
Breaking Minds, Breaking Systems: Jailbreaking Large Language Models via Human-like Psychological Manipulationcs.AI updates on arXiv.org arXiv:2512.18244v1 Announce Type: cross
Abstract: Large Language Models (LLMs) have gained considerable popularity and protected by increasingly sophisticated safety mechanisms. However, jailbreak attacks continue to pose a critical security threat by inducing models to generate policy-violating behaviors. Current paradigms focus on input-level anomalies, overlooking that the model’s internal psychometric state can be systematically manipulated. To address this, we introduce Psychological Jailbreak, a new jailbreak attack paradigm that exposes a stateful psychological attack surface in LLMs, where attackers exploit the manipulation of a model’s psychological state across interactions. Building on this insight, we propose Human-like Psychological Manipulation (HPM), a black-box jailbreak method that dynamically profiles a target model’s latent psychological vulnerabilities and synthesizes tailored multi-turn attack strategies. By leveraging the model’s optimization for anthropomorphic consistency, HPM creates a psychological pressure where social compliance overrides safety constraints. To systematically measure psychological safety, we construct an evaluation framework incorporating psychometric datasets and the Policy Corruption Score (PCS). Benchmarking against various models (e.g., GPT-4o, DeepSeek-V3, Gemini-2-Flash), HPM achieves a mean Attack Success Rate (ASR) of 88.1%, outperforming state-of-the-art attack baselines. Our experiments demonstrate robust penetration against advanced defenses, including adversarial prompt optimization (e.g., RPO) and cognitive interventions (e.g., Self-Reminder). Ultimately, PCS analysis confirms HPM induces safety breakdown to satisfy manipulated contexts. Our work advocates for a fundamental paradigm shift from static content filtering to psychological safety, prioritizing the development of psychological defense mechanisms against deep cognitive manipulation.
arXiv:2512.18244v1 Announce Type: cross
Abstract: Large Language Models (LLMs) have gained considerable popularity and protected by increasingly sophisticated safety mechanisms. However, jailbreak attacks continue to pose a critical security threat by inducing models to generate policy-violating behaviors. Current paradigms focus on input-level anomalies, overlooking that the model’s internal psychometric state can be systematically manipulated. To address this, we introduce Psychological Jailbreak, a new jailbreak attack paradigm that exposes a stateful psychological attack surface in LLMs, where attackers exploit the manipulation of a model’s psychological state across interactions. Building on this insight, we propose Human-like Psychological Manipulation (HPM), a black-box jailbreak method that dynamically profiles a target model’s latent psychological vulnerabilities and synthesizes tailored multi-turn attack strategies. By leveraging the model’s optimization for anthropomorphic consistency, HPM creates a psychological pressure where social compliance overrides safety constraints. To systematically measure psychological safety, we construct an evaluation framework incorporating psychometric datasets and the Policy Corruption Score (PCS). Benchmarking against various models (e.g., GPT-4o, DeepSeek-V3, Gemini-2-Flash), HPM achieves a mean Attack Success Rate (ASR) of 88.1%, outperforming state-of-the-art attack baselines. Our experiments demonstrate robust penetration against advanced defenses, including adversarial prompt optimization (e.g., RPO) and cognitive interventions (e.g., Self-Reminder). Ultimately, PCS analysis confirms HPM induces safety breakdown to satisfy manipulated contexts. Our work advocates for a fundamental paradigm shift from static content filtering to psychological safety, prioritizing the development of psychological defense mechanisms against deep cognitive manipulation. Read More
An Agentic Framework for Autonomous Materials Computationcs.AI updates on arXiv.org arXiv:2512.19458v1 Announce Type: new
Abstract: Large Language Models (LLMs) have emerged as powerful tools for accelerating scientific discovery, yet their static knowledge and hallucination issues hinder autonomous research applications. Recent advances integrate LLMs into agentic frameworks, enabling retrieval, reasoning, and tool use for complex scientific workflows. Here, we present a domain-specialized agent designed for reliable automation of first-principles materials computations. By embedding domain expertise, the agent ensures physically coherent multi-step workflows and consistently selects convergent, well-posed parameters, thereby enabling reliable end-to-end computational execution. A new benchmark of diverse computational tasks demonstrates that our system significantly outperforms standalone LLMs in both accuracy and robustness. This work establishes a verifiable foundation for autonomous computational experimentation and represents a key step toward fully automated scientific discovery.
arXiv:2512.19458v1 Announce Type: new
Abstract: Large Language Models (LLMs) have emerged as powerful tools for accelerating scientific discovery, yet their static knowledge and hallucination issues hinder autonomous research applications. Recent advances integrate LLMs into agentic frameworks, enabling retrieval, reasoning, and tool use for complex scientific workflows. Here, we present a domain-specialized agent designed for reliable automation of first-principles materials computations. By embedding domain expertise, the agent ensures physically coherent multi-step workflows and consistently selects convergent, well-posed parameters, thereby enabling reliable end-to-end computational execution. A new benchmark of diverse computational tasks demonstrates that our system significantly outperforms standalone LLMs in both accuracy and robustness. This work establishes a verifiable foundation for autonomous computational experimentation and represents a key step toward fully automated scientific discovery. Read More

5 Emerging Trends in Data Engineering for 2026KDnuggets Looking ahead to 2026, the most impactful trends are not flashy frameworks but structural changes in how data pipelines are designed, owned, and operated.
Looking ahead to 2026, the most impactful trends are not flashy frameworks but structural changes in how data pipelines are designed, owned, and operated. Read More
Inside China’s push to apply AI across its energy systemAI News Under China’s push to clean up its energy system, AI is starting to shape how power is produced, moved, and used — not in abstract policy terms, but in day-to-day operations. In Chifeng, a city in northern China, a renewable-powered factory offers a clear example. The site produces hydrogen and ammonia using electricity generated entirely
The post Inside China’s push to apply AI across its energy system appeared first on AI News.
Under China’s push to clean up its energy system, AI is starting to shape how power is produced, moved, and used — not in abstract policy terms, but in day-to-day operations. In Chifeng, a city in northern China, a renewable-powered factory offers a clear example. The site produces hydrogen and ammonia using electricity generated entirely
The post Inside China’s push to apply AI across its energy system appeared first on AI News. Read More
Reliable Audio Deepfake Detection in Variable Conditions via Quantum-Kernel SVMscs.AI updates on arXiv.org arXiv:2512.18797v1 Announce Type: cross
Abstract: Detecting synthetic speech is challenging when labeled data are scarce and recording conditions vary. Existing end-to-end deep models often overfit or fail to generalize, and while kernel methods can remain competitive, their performance heavily depends on the chosen kernel. Here, we show that using a quantum kernel in audio deepfake detection reduces falsepositive rates without increasing model size. Quantum feature maps embed data into high-dimensional Hilbert spaces, enabling the use of expressive similarity measures and compact classifiers. Building on this motivation, we compare quantum-kernel SVMs (QSVMs) with classical SVMs using identical mel-spectrogram preprocessing and stratified 5-fold cross-validation across four corpora (ASVspoof 2019 LA, ASVspoof 5 (2024), ADD23, and an In-the-Wild set). QSVMs achieve consistently lower equalerror rates (EER): 0.183 vs. 0.299 on ASVspoof 5 (2024), 0.081 vs. 0.188 on ADD23, 0.346 vs. 0.399 on ASVspoof 2019, and 0.355 vs. 0.413 In-the-Wild. At the EER operating point (where FPR equals FNR), these correspond to absolute false-positiverate reductions of 0.116 (38.8%), 0.107 (56.9%), 0.053 (13.3%), and 0.058 (14.0%), respectively. We also report how consistent the results are across cross-validation folds and margin-based measures of class separation, using identical settings for both models. The only modification is the kernel; the features and SVM remain unchanged, no additional trainable parameters are introduced, and the quantum kernel is computed on a conventional computer.
arXiv:2512.18797v1 Announce Type: cross
Abstract: Detecting synthetic speech is challenging when labeled data are scarce and recording conditions vary. Existing end-to-end deep models often overfit or fail to generalize, and while kernel methods can remain competitive, their performance heavily depends on the chosen kernel. Here, we show that using a quantum kernel in audio deepfake detection reduces falsepositive rates without increasing model size. Quantum feature maps embed data into high-dimensional Hilbert spaces, enabling the use of expressive similarity measures and compact classifiers. Building on this motivation, we compare quantum-kernel SVMs (QSVMs) with classical SVMs using identical mel-spectrogram preprocessing and stratified 5-fold cross-validation across four corpora (ASVspoof 2019 LA, ASVspoof 5 (2024), ADD23, and an In-the-Wild set). QSVMs achieve consistently lower equalerror rates (EER): 0.183 vs. 0.299 on ASVspoof 5 (2024), 0.081 vs. 0.188 on ADD23, 0.346 vs. 0.399 on ASVspoof 2019, and 0.355 vs. 0.413 In-the-Wild. At the EER operating point (where FPR equals FNR), these correspond to absolute false-positiverate reductions of 0.116 (38.8%), 0.107 (56.9%), 0.053 (13.3%), and 0.058 (14.0%), respectively. We also report how consistent the results are across cross-validation folds and margin-based measures of class separation, using identical settings for both models. The only modification is the kernel; the features and SVM remain unchanged, no additional trainable parameters are introduced, and the quantum kernel is computed on a conventional computer. Read More
Datasets for machine learning and for assessing the intelligence level of automatic patent search systemscs.AI updates on arXiv.org arXiv:2512.18384v1 Announce Type: cross
Abstract: The key to success in automating prior art search in patent research using artificial intelligence lies in developing large datasets for machine learning and ensuring their availability. This work is dedicated to providing a comprehensive solution to the problem of creating infrastructure for research in this field, including datasets and tools for calculating search quality criteria. The paper discusses the concept of semantic clusters of patent documents that determine the state of the art in a given subject, as proposed by the authors. A definition of such semantic clusters is also provided. Prior art search is presented as the task of identifying elements within a semantic cluster of patent documents in the subject area specified by the document under consideration. A generator of user-configurable datasets for machine learning, based on collections of U.S. and Russian patent documents, is described. The dataset generator creates a database of links to documents in semantic clusters. Then, based on user-defined parameters, it forms a dataset of semantic clusters in JSON format for machine learning. To evaluate machine learning outcomes, it is proposed to calculate search quality scores that account for semantic clusters of the documents being searched. To automate the evaluation process, the paper describes a utility developed by the authors for assessing the quality of prior art document search.
arXiv:2512.18384v1 Announce Type: cross
Abstract: The key to success in automating prior art search in patent research using artificial intelligence lies in developing large datasets for machine learning and ensuring their availability. This work is dedicated to providing a comprehensive solution to the problem of creating infrastructure for research in this field, including datasets and tools for calculating search quality criteria. The paper discusses the concept of semantic clusters of patent documents that determine the state of the art in a given subject, as proposed by the authors. A definition of such semantic clusters is also provided. Prior art search is presented as the task of identifying elements within a semantic cluster of patent documents in the subject area specified by the document under consideration. A generator of user-configurable datasets for machine learning, based on collections of U.S. and Russian patent documents, is described. The dataset generator creates a database of links to documents in semantic clusters. Then, based on user-defined parameters, it forms a dataset of semantic clusters in JSON format for machine learning. To evaluate machine learning outcomes, it is proposed to calculate search quality scores that account for semantic clusters of the documents being searched. To automate the evaluation process, the paper describes a utility developed by the authors for assessing the quality of prior art document search. Read More

Gistr: The Smart AI Notebook for Organizing KnowledgeKDnuggets This article explains how Gistr transforms the way data professionals interact with their most valuable asset: their accumulated knowledge.
This article explains how Gistr transforms the way data professionals interact with their most valuable asset: their accumulated knowledge. Read More
The Geometry of Laziness: What Angles Reveal About AI HallucinationsTowards Data Science A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science.
A story about failing forward, spheres you can’t visualize, and why sometimes the math knows things before we do
The post The Geometry of Laziness: What Angles Reveal About AI Hallucinations appeared first on Towards Data Science. Read More
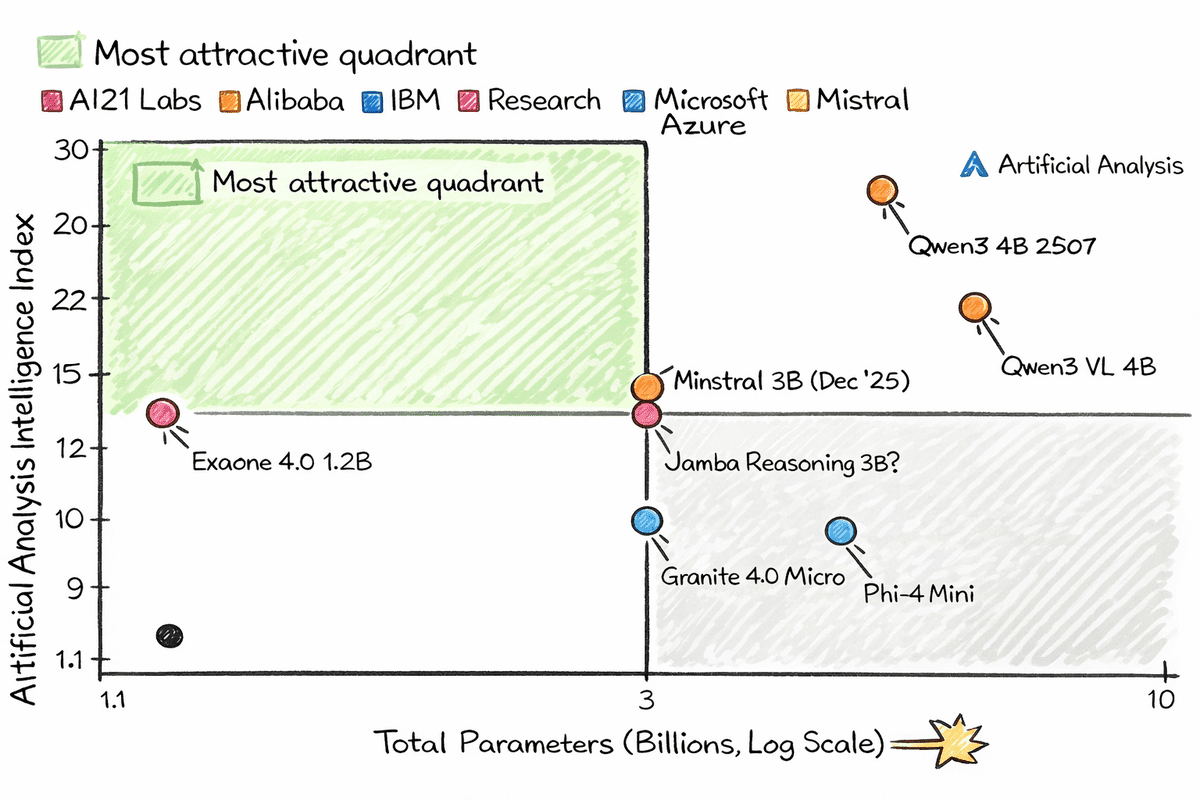
7 Tiny AI Models for Raspberry PiKDnuggets This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge.
This is a list of top LLM and VLMs that are fast, smart, and small enough to run locally on devices as small as a Raspberry Pi or even a smart fridge. Read More
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI Towards Data Science
ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AITowards Data Science For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science.
For the last couple of years, a lot of the conversation around AI has revolved around a single, deceptively simple question: Which model is the best? But the next question was always, the best for what? The best for reasoning? Writing? Coding? Or maybe it’s the best for images, audio, or video? That framing made
The post ChatLLM Presents a Streamlined Solution to Addressing the Real Bottleneck in AI appeared first on Towards Data Science. Read More