16x–128x Semantic Document Compression appeared first on MarkTechPost. Read More
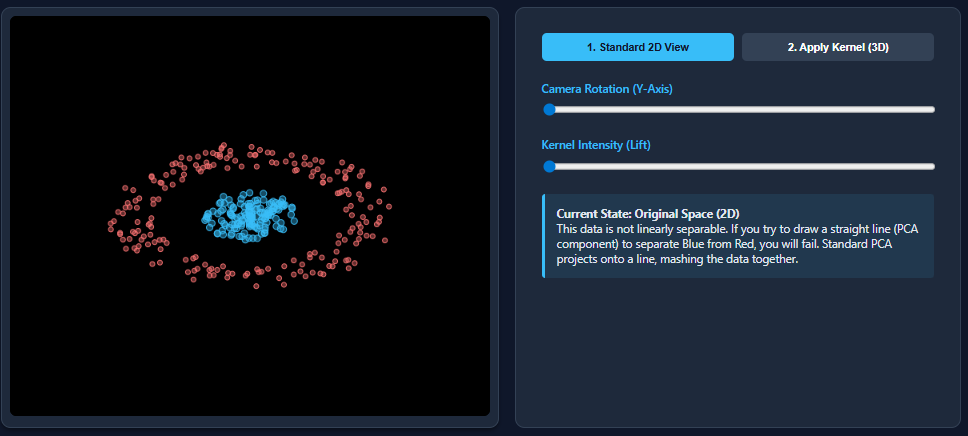
Kernel Principal Component Analysis (PCA): Explained with an ExampleMarkTechPost Dimensionality reduction techniques like PCA work wonderfully when datasets are linearly separable—but they break down the moment nonlinear patterns appear. That’s exactly what happens with datasets such as two moons: PCA flattens the structure and mixes the classes together. Kernel PCA fixes this limitation by mapping the data into a higher-dimensional feature space where nonlinear
The post Kernel Principal Component Analysis (PCA): Explained with an Example appeared first on MarkTechPost.
Dimensionality reduction techniques like PCA work wonderfully when datasets are linearly separable—but they break down the moment nonlinear patterns appear. That’s exactly what happens with datasets such as two moons: PCA flattens the structure and mixes the classes together. Kernel PCA fixes this limitation by mapping the data into a higher-dimensional feature space where nonlinear
The post Kernel Principal Component Analysis (PCA): Explained with an Example appeared first on MarkTechPost. Read More
How to Design a Fully Local Multi-Agent Orchestration System Using TinyLlama for Intelligent Task Decomposition and Autonomous CollaborationMarkTechPost In this tutorial, we explore how we can orchestrate a team of specialized AI agents locally using an efficient manager-agent architecture powered by TinyLlama. We walk through how we build structured task decomposition, inter-agent collaboration, and autonomous reasoning loops without relying on any external APIs. By running everything directly through the transformers library, we create
The post How to Design a Fully Local Multi-Agent Orchestration System Using TinyLlama for Intelligent Task Decomposition and Autonomous Collaboration appeared first on MarkTechPost.
In this tutorial, we explore how we can orchestrate a team of specialized AI agents locally using an efficient manager-agent architecture powered by TinyLlama. We walk through how we build structured task decomposition, inter-agent collaboration, and autonomous reasoning loops without relying on any external APIs. By running everything directly through the transformers library, we create
The post How to Design a Fully Local Multi-Agent Orchestration System Using TinyLlama for Intelligent Task Decomposition and Autonomous Collaboration appeared first on MarkTechPost. Read More
The Machine Learning “Advent Calendar” Day 6: Decision Tree RegressorTowards Data Science During the first days of this Machine Learning Advent Calendar, we explored models based on distances. Today, we switch to a completely different way of learning: Decision Trees.
With a simple one-feature dataset, we can see how a tree chooses its first split. The idea is always the same: if humans can guess the split visually, then we can rebuild the logic step by step in Excel.
By listing all possible split values and computing the MSE for each one, we identify the split that reduces the error the most. This gives us a clear intuition of how a Decision Tree grows, how it makes predictions, and why the first split is such a crucial step.
The post The Machine Learning “Advent Calendar” Day 6: Decision Tree Regressor appeared first on Towards Data Science.
During the first days of this Machine Learning Advent Calendar, we explored models based on distances. Today, we switch to a completely different way of learning: Decision Trees.
With a simple one-feature dataset, we can see how a tree chooses its first split. The idea is always the same: if humans can guess the split visually, then we can rebuild the logic step by step in Excel.
By listing all possible split values and computing the MSE for each one, we identify the split that reduces the error the most. This gives us a clear intuition of how a Decision Tree grows, how it makes predictions, and why the first split is such a crucial step.
The post The Machine Learning “Advent Calendar” Day 6: Decision Tree Regressor appeared first on Towards Data Science. Read More
How We Are Testing Our Agents in DevTowards Data Science Testing that your AI agent is performing as expected is not easy. Here are a few strategies we learned the hard way.
The post How We Are Testing Our Agents in Dev appeared first on Towards Data Science.
Testing that your AI agent is performing as expected is not easy. Here are a few strategies we learned the hard way.
The post How We Are Testing Our Agents in Dev appeared first on Towards Data Science. Read More
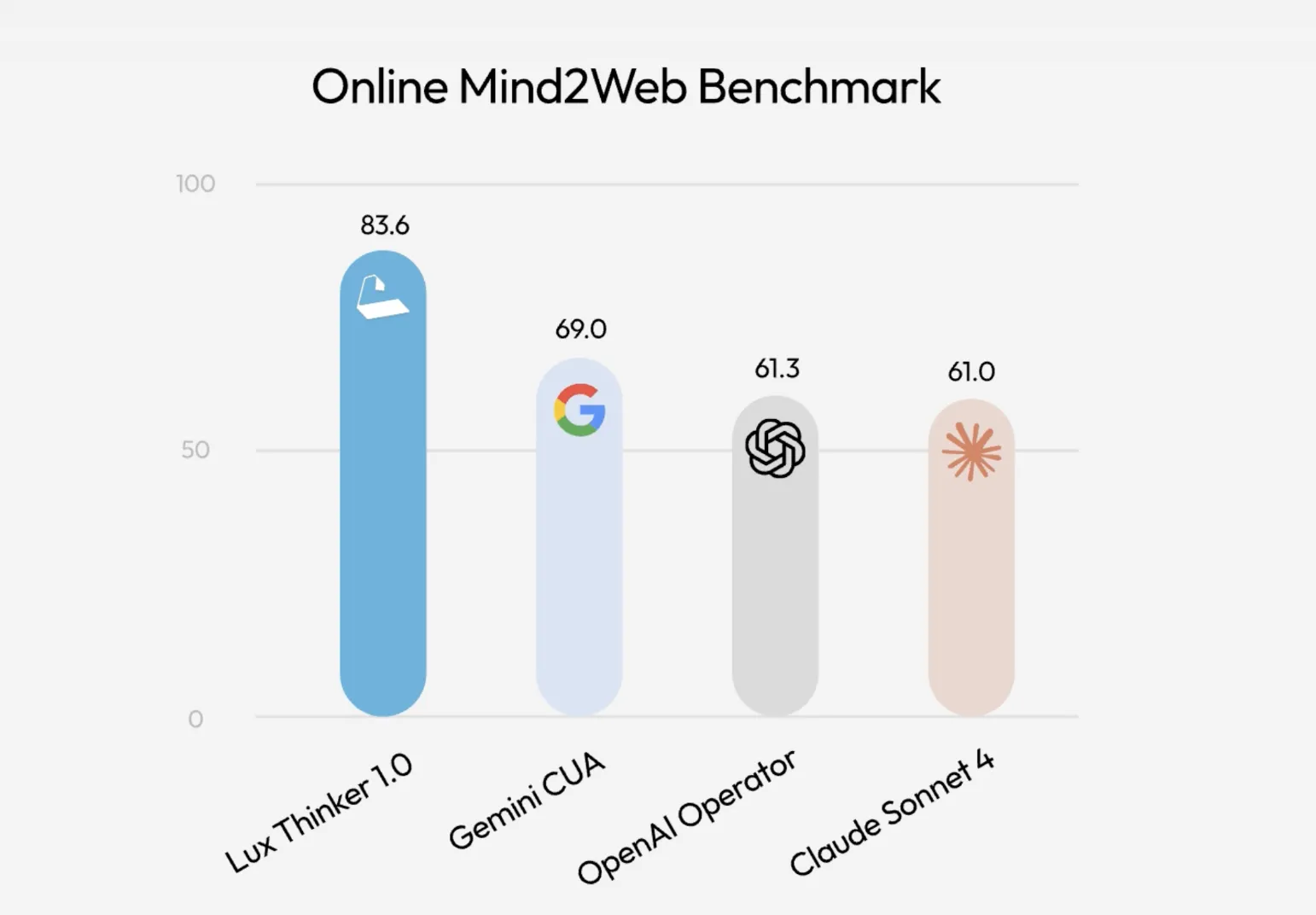
OpenAGI Foundation Launches Lux: A Foundation Computer Use Model that Tops Online Mind2Web with OSGym At ScaleMarkTechPost How do you turn slow, manual click work across browsers and desktops into a reliable, automated system that can actually use a computer for you at scale? Lux is the latest example of computer use agents moving from research demo to infrastructure. OpenAGI Foundation team has released Lux, a foundation model that operates real desktops
The post OpenAGI Foundation Launches Lux: A Foundation Computer Use Model that Tops Online Mind2Web with OSGym At Scale appeared first on MarkTechPost.
How do you turn slow, manual click work across browsers and desktops into a reliable, automated system that can actually use a computer for you at scale? Lux is the latest example of computer use agents moving from research demo to infrastructure. OpenAGI Foundation team has released Lux, a foundation model that operates real desktops
The post OpenAGI Foundation Launches Lux: A Foundation Computer Use Model that Tops Online Mind2Web with OSGym At Scale appeared first on MarkTechPost. Read More
On the Challenge of Converting TensorFlow Models to PyTorchTowards Data Science How to upgrade and optimize legacy AI/ML models
The post On the Challenge of Converting TensorFlow Models to PyTorch appeared first on Towards Data Science.
How to upgrade and optimize legacy AI/ML models
The post On the Challenge of Converting TensorFlow Models to PyTorch appeared first on Towards Data Science. Read More