
DaGRPO: Rectifying Gradient Conflict in Reasoning via Distinctiveness-Aware Group Relative Policy Optimizationcs.AI updates on arXiv.org arXiv:2512.06337v1 Announce Type: new
Abstract: The evolution of Large Language Models (LLMs) has catalyzed a paradigm shift from superficial instruction following to rigorous long-horizon reasoning. While Group Relative Policy Optimization (GRPO) has emerged as a pivotal mechanism for eliciting such post-training reasoning capabilities due to its exceptional performance, it remains plagued by significant training instability and poor sample efficiency. We theoretically identify the root cause of these issues as the lack of distinctiveness within on-policy rollouts: for routine queries, highly homogeneous samples induce destructive gradient conflicts; whereas for hard queries, the scarcity of valid positive samples results in ineffective optimization. To bridge this gap, we propose Distinctiveness-aware Group Relative Policy Optimization (DaGRPO). DaGRPO incorporates two core mechanisms: (1) Sequence-level Gradient Rectification, which utilizes fine-grained scoring to dynamically mask sample pairs with low distinctiveness, thereby eradicating gradient conflicts at the source; and (2) Off-policy Data Augmentation, which introduces high-quality anchors to recover training signals for challenging tasks. Extensive experiments across 9 mathematical reasoning and out-of-distribution (OOD) generalization benchmarks demonstrate that DaGRPO significantly surpasses existing SFT, GRPO, and hybrid baselines, achieving new state-of-the-art performance (e.g., a +4.7% average accuracy gain on math benchmarks). Furthermore, in-depth analysis confirms that DaGRPO effectively mitigates gradient explosion and accelerates the emergence of long-chain reasoning capabilities.
arXiv:2512.06337v1 Announce Type: new
Abstract: The evolution of Large Language Models (LLMs) has catalyzed a paradigm shift from superficial instruction following to rigorous long-horizon reasoning. While Group Relative Policy Optimization (GRPO) has emerged as a pivotal mechanism for eliciting such post-training reasoning capabilities due to its exceptional performance, it remains plagued by significant training instability and poor sample efficiency. We theoretically identify the root cause of these issues as the lack of distinctiveness within on-policy rollouts: for routine queries, highly homogeneous samples induce destructive gradient conflicts; whereas for hard queries, the scarcity of valid positive samples results in ineffective optimization. To bridge this gap, we propose Distinctiveness-aware Group Relative Policy Optimization (DaGRPO). DaGRPO incorporates two core mechanisms: (1) Sequence-level Gradient Rectification, which utilizes fine-grained scoring to dynamically mask sample pairs with low distinctiveness, thereby eradicating gradient conflicts at the source; and (2) Off-policy Data Augmentation, which introduces high-quality anchors to recover training signals for challenging tasks. Extensive experiments across 9 mathematical reasoning and out-of-distribution (OOD) generalization benchmarks demonstrate that DaGRPO significantly surpasses existing SFT, GRPO, and hybrid baselines, achieving new state-of-the-art performance (e.g., a +4.7% average accuracy gain on math benchmarks). Furthermore, in-depth analysis confirms that DaGRPO effectively mitigates gradient explosion and accelerates the emergence of long-chain reasoning capabilities. Read More
A Realistic Roadmap to Start an AI Career in 2026Towards Data Science How to learn AI in 2026 through real, usable projects
The post A Realistic Roadmap to Start an AI Career in 2026 appeared first on Towards Data Science.
How to learn AI in 2026 through real, usable projects
The post A Realistic Roadmap to Start an AI Career in 2026 appeared first on Towards Data Science. Read More

How people really use AI: The surprising truth from analysing billions of interactionsAI News For the past year, we’ve been told that artificial intelligence is revolutionising productivity—helping us write emails, generate code, and summarise documents. But what if the reality of how people actually use AI is completely different from what we’ve been led to believe? A data-driven study by OpenRouter has just pulled back the curtain on real-world AI usage by analysing over 100
The post How people really use AI: The surprising truth from analysing billions of interactions appeared first on AI News.
For the past year, we’ve been told that artificial intelligence is revolutionising productivity—helping us write emails, generate code, and summarise documents. But what if the reality of how people actually use AI is completely different from what we’ve been led to believe? A data-driven study by OpenRouter has just pulled back the curtain on real-world AI usage by analysing over 100
The post How people really use AI: The surprising truth from analysing billions of interactions appeared first on AI News. Read More
Newsweek: Building AI-resilience for the next era of informationAI News Artificial intelligence is transforming the way information is created, summarised, and delivered. For publishers, the shift is already visible. Search engines provide AI-generated overviews, users get answers without clicking, and content is scraped by large language models that train on decades of journalism. In this environment one question remains: How does a publisher survive when
The post Newsweek: Building AI-resilience for the next era of information appeared first on AI News.
Artificial intelligence is transforming the way information is created, summarised, and delivered. For publishers, the shift is already visible. Search engines provide AI-generated overviews, users get answers without clicking, and content is scraped by large language models that train on decades of journalism. In this environment one question remains: How does a publisher survive when
The post Newsweek: Building AI-resilience for the next era of information appeared first on AI News. Read More
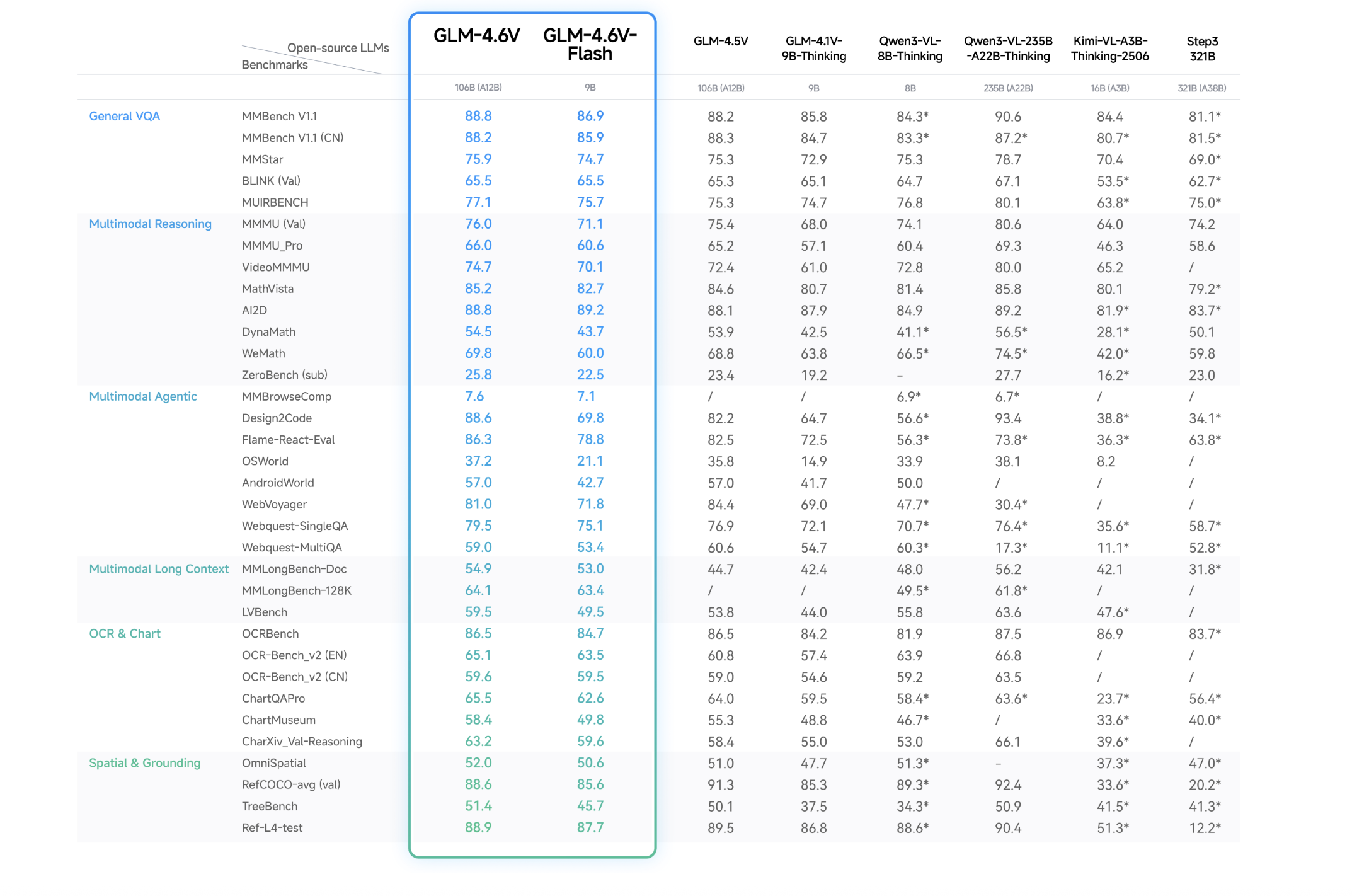
Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool CallingMarkTechPost Zhipu AI has open sourced the GLM-4.6V series as a pair of vision language models that treat images, video and tools as first class inputs for agents, not as afterthoughts bolted on top of text. Model lineup and context length The series has 2 models. GLM-4.6V is a 106B parameter foundation model for cloud and
The post Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool Calling appeared first on MarkTechPost.
Zhipu AI has open sourced the GLM-4.6V series as a pair of vision language models that treat images, video and tools as first class inputs for agents, not as afterthoughts bolted on top of text. Model lineup and context length The series has 2 models. GLM-4.6V is a 106B parameter foundation model for cloud and
The post Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool Calling appeared first on MarkTechPost. Read More
Collaborative Causal Sensemaking: Closing the Complementarity Gap in Human-AI Decision Supportcs.AI updates on arXiv.org arXiv:2512.07801v1 Announce Type: cross
Abstract: LLM-based agents are rapidly being plugged into expert decision-support, yet in messy, high-stakes settings they rarely make the team smarter: human-AI teams often underperform the best individual, experts oscillate between verification loops and over-reliance, and the promised complementarity does not materialise. We argue this is not just a matter of accuracy, but a fundamental gap in how we conceive AI assistance: expert decisions are made through collaborative cognitive processes where mental models, goals, and constraints are continually co-constructed, tested, and revised between human and AI. We propose Collaborative Causal Sensemaking (CCS) as a research agenda and organizing framework for decision-support agents: systems designed as partners in cognitive work, maintaining evolving models of how particular experts reason, helping articulate and revise goals, co-constructing and stress-testing causal hypotheses, and learning from the outcomes of joint decisions so that both human and agent improve over time. We sketch challenges around training ecologies that make collaborative thinking instrumentally valuable, representations and interaction protocols for co-authored models, and evaluation centred on trust and complementarity. These directions can reframe MAS research around agents that participate in collaborative sensemaking and act as AI teammates that think with their human partners.
arXiv:2512.07801v1 Announce Type: cross
Abstract: LLM-based agents are rapidly being plugged into expert decision-support, yet in messy, high-stakes settings they rarely make the team smarter: human-AI teams often underperform the best individual, experts oscillate between verification loops and over-reliance, and the promised complementarity does not materialise. We argue this is not just a matter of accuracy, but a fundamental gap in how we conceive AI assistance: expert decisions are made through collaborative cognitive processes where mental models, goals, and constraints are continually co-constructed, tested, and revised between human and AI. We propose Collaborative Causal Sensemaking (CCS) as a research agenda and organizing framework for decision-support agents: systems designed as partners in cognitive work, maintaining evolving models of how particular experts reason, helping articulate and revise goals, co-constructing and stress-testing causal hypotheses, and learning from the outcomes of joint decisions so that both human and agent improve over time. We sketch challenges around training ecologies that make collaborative thinking instrumentally valuable, representations and interaction protocols for co-authored models, and evaluation centred on trust and complementarity. These directions can reframe MAS research around agents that participate in collaborative sensemaking and act as AI teammates that think with their human partners. Read More
Unsupervised decoding of encoded reasoning using language model interpretabilitycs.AI updates on arXiv.org arXiv:2512.01222v2 Announce Type: replace
Abstract: As large language models become increasingly capable, there is growing concern that they may develop reasoning processes that are encoded or hidden from human oversight. To investigate whether current interpretability techniques can penetrate such encoded reasoning, we construct a controlled testbed by fine-tuning a reasoning model (DeepSeek-R1-Distill-Llama-70B) to perform chain-of-thought reasoning in ROT-13 encryption while maintaining intelligible English outputs. We evaluate mechanistic interpretability methods–in particular, logit lens analysis–on their ability to decode the model’s hidden reasoning process using only internal activations. We show that logit lens can effectively translate encoded reasoning, with accuracy peaking in intermediate-to-late layers. Finally, we develop a fully unsupervised decoding pipeline that combines logit lens with automated paraphrasing, achieving substantial accuracy in reconstructing complete reasoning transcripts from internal model representations. These findings suggest that current mechanistic interpretability techniques may be more robust to simple forms of encoded reasoning than previously understood. Our work provides an initial framework for evaluating interpretability methods against models that reason in non-human-readable formats, contributing to the broader challenge of maintaining oversight over increasingly capable AI systems.
arXiv:2512.01222v2 Announce Type: replace
Abstract: As large language models become increasingly capable, there is growing concern that they may develop reasoning processes that are encoded or hidden from human oversight. To investigate whether current interpretability techniques can penetrate such encoded reasoning, we construct a controlled testbed by fine-tuning a reasoning model (DeepSeek-R1-Distill-Llama-70B) to perform chain-of-thought reasoning in ROT-13 encryption while maintaining intelligible English outputs. We evaluate mechanistic interpretability methods–in particular, logit lens analysis–on their ability to decode the model’s hidden reasoning process using only internal activations. We show that logit lens can effectively translate encoded reasoning, with accuracy peaking in intermediate-to-late layers. Finally, we develop a fully unsupervised decoding pipeline that combines logit lens with automated paraphrasing, achieving substantial accuracy in reconstructing complete reasoning transcripts from internal model representations. These findings suggest that current mechanistic interpretability techniques may be more robust to simple forms of encoded reasoning than previously understood. Our work provides an initial framework for evaluating interpretability methods against models that reason in non-human-readable formats, contributing to the broader challenge of maintaining oversight over increasingly capable AI systems. Read More
R2MF-Net: A Recurrent Residual Multi-Path Fusion Network for Robust Multi-directional Spine X-ray Segmentationcs.AI updates on arXiv.org arXiv:2512.07576v1 Announce Type: cross
Abstract: Accurate segmentation of spinal structures in X-ray images is a prerequisite for quantitative scoliosis assessment, including Cobb angle measurement, vertebral translation estimation and curvature classification. In routine practice, clinicians acquire coronal, left-bending and right-bending radiographs to jointly evaluate deformity severity and spinal flexibility. However, the segmentation step remains heavily manual, time-consuming and non-reproducible, particularly in low-contrast images and in the presence of rib shadows or overlapping tissues. To address these limitations, this paper proposes R2MF-Net, a recurrent residual multi-path encoder–decoder network tailored for automatic segmentation of multi-directional spine X-ray images. The overall design consists of a coarse segmentation network and a fine segmentation network connected in cascade. Both stages adopt an improved Inception-style multi-branch feature extractor, while a recurrent residual jump connection (R2-Jump) module is inserted into skip paths to gradually align encoder and decoder semantics. A multi-scale cross-stage skip (MC-Skip) mechanism allows the fine network to reuse hierarchical representations from multiple decoder levels of the coarse network, thereby strengthening the stability of segmentation across imaging directions and contrast conditions. Furthermore, a lightweight spatial-channel squeeze-and-excitation block (SCSE-Lite) is employed at the bottleneck to emphasize spine-related activations and suppress irrelevant structures and background noise. We evaluate R2MF-Net on a clinical multi-view radiograph dataset comprising 228 sets of coronal, left-bending and right-bending spine X-ray images with expert annotations.
arXiv:2512.07576v1 Announce Type: cross
Abstract: Accurate segmentation of spinal structures in X-ray images is a prerequisite for quantitative scoliosis assessment, including Cobb angle measurement, vertebral translation estimation and curvature classification. In routine practice, clinicians acquire coronal, left-bending and right-bending radiographs to jointly evaluate deformity severity and spinal flexibility. However, the segmentation step remains heavily manual, time-consuming and non-reproducible, particularly in low-contrast images and in the presence of rib shadows or overlapping tissues. To address these limitations, this paper proposes R2MF-Net, a recurrent residual multi-path encoder–decoder network tailored for automatic segmentation of multi-directional spine X-ray images. The overall design consists of a coarse segmentation network and a fine segmentation network connected in cascade. Both stages adopt an improved Inception-style multi-branch feature extractor, while a recurrent residual jump connection (R2-Jump) module is inserted into skip paths to gradually align encoder and decoder semantics. A multi-scale cross-stage skip (MC-Skip) mechanism allows the fine network to reuse hierarchical representations from multiple decoder levels of the coarse network, thereby strengthening the stability of segmentation across imaging directions and contrast conditions. Furthermore, a lightweight spatial-channel squeeze-and-excitation block (SCSE-Lite) is employed at the bottleneck to emphasize spine-related activations and suppress irrelevant structures and background noise. We evaluate R2MF-Net on a clinical multi-view radiograph dataset comprising 228 sets of coronal, left-bending and right-bending spine X-ray images with expert annotations. Read More
HodgeFormer: Transformers for Learnable Operators on Triangular Meshes through Data-Driven Hodge Matricescs.AI updates on arXiv.org arXiv:2509.01839v5 Announce Type: replace-cross
Abstract: Currently, prominent Transformer architectures applied on graphs and meshes for shape analysis tasks employ traditional attention layers that heavily utilize spectral features requiring costly eigenvalue decomposition-based methods. To encode the mesh structure, these methods derive positional embeddings, that heavily rely on eigenvalue decomposition based operations, e.g. on the Laplacian matrix, or on heat-kernel signatures, which are then concatenated to the input features. This paper proposes a novel approach inspired by the explicit construction of the Hodge Laplacian operator in Discrete Exterior Calculus as a product of discrete Hodge operators and exterior derivatives, i.e. $(L := star_0^{-1} d_0^T star_1 d_0)$. We adjust the Transformer architecture in a novel deep learning layer that utilizes the multi-head attention mechanism to approximate Hodge matrices $star_0$, $star_1$ and $star_2$ and learn families of discrete operators $L$ that act on mesh vertices, edges and faces. Our approach results in a computationally-efficient architecture that achieves comparable performance in mesh segmentation and classification tasks, through a direct learning framework, while eliminating the need for costly eigenvalue decomposition operations or complex preprocessing operations.
arXiv:2509.01839v5 Announce Type: replace-cross
Abstract: Currently, prominent Transformer architectures applied on graphs and meshes for shape analysis tasks employ traditional attention layers that heavily utilize spectral features requiring costly eigenvalue decomposition-based methods. To encode the mesh structure, these methods derive positional embeddings, that heavily rely on eigenvalue decomposition based operations, e.g. on the Laplacian matrix, or on heat-kernel signatures, which are then concatenated to the input features. This paper proposes a novel approach inspired by the explicit construction of the Hodge Laplacian operator in Discrete Exterior Calculus as a product of discrete Hodge operators and exterior derivatives, i.e. $(L := star_0^{-1} d_0^T star_1 d_0)$. We adjust the Transformer architecture in a novel deep learning layer that utilizes the multi-head attention mechanism to approximate Hodge matrices $star_0$, $star_1$ and $star_2$ and learn families of discrete operators $L$ that act on mesh vertices, edges and faces. Our approach results in a computationally-efficient architecture that achieves comparable performance in mesh segmentation and classification tasks, through a direct learning framework, while eliminating the need for costly eigenvalue decomposition operations or complex preprocessing operations. Read More
How Sharp and Bias-Robust is a Model? Dual Evaluation Perspectives on Knowledge Graph Completioncs.AI updates on arXiv.org arXiv:2512.06296v1 Announce Type: new
Abstract: Knowledge graph completion (KGC) aims to predict missing facts from the observed KG. While a number of KGC models have been studied, the evaluation of KGC still remain underexplored. In this paper, we observe that existing metrics overlook two key perspectives for KGC evaluation: (A1) predictive sharpness — the degree of strictness in evaluating an individual prediction, and (A2) popularity-bias robustness — the ability to predict low-popularity entities. Toward reflecting both perspectives, we propose a novel evaluation framework (PROBE), which consists of a rank transformer (RT) estimating the score of each prediction based on a required level of predictive sharpness and a rank aggregator (RA) aggregating all the scores in a popularity-aware manner. Experiments on real-world KGs reveal that existing metrics tend to over- or under-estimate the accuracy of KGC models, whereas PROBE yields a comprehensive understanding of KGC models and reliable evaluation results.
arXiv:2512.06296v1 Announce Type: new
Abstract: Knowledge graph completion (KGC) aims to predict missing facts from the observed KG. While a number of KGC models have been studied, the evaluation of KGC still remain underexplored. In this paper, we observe that existing metrics overlook two key perspectives for KGC evaluation: (A1) predictive sharpness — the degree of strictness in evaluating an individual prediction, and (A2) popularity-bias robustness — the ability to predict low-popularity entities. Toward reflecting both perspectives, we propose a novel evaluation framework (PROBE), which consists of a rank transformer (RT) estimating the score of each prediction based on a required level of predictive sharpness and a rank aggregator (RA) aggregating all the scores in a popularity-aware manner. Experiments on real-world KGs reveal that existing metrics tend to over- or under-estimate the accuracy of KGC models, whereas PROBE yields a comprehensive understanding of KGC models and reliable evaluation results. Read More