
EpiPlanAgent: Agentic Automated Epidemic Response Planningcs.AI updates on arXiv.org arXiv:2512.10313v2 Announce Type: replace
Abstract: Epidemic response planning is essential yet traditionally reliant on labor-intensive manual methods. This study aimed to design and evaluate EpiPlanAgent, an agent-based system using large language models (LLMs) to automate the generation and validation of digital emergency response plans. The multi-agent framework integrated task decomposition, knowledge grounding, and simulation modules. Public health professionals tested the system using real-world outbreak scenarios in a controlled evaluation. Results demonstrated that EpiPlanAgent significantly improved the completeness and guideline alignment of plans while drastically reducing development time compared to manual workflows. Expert evaluation confirmed high consistency between AI-generated and human-authored content. User feedback indicated strong perceived utility. In conclusion, EpiPlanAgent provides an effective, scalable solution for intelligent epidemic response planning, demonstrating the potential of agentic AI to transform public health preparedness.
arXiv:2512.10313v2 Announce Type: replace
Abstract: Epidemic response planning is essential yet traditionally reliant on labor-intensive manual methods. This study aimed to design and evaluate EpiPlanAgent, an agent-based system using large language models (LLMs) to automate the generation and validation of digital emergency response plans. The multi-agent framework integrated task decomposition, knowledge grounding, and simulation modules. Public health professionals tested the system using real-world outbreak scenarios in a controlled evaluation. Results demonstrated that EpiPlanAgent significantly improved the completeness and guideline alignment of plans while drastically reducing development time compared to manual workflows. Expert evaluation confirmed high consistency between AI-generated and human-authored content. User feedback indicated strong perceived utility. In conclusion, EpiPlanAgent provides an effective, scalable solution for intelligent epidemic response planning, demonstrating the potential of agentic AI to transform public health preparedness. Read More
The Skills That Bridge Technical Work and Business ImpactTowards Data Science In the Author Spotlight series, TDS Editors chat with members of our community about their career path in data science and AI, their writing, and their sources of inspiration. Today, we’re thrilled to share our conversation with Maria Mouschoutzi. Maria is a Data Analyst and Project Manager with a strong background in Operations Research, Mechanical
The post The Skills That Bridge Technical Work and Business Impact appeared first on Towards Data Science.
In the Author Spotlight series, TDS Editors chat with members of our community about their career path in data science and AI, their writing, and their sources of inspiration. Today, we’re thrilled to share our conversation with Maria Mouschoutzi. Maria is a Data Analyst and Project Manager with a strong background in Operations Research, Mechanical
The post The Skills That Bridge Technical Work and Business Impact appeared first on Towards Data Science. Read More
The Machine Learning “Advent Calendar” Day 14: Softmax Regression in ExcelTowards Data Science Softmax Regression is simply Logistic Regression extended to multiple classes.
By computing one linear score per class and normalizing them with Softmax, we obtain multiclass probabilities without changing the core logic.
The loss, the gradients, and the optimization remain the same.
Only the number of parallel scores increases.
Implemented in Excel, the model becomes transparent: you can see the scores, the probabilities, and how the coefficients evolve over time.
The post The Machine Learning “Advent Calendar” Day 14: Softmax Regression in Excel appeared first on Towards Data Science.
Softmax Regression is simply Logistic Regression extended to multiple classes.
By computing one linear score per class and normalizing them with Softmax, we obtain multiclass probabilities without changing the core logic.
The loss, the gradients, and the optimization remain the same.
Only the number of parallel scores increases.
Implemented in Excel, the model becomes transparent: you can see the scores, the probabilities, and how the coefficients evolve over time.
The post The Machine Learning “Advent Calendar” Day 14: Softmax Regression in Excel appeared first on Towards Data Science. Read More
Lessons Learned from Upgrading to LangChain 1.0 in ProductionTowards Data Science What worked, what broke, and why I did it
The post Lessons Learned from Upgrading to LangChain 1.0 in Production appeared first on Towards Data Science.
What worked, what broke, and why I did it
The post Lessons Learned from Upgrading to LangChain 1.0 in Production appeared first on Towards Data Science. Read More

Walmart’s AI strategy: Beyond the hype, what’s actually workingAI News Walmart’s December 9 transfer to Nasdaq wasn’t just a symbolic gesture. The US$905 billion retailer is making its boldest claim yet: that it’s no longer a traditional discount chain, but a tech-powered enterprise using AI to fundamentally rewire its retail operations. But beyond the marketing spin and the parade of AI announcements, what’s genuinely transforming
The post Walmart’s AI strategy: Beyond the hype, what’s actually working appeared first on AI News.
Walmart’s December 9 transfer to Nasdaq wasn’t just a symbolic gesture. The US$905 billion retailer is making its boldest claim yet: that it’s no longer a traditional discount chain, but a tech-powered enterprise using AI to fundamentally rewire its retail operations. But beyond the marketing spin and the parade of AI announcements, what’s genuinely transforming
The post Walmart’s AI strategy: Beyond the hype, what’s actually working appeared first on AI News. Read More

Deep-learning model predicts how fruit flies form, cell by cellMIT News – Machine learning The approach could apply to more complex tissues and organs, helping researchers to identify early signs of disease.
The approach could apply to more complex tissues and organs, helping researchers to identify early signs of disease. Read More
Meta-Statistical Learning: Supervised Learning of Statistical Estimatorscs.AI updates on arXiv.org arXiv:2502.12088v3 Announce Type: replace-cross
Abstract: Statistical inference, a central tool of science, revolves around the study and the usage of statistical estimators: functions that map finite samples to predictions about unknown distribution parameters. In the frequentist framework, estimators are evaluated based on properties such as bias, variance (for parameter estimation), accuracy, power, and calibration (for hypothesis testing). However, crafting estimators with desirable properties is often analytically challenging, and sometimes impossible, e.g., there exists no universally unbiased estimator for the standard deviation. In this work, we introduce meta-statistical learning, an amortized learning framework that recasts estimator design as an optimization problem via supervised learning. This takes a fully empirical approach to discovering statistical estimators; entire datasets are input to permutation-invariant neural networks, such as Set Transformers, trained to predict the target statistical property. The trained model is the estimator, and can be analyzed through the classical frequentist lens. We demonstrate the approach on two tasks: learning a normality test (classification) and estimating mutual information (regression), achieving strong results even with small models. Looking ahead, this paradigm opens a path to automate the discovery of generalizable and flexible statistical estimators.
arXiv:2502.12088v3 Announce Type: replace-cross
Abstract: Statistical inference, a central tool of science, revolves around the study and the usage of statistical estimators: functions that map finite samples to predictions about unknown distribution parameters. In the frequentist framework, estimators are evaluated based on properties such as bias, variance (for parameter estimation), accuracy, power, and calibration (for hypothesis testing). However, crafting estimators with desirable properties is often analytically challenging, and sometimes impossible, e.g., there exists no universally unbiased estimator for the standard deviation. In this work, we introduce meta-statistical learning, an amortized learning framework that recasts estimator design as an optimization problem via supervised learning. This takes a fully empirical approach to discovering statistical estimators; entire datasets are input to permutation-invariant neural networks, such as Set Transformers, trained to predict the target statistical property. The trained model is the estimator, and can be analyzed through the classical frequentist lens. We demonstrate the approach on two tasks: learning a normality test (classification) and estimating mutual information (regression), achieving strong results even with small models. Looking ahead, this paradigm opens a path to automate the discovery of generalizable and flexible statistical estimators. Read More
Q${}^2$Forge: Minting Competency Questions and SPARQL Queries for Question-Answering Over Knowledge Graphscs.AI updates on arXiv.org arXiv:2505.13572v3 Announce Type: replace-cross
Abstract: The SPARQL query language is the standard method to access knowledge graphs (KGs). However, formulating SPARQL queries is a significant challenge for non-expert users, and remains time-consuming for the experienced ones. Best practices recommend to document KGs with competency questions and example queries to contextualise the knowledge they contain and illustrate their potential applications. In practice, however, this is either not the case or the examples are provided in limited numbers. Large Language Models (LLMs) are being used in conversational agents and are proving to be an attractive solution with a wide range of applications, from simple question-answering about common knowledge to generating code in a targeted programming language. However, training and testing these models to produce high quality SPARQL queries from natural language questions requires substantial datasets of question-query pairs. In this paper, we present Q${}^2$Forge that addresses the challenge of generating new competency questions for a KG and corresponding SPARQL queries. It iteratively validates those queries with human feedback and LLM as a judge. Q${}^2$Forge is open source, generic, extensible and modular, meaning that the different modules of the application (CQ generation, query generation and query refinement) can be used separately, as an integrated pipeline, or replaced by alternative services. The result is a complete pipeline from competency question formulation to query evaluation, supporting the creation of reference query sets for any target KG.
arXiv:2505.13572v3 Announce Type: replace-cross
Abstract: The SPARQL query language is the standard method to access knowledge graphs (KGs). However, formulating SPARQL queries is a significant challenge for non-expert users, and remains time-consuming for the experienced ones. Best practices recommend to document KGs with competency questions and example queries to contextualise the knowledge they contain and illustrate their potential applications. In practice, however, this is either not the case or the examples are provided in limited numbers. Large Language Models (LLMs) are being used in conversational agents and are proving to be an attractive solution with a wide range of applications, from simple question-answering about common knowledge to generating code in a targeted programming language. However, training and testing these models to produce high quality SPARQL queries from natural language questions requires substantial datasets of question-query pairs. In this paper, we present Q${}^2$Forge that addresses the challenge of generating new competency questions for a KG and corresponding SPARQL queries. It iteratively validates those queries with human feedback and LLM as a judge. Q${}^2$Forge is open source, generic, extensible and modular, meaning that the different modules of the application (CQ generation, query generation and query refinement) can be used separately, as an integrated pipeline, or replaced by alternative services. The result is a complete pipeline from competency question formulation to query evaluation, supporting the creation of reference query sets for any target KG. Read More
How to Increase Coding Iteration SpeedTowards Data Science Learn how to become a more efficient programmer with local testing
The post How to Increase Coding Iteration Speed appeared first on Towards Data Science.
Learn how to become a more efficient programmer with local testing
The post How to Increase Coding Iteration Speed appeared first on Towards Data Science. Read More
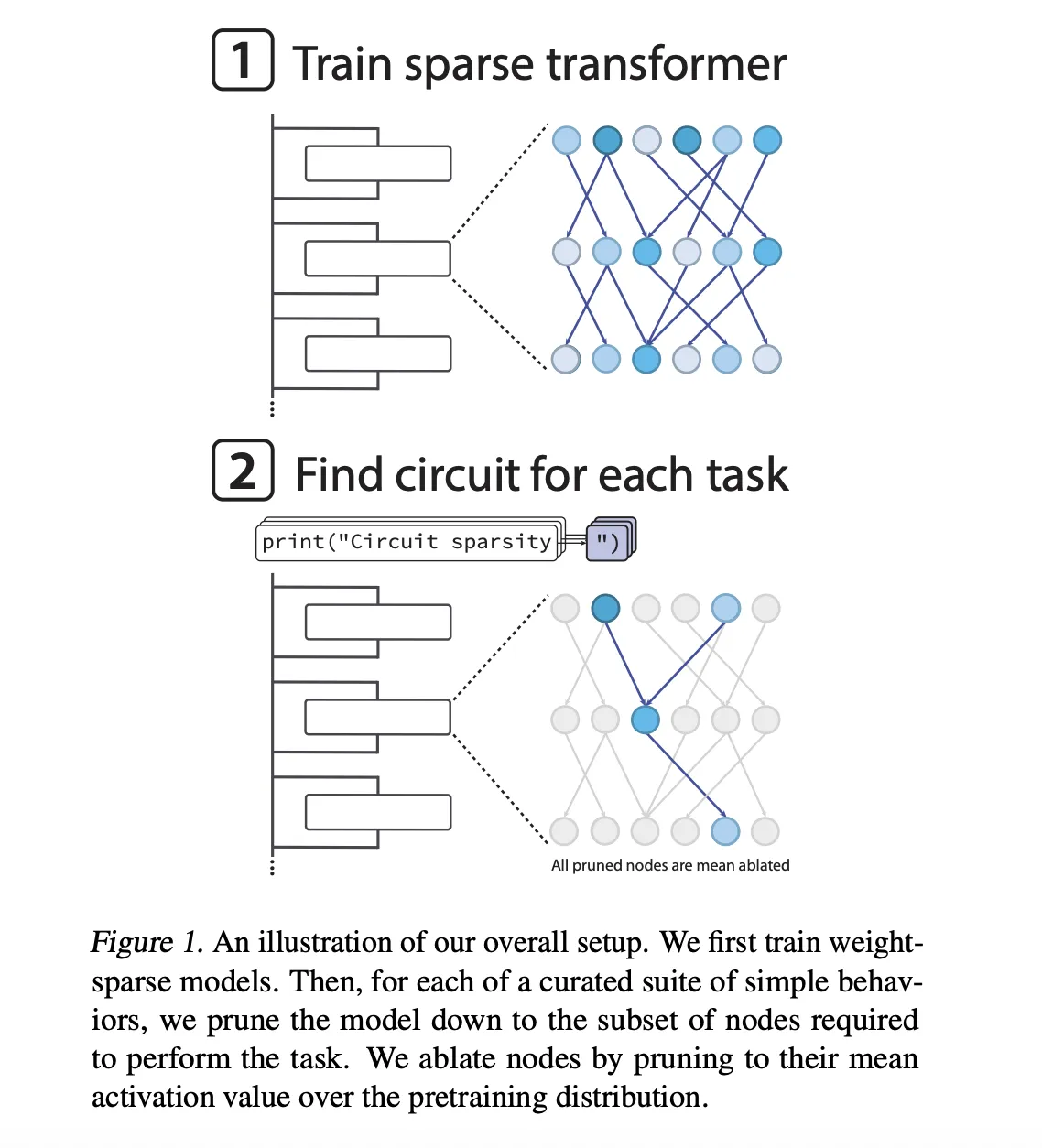
OpenAI has Released the ‘circuit-sparsity’: A Set of Open Tools for Connecting Weight Sparse Models and Dense Baselines through Activation BridgesMarkTechPost OpenAI team has released their openai/circuit-sparsity model on Hugging Face and the openai/circuit_sparsity toolkit on GitHub. The release packages the models and circuits from the paper ‘Weight-sparse transformers have interpretable circuits‘. What is a weight sparse transformer? The models are GPT-2 style decoder only transformers trained on Python code. Sparsity is not added after training,
The post OpenAI has Released the ‘circuit-sparsity’: A Set of Open Tools for Connecting Weight Sparse Models and Dense Baselines through Activation Bridges appeared first on MarkTechPost.
OpenAI team has released their openai/circuit-sparsity model on Hugging Face and the openai/circuit_sparsity toolkit on GitHub. The release packages the models and circuits from the paper ‘Weight-sparse transformers have interpretable circuits‘. What is a weight sparse transformer? The models are GPT-2 style decoder only transformers trained on Python code. Sparsity is not added after training,
The post OpenAI has Released the ‘circuit-sparsity’: A Set of Open Tools for Connecting Weight Sparse Models and Dense Baselines through Activation Bridges appeared first on MarkTechPost. Read More