
Superposition as Lossy Compression: Measure with Sparse Autoencoders and Connect to Adversarial Vulnerabilitycs.AI updates on arXiv.org arXiv:2512.13568v1 Announce Type: cross
Abstract: Neural networks achieve remarkable performance through superposition: encoding multiple features as overlapping directions in activation space rather than dedicating individual neurons to each feature. This challenges interpretability, yet we lack principled methods to measure superposition. We present an information-theoretic framework measuring a neural representation’s effective degrees of freedom. We apply Shannon entropy to sparse autoencoder activations to compute the number of effective features as the minimum neurons needed for interference-free encoding. Equivalently, this measures how many “virtual neurons” the network simulates through superposition. When networks encode more effective features than actual neurons, they must accept interference as the price of compression. Our metric strongly correlates with ground truth in toy models, detects minimal superposition in algorithmic tasks, and reveals systematic reduction under dropout. Layer-wise patterns mirror intrinsic dimensionality studies on Pythia-70M. The metric also captures developmental dynamics, detecting sharp feature consolidation during grokking. Surprisingly, adversarial training can increase effective features while improving robustness, contradicting the hypothesis that superposition causes vulnerability. Instead, the effect depends on task complexity and network capacity: simple tasks with ample capacity allow feature expansion (abundance regime), while complex tasks or limited capacity force reduction (scarcity regime). By defining superposition as lossy compression, this work enables principled measurement of how neural networks organize information under computational constraints, connecting superposition to adversarial robustness.
arXiv:2512.13568v1 Announce Type: cross
Abstract: Neural networks achieve remarkable performance through superposition: encoding multiple features as overlapping directions in activation space rather than dedicating individual neurons to each feature. This challenges interpretability, yet we lack principled methods to measure superposition. We present an information-theoretic framework measuring a neural representation’s effective degrees of freedom. We apply Shannon entropy to sparse autoencoder activations to compute the number of effective features as the minimum neurons needed for interference-free encoding. Equivalently, this measures how many “virtual neurons” the network simulates through superposition. When networks encode more effective features than actual neurons, they must accept interference as the price of compression. Our metric strongly correlates with ground truth in toy models, detects minimal superposition in algorithmic tasks, and reveals systematic reduction under dropout. Layer-wise patterns mirror intrinsic dimensionality studies on Pythia-70M. The metric also captures developmental dynamics, detecting sharp feature consolidation during grokking. Surprisingly, adversarial training can increase effective features while improving robustness, contradicting the hypothesis that superposition causes vulnerability. Instead, the effect depends on task complexity and network capacity: simple tasks with ample capacity allow feature expansion (abundance regime), while complex tasks or limited capacity force reduction (scarcity regime). By defining superposition as lossy compression, this work enables principled measurement of how neural networks organize information under computational constraints, connecting superposition to adversarial robustness. Read More
Adaptive-lambda Subtracted Importance Sampled Scores in Machine Unlearning for DDPMs and VAEscs.AI updates on arXiv.org arXiv:2512.01054v2 Announce Type: replace-cross
Abstract: Machine Unlearning is essential for large generative models (VAEs, DDPMs) to comply with the right to be forgotten and prevent undesired content generation without costly retraining. Existing approaches, such as Static-lambda SISS for diffusion models, rely on a fixed mixing weight lambda, which is suboptimal because the required unlearning strength varies across samples and training stages.
We propose Adaptive-lambda SISS, a principled extension that turns lambda into a latent variable dynamically inferred at each training step. A lightweight inference network parameterizes an adaptive posterior over lambda, conditioned on contextual features derived from the instantaneous SISS loss terms (retain/forget losses and their gradients). This enables joint optimization of the diffusion model and the lambda-inference mechanism via a variational objective, yielding significantly better trade-offs.
We further extend the adaptive-lambda principle to score-based unlearning and introduce a multi-class variant of Score Forgetting Distillation. In addition, we present two new directions: (i) a hybrid objective combining the data-free efficiency of Score Forgetting Distillation with the direct gradient control of SISS, and (ii) a Reinforcement Learning formulation that treats unlearning as a sequential decision process, learning an optimal policy over a state space defined by the model’s current memory of the forget set.
Experiments on an augmented MNIST benchmark show that Adaptive-lambda SISS substantially outperforms the original static-lambda SISS, achieving stronger removal of forgotten classes while better preserving generation quality on the retain set.
arXiv:2512.01054v2 Announce Type: replace-cross
Abstract: Machine Unlearning is essential for large generative models (VAEs, DDPMs) to comply with the right to be forgotten and prevent undesired content generation without costly retraining. Existing approaches, such as Static-lambda SISS for diffusion models, rely on a fixed mixing weight lambda, which is suboptimal because the required unlearning strength varies across samples and training stages.
We propose Adaptive-lambda SISS, a principled extension that turns lambda into a latent variable dynamically inferred at each training step. A lightweight inference network parameterizes an adaptive posterior over lambda, conditioned on contextual features derived from the instantaneous SISS loss terms (retain/forget losses and their gradients). This enables joint optimization of the diffusion model and the lambda-inference mechanism via a variational objective, yielding significantly better trade-offs.
We further extend the adaptive-lambda principle to score-based unlearning and introduce a multi-class variant of Score Forgetting Distillation. In addition, we present two new directions: (i) a hybrid objective combining the data-free efficiency of Score Forgetting Distillation with the direct gradient control of SISS, and (ii) a Reinforcement Learning formulation that treats unlearning as a sequential decision process, learning an optimal policy over a state space defined by the model’s current memory of the forget set.
Experiments on an augmented MNIST benchmark show that Adaptive-lambda SISS substantially outperforms the original static-lambda SISS, achieving stronger removal of forgotten classes while better preserving generation quality on the retain set. Read More
Multimodal DeepResearcher: Generating Text-Chart Interleaved Reports From Scratch with Agentic Frameworkcs.AI updates on arXiv.org arXiv:2506.02454v3 Announce Type: replace-cross
Abstract: Visualizations play a crucial part in effective communication of concepts and information. Recent advances in reasoning and retrieval augmented generation have enabled Large Language Models (LLMs) to perform deep research and generate comprehensive reports. Despite its progress, existing deep research frameworks primarily focus on generating text-only content, leaving the automated generation of interleaved texts and visualizations underexplored. This novel task poses key challenges in designing informative visualizations and effectively integrating them with text reports. To address these challenges, we propose Formal Description of Visualization (FDV), a structured textual representation of charts that enables LLMs to learn from and generate diverse, high-quality visualizations. Building on this representation, we introduce Multimodal DeepResearcher, an agentic framework that decomposes the task into four stages: (1) researching, (2) exemplar report textualization, (3) planning, and (4) multimodal report generation. For the evaluation of generated multimodal reports, we develop MultimodalReportBench, which contains 100 diverse topics served as inputs along with 5 dedicated metrics. Extensive experiments across models and evaluation methods demonstrate the effectiveness of Multimodal DeepResearcher. Notably, utilizing the same Claude 3.7 Sonnet model, Multimodal DeepResearcher achieves an 82% overall win rate over the baseline method.
arXiv:2506.02454v3 Announce Type: replace-cross
Abstract: Visualizations play a crucial part in effective communication of concepts and information. Recent advances in reasoning and retrieval augmented generation have enabled Large Language Models (LLMs) to perform deep research and generate comprehensive reports. Despite its progress, existing deep research frameworks primarily focus on generating text-only content, leaving the automated generation of interleaved texts and visualizations underexplored. This novel task poses key challenges in designing informative visualizations and effectively integrating them with text reports. To address these challenges, we propose Formal Description of Visualization (FDV), a structured textual representation of charts that enables LLMs to learn from and generate diverse, high-quality visualizations. Building on this representation, we introduce Multimodal DeepResearcher, an agentic framework that decomposes the task into four stages: (1) researching, (2) exemplar report textualization, (3) planning, and (4) multimodal report generation. For the evaluation of generated multimodal reports, we develop MultimodalReportBench, which contains 100 diverse topics served as inputs along with 5 dedicated metrics. Extensive experiments across models and evaluation methods demonstrate the effectiveness of Multimodal DeepResearcher. Notably, utilizing the same Claude 3.7 Sonnet model, Multimodal DeepResearcher achieves an 82% overall win rate over the baseline method. Read More

5 Workflow Automation Tools for All ProfessionalsKDnuggets Five powerful automation tools to help you streamline repetitive digital tasks, increase productivity, and create smarter workflows without requiring deep technical skills.
Five powerful automation tools to help you streamline repetitive digital tasks, increase productivity, and create smarter workflows without requiring deep technical skills. Read More

Mining business learnings for AI deploymentAI News Mining conglomerate BHP describes AI as the way it’s turning operational data into better day-to-day decisions. A blog post from the company highlights the analysis of data from sensors and monitoring systems to spot patterns and flag issues for plant machinery, giving choices to decision-makers that can improve efficiency and safety – plus reduce environmental
The post Mining business learnings for AI deployment appeared first on AI News.
Mining conglomerate BHP describes AI as the way it’s turning operational data into better day-to-day decisions. A blog post from the company highlights the analysis of data from sensors and monitoring systems to spot patterns and flag issues for plant machinery, giving choices to decision-makers that can improve efficiency and safety – plus reduce environmental
The post Mining business learnings for AI deployment appeared first on AI News. Read More
AWS’s legacy will be in AI successAI News As the company that kick-started the cloud computing revolution, Amazon is one of the world’s biggest companies whose practices in all things technological can be regarded as a blueprint for implementing new technology. This article looks at some of the ways that the company is deploying AI in its operations. Amazon’s latest AI strategy has
The post AWS’s legacy will be in AI success appeared first on AI News.
As the company that kick-started the cloud computing revolution, Amazon is one of the world’s biggest companies whose practices in all things technological can be regarded as a blueprint for implementing new technology. This article looks at some of the ways that the company is deploying AI in its operations. Amazon’s latest AI strategy has
The post AWS’s legacy will be in AI success appeared first on AI News. Read More
Geospatial exploratory data analysis with GeoPandas and DuckDBTowards Data Science In this article, I’ll show you how to use two popular Python libraries to carry out some geospatial analysis of traffic accident data within the UK. I was a relatively early adopter of DuckDB, the fast OLAP database, after it became available, but only recently realised that, through an extension, it offered a large number
The post Geospatial exploratory data analysis with GeoPandas and DuckDB appeared first on Towards Data Science.
In this article, I’ll show you how to use two popular Python libraries to carry out some geospatial analysis of traffic accident data within the UK. I was a relatively early adopter of DuckDB, the fast OLAP database, after it became available, but only recently realised that, through an extension, it offered a large number
The post Geospatial exploratory data analysis with GeoPandas and DuckDB appeared first on Towards Data Science. Read More
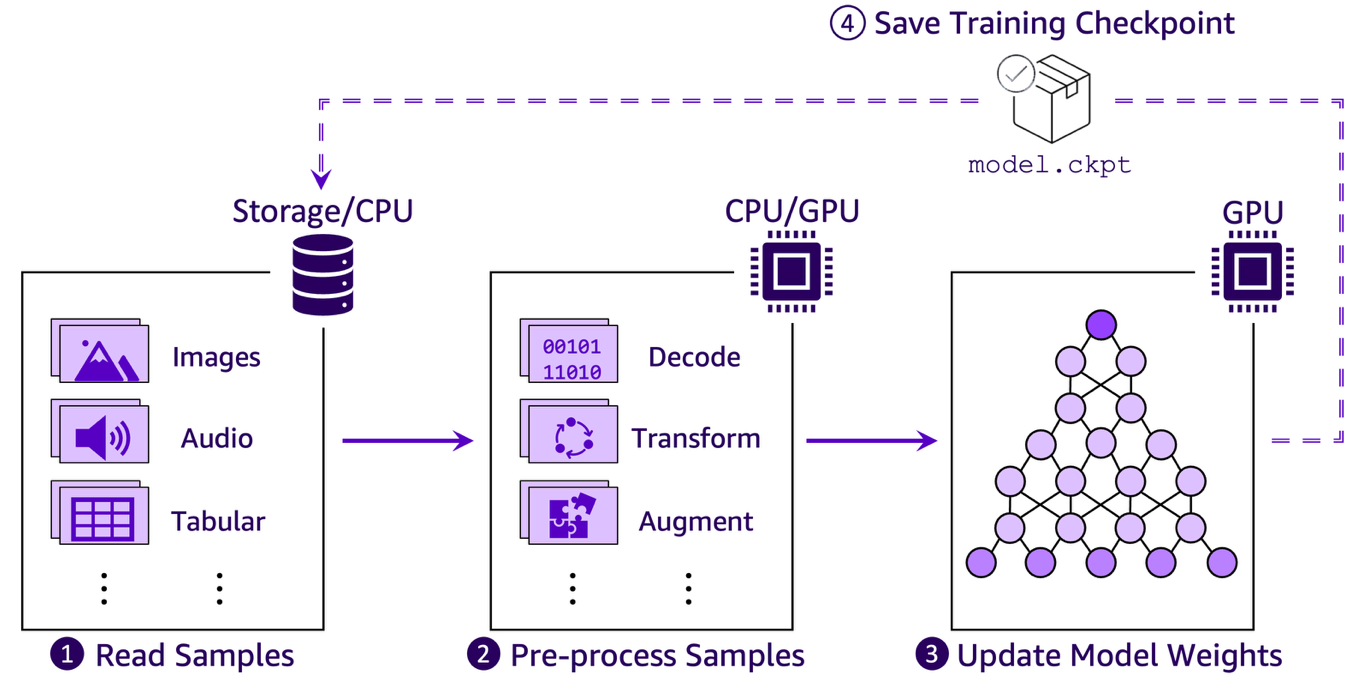
Applying data loading best practices for ML training with Amazon S3 clientsArtificial Intelligence In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets.
In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets. Read More

The Data Detox: Training Yourself for the Messy, Noisy, Real WorldKDnuggets In this article, we’ll use a real-life data project to explore four practical steps for preparing to deal with messy, real-life datasets.
In this article, we’ll use a real-life data project to explore four practical steps for preparing to deal with messy, real-life datasets. Read More
6 Technical Skills That Make You a Senior Data ScientistTowards Data Science Beyond writing code, these are the design-level decisions, trade-offs, and habits that quietly separate senior data scientists from everyone else.
The post 6 Technical Skills That Make You a Senior Data Scientist appeared first on Towards Data Science.
Beyond writing code, these are the design-level decisions, trade-offs, and habits that quietly separate senior data scientists from everyone else.
The post 6 Technical Skills That Make You a Senior Data Scientist appeared first on Towards Data Science. Read More