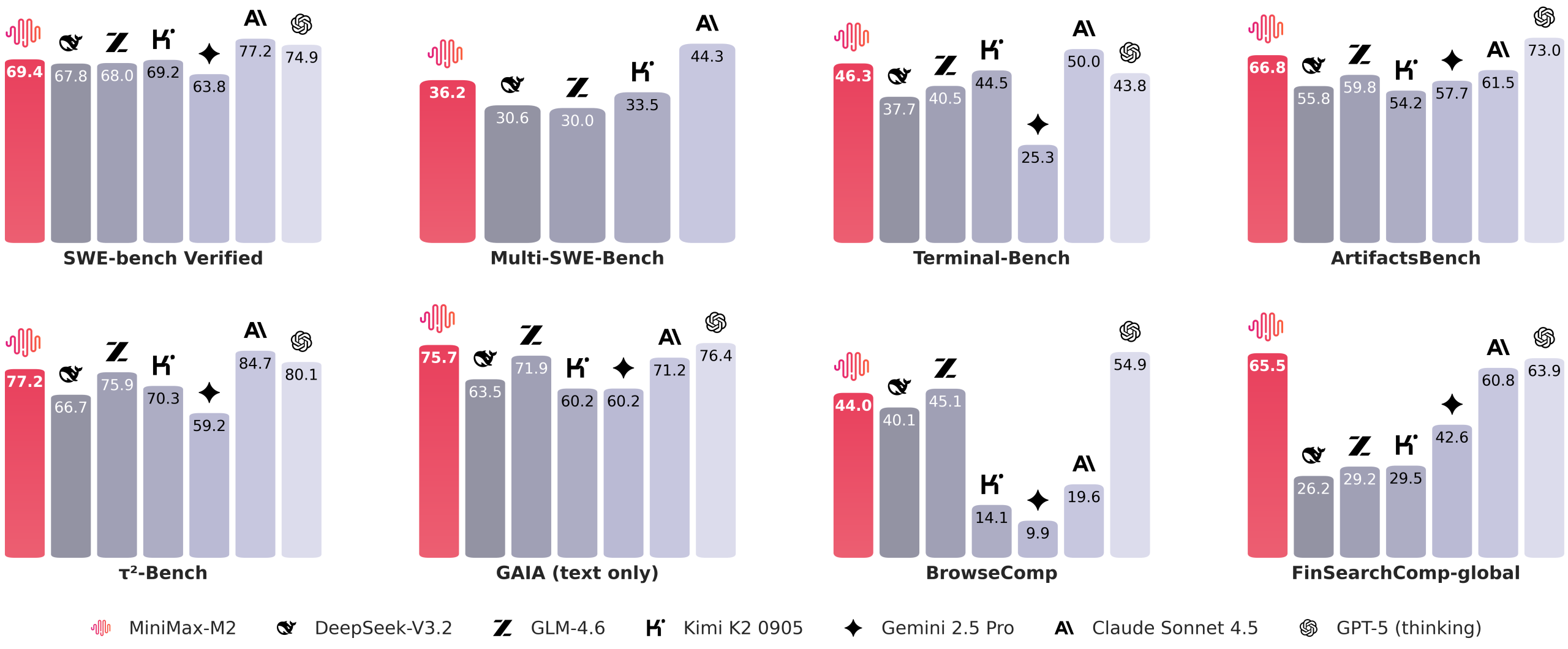
MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x FasterMarkTechPost Can an open source MoE truly power agentic coding workflows at a fraction of flagship model costs while sustaining long-horizon tool use across MCP, shell, browser, retrieval, and code? MiniMax team has just released MiniMax-M2, a mixture of experts MoE model optimized for coding and agent workflows. The weights are published on Hugging Face under
The post MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster appeared first on MarkTechPost.
Can an open source MoE truly power agentic coding workflows at a fraction of flagship model costs while sustaining long-horizon tool use across MCP, shell, browser, retrieval, and code? MiniMax team has just released MiniMax-M2, a mixture of experts MoE model optimized for coding and agent workflows. The weights are published on Hugging Face under
The post MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster appeared first on MarkTechPost. Read More

Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood)Towards Data Science Can I use NumPy to figure out how my habits affect my mood and productivity?
The post Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood) appeared first on Towards Data Science.
Can I use NumPy to figure out how my habits affect my mood and productivity?
The post Using NumPy to Analyze My Daily Habits (Sleep, Screen Time & Mood) appeared first on Towards Data Science. Read More
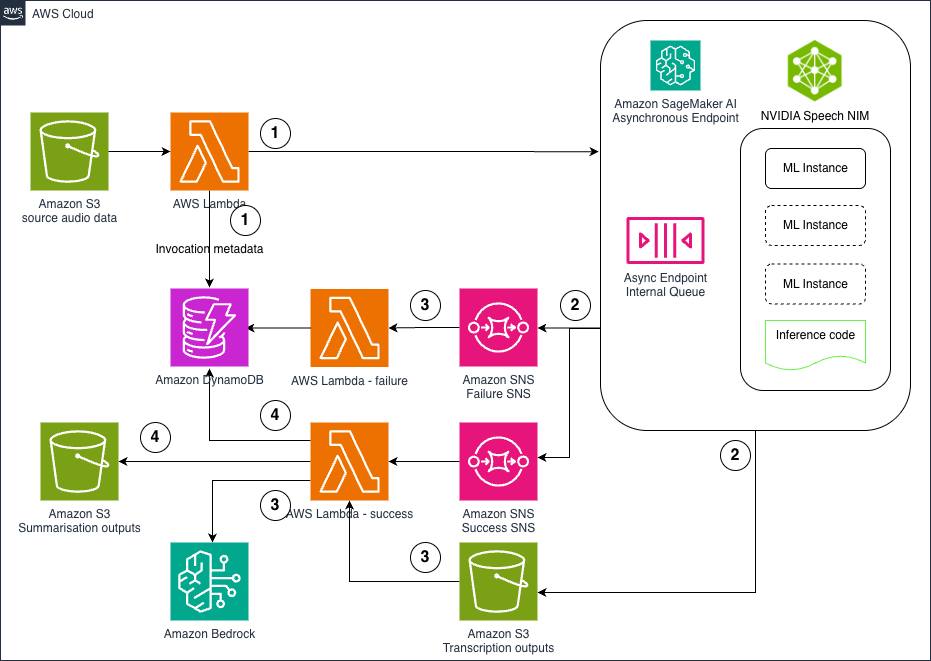
Hosting NVIDIA speech NIM models on Amazon SageMaker AI: Parakeet ASRArtificial Intelligence In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale .
In this post, we explore how to deploy NVIDIA’s Parakeet ASR model on Amazon SageMaker AI using asynchronous inference endpoints to create a scalable, cost-effective pipeline for processing large volumes of audio data. The solution combines state-of-the-art speech recognition capabilities with AWS managed services like Lambda, S3, and Bedrock to automatically transcribe audio files and generate intelligent summaries, enabling organizations to unlock valuable insights from customer calls, meeting recordings, and other audio content at scale . Read More
Deep Reinforcement Learning: 0 to 100Towards Data Science Using RL to teach robots to fly a drone
The post Deep Reinforcement Learning: 0 to 100 appeared first on Towards Data Science.
Using RL to teach robots to fly a drone
The post Deep Reinforcement Learning: 0 to 100 appeared first on Towards Data Science. Read More
Using Claude Skills with Neo4jTowards Data Science A hands-on exploration of Claude Skills and their potential applications in Neo4j
The post Using Claude Skills with Neo4j appeared first on Towards Data Science.
A hands-on exploration of Claude Skills and their potential applications in Neo4j
The post Using Claude Skills with Neo4j appeared first on Towards Data Science. Read More

API Development for Web Apps and Data ProductsKDnuggets Application programming interfaces are essential for modern web applications and data products. They allow different systems to communicate with each other and share data securely.
Application programming interfaces are essential for modern web applications and data products. They allow different systems to communicate with each other and share data securely. Read More
Water Cooler Small Talk, Ep. 9: What “Thinking” and “Reasoning” Really Mean in AI and LLMsTowards Data Science Understanding how AI models “reason” and why it’s not what humans do when we think
The post Water Cooler Small Talk, Ep. 9: What “Thinking” and “Reasoning” Really Mean in AI and LLMs appeared first on Towards Data Science.
Understanding how AI models “reason” and why it’s not what humans do when we think
The post Water Cooler Small Talk, Ep. 9: What “Thinking” and “Reasoning” Really Mean in AI and LLMs appeared first on Towards Data Science. Read More
Exploration through Generation: Applying GFlowNets to Structured Searchcs.AI updates on arXiv.org arXiv:2510.21886v1 Announce Type: new
Abstract: This work applies Generative Flow Networks (GFlowNets) to three graph optimization problems: the Traveling Salesperson Problem, Minimum Spanning Tree, and Shortest Path. GFlowNets are generative models that learn to sample solutions proportionally to a reward function. The models are trained using the Trajectory Balance loss to build solutions sequentially, se- lecting edges for spanning trees, nodes for paths, and cities for tours. Experiments on benchmark instances of varying sizes show that GFlowNets learn to find optimal solutions. For each problem type, multiple graph configurations with different numbers of nodes were tested. The generated solutions match those from classical algorithms (Dijkstra for shortest path, Kruskal for spanning trees, and exact solvers for TSP). Training convergence depends on problem complexity, with the number of episodes required for loss stabilization increasing as graph size grows. Once training converges, the generated solutions match known optima from classical algorithms across the tested instances. This work demonstrates that generative models can solve combinatorial optimization problems through learned policies. The main advantage of this learning-based approach is computational scalability: while classical algorithms have fixed complexity per instance, GFlowNets amortize computation through training. With sufficient computational resources, the framework could potentially scale to larger problem instances where classical exact methods become infeasible.
arXiv:2510.21886v1 Announce Type: new
Abstract: This work applies Generative Flow Networks (GFlowNets) to three graph optimization problems: the Traveling Salesperson Problem, Minimum Spanning Tree, and Shortest Path. GFlowNets are generative models that learn to sample solutions proportionally to a reward function. The models are trained using the Trajectory Balance loss to build solutions sequentially, se- lecting edges for spanning trees, nodes for paths, and cities for tours. Experiments on benchmark instances of varying sizes show that GFlowNets learn to find optimal solutions. For each problem type, multiple graph configurations with different numbers of nodes were tested. The generated solutions match those from classical algorithms (Dijkstra for shortest path, Kruskal for spanning trees, and exact solvers for TSP). Training convergence depends on problem complexity, with the number of episodes required for loss stabilization increasing as graph size grows. Once training converges, the generated solutions match known optima from classical algorithms across the tested instances. This work demonstrates that generative models can solve combinatorial optimization problems through learned policies. The main advantage of this learning-based approach is computational scalability: while classical algorithms have fixed complexity per instance, GFlowNets amortize computation through training. With sufficient computational resources, the framework could potentially scale to larger problem instances where classical exact methods become infeasible. Read More
Distribution Shift Alignment Helps LLMs Simulate Survey Response Distributionscs.AI updates on arXiv.org arXiv:2510.21977v1 Announce Type: new
Abstract: Large language models (LLMs) offer a promising way to simulate human survey responses, potentially reducing the cost of large-scale data collection. However, existing zero-shot methods suffer from prompt sensitivity and low accuracy, while conventional fine-tuning approaches mostly fit the training set distributions and struggle to produce results more accurate than the training set itself, which deviates from the original goal of using LLMs to simulate survey responses. Building on this observation, we introduce Distribution Shift Alignment (DSA), a two-stage fine-tuning method that aligns both the output distributions and the distribution shifts across different backgrounds. By learning how these distributions change rather than fitting training data, DSA can provide results substantially closer to the true distribution than the training data. Empirically, DSA consistently outperforms other methods on five public survey datasets. We further conduct a comprehensive comparison covering accuracy, robustness, and data savings. DSA reduces the required real data by 53.48-69.12%, demonstrating its effectiveness and efficiency in survey simulation.
arXiv:2510.21977v1 Announce Type: new
Abstract: Large language models (LLMs) offer a promising way to simulate human survey responses, potentially reducing the cost of large-scale data collection. However, existing zero-shot methods suffer from prompt sensitivity and low accuracy, while conventional fine-tuning approaches mostly fit the training set distributions and struggle to produce results more accurate than the training set itself, which deviates from the original goal of using LLMs to simulate survey responses. Building on this observation, we introduce Distribution Shift Alignment (DSA), a two-stage fine-tuning method that aligns both the output distributions and the distribution shifts across different backgrounds. By learning how these distributions change rather than fitting training data, DSA can provide results substantially closer to the true distribution than the training data. Empirically, DSA consistently outperforms other methods on five public survey datasets. We further conduct a comprehensive comparison covering accuracy, robustness, and data savings. DSA reduces the required real data by 53.48-69.12%, demonstrating its effectiveness and efficiency in survey simulation. Read More
Performance Trade-offs of Optimizing Small Language Models for E-Commercecs.AI updates on arXiv.org arXiv:2510.21970v1 Announce Type: new
Abstract: Large Language Models (LLMs) offer state-of-the-art performance in natural language understanding and generation tasks. However, the deployment of leading commercial models for specialized tasks, such as e-commerce, is often hindered by high computational costs, latency, and operational expenses. This paper investigates the viability of smaller, open-weight models as a resource-efficient alternative. We present a methodology for optimizing a one-billion-parameter Llama 3.2 model for multilingual e-commerce intent recognition. The model was fine-tuned using Quantized Low-Rank Adaptation (QLoRA) on a synthetically generated dataset designed to mimic real-world user queries. Subsequently, we applied post-training quantization techniques, creating GPU-optimized (GPTQ) and CPU-optimized (GGUF) versions. Our results demonstrate that the specialized 1B model achieves 99% accuracy, matching the performance of the significantly larger GPT-4.1 model. A detailed performance analysis revealed critical, hardware-dependent trade-offs: while 4-bit GPTQ reduced VRAM usage by 41%, it paradoxically slowed inference by 82% on an older GPU architecture (NVIDIA T4) due to dequantization overhead. Conversely, GGUF formats on a CPU achieved a speedup of up to 18x in inference throughput and a reduction of over 90% in RAM consumption compared to the FP16 baseline. We conclude that small, properly optimized open-weight models are not just a viable but a more suitable alternative for domain-specific applications, offering state-of-the-art accuracy at a fraction of the computational cost.
arXiv:2510.21970v1 Announce Type: new
Abstract: Large Language Models (LLMs) offer state-of-the-art performance in natural language understanding and generation tasks. However, the deployment of leading commercial models for specialized tasks, such as e-commerce, is often hindered by high computational costs, latency, and operational expenses. This paper investigates the viability of smaller, open-weight models as a resource-efficient alternative. We present a methodology for optimizing a one-billion-parameter Llama 3.2 model for multilingual e-commerce intent recognition. The model was fine-tuned using Quantized Low-Rank Adaptation (QLoRA) on a synthetically generated dataset designed to mimic real-world user queries. Subsequently, we applied post-training quantization techniques, creating GPU-optimized (GPTQ) and CPU-optimized (GGUF) versions. Our results demonstrate that the specialized 1B model achieves 99% accuracy, matching the performance of the significantly larger GPT-4.1 model. A detailed performance analysis revealed critical, hardware-dependent trade-offs: while 4-bit GPTQ reduced VRAM usage by 41%, it paradoxically slowed inference by 82% on an older GPU architecture (NVIDIA T4) due to dequantization overhead. Conversely, GGUF formats on a CPU achieved a speedup of up to 18x in inference throughput and a reduction of over 90% in RAM consumption compared to the FP16 baseline. We conclude that small, properly optimized open-weight models are not just a viable but a more suitable alternative for domain-specific applications, offering state-of-the-art accuracy at a fraction of the computational cost. Read More