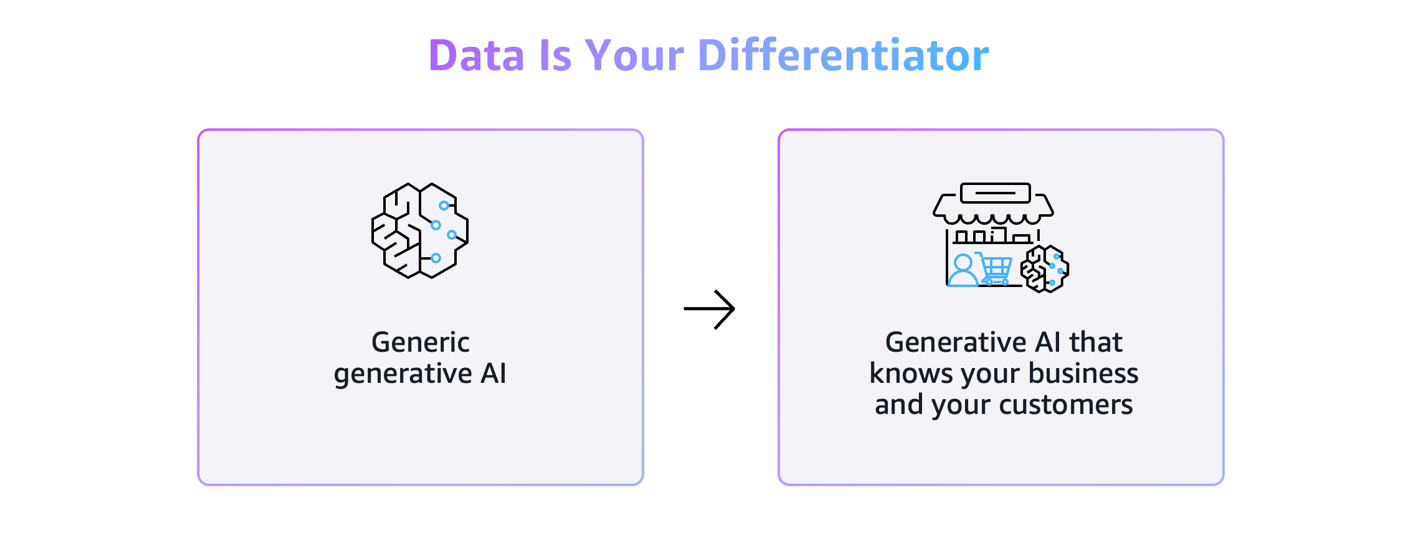
Custom Intelligence: Building AI that matches your business DNAArtificial Intelligence In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences,
In 2024, we launched the Custom Model Program within the AWS Generative AI Innovation Center to provide comprehensive support throughout every stage of model customization and optimization. Over the past two years, this program has delivered exceptional results by partnering with global enterprises and startups across diverse industries—including legal, financial services, healthcare and life sciences, Read More

RF-DETR Under the Hood: The Insights of a Real-Time Transformer DetectionTowards Data Science From rigid grids to adaptive attention, this is the evolutionary path that made detection transformers fast, flexible, and formidable.
The post RF-DETR Under the Hood: The Insights of a Real-Time Transformer Detection appeared first on Towards Data Science.
From rigid grids to adaptive attention, this is the evolutionary path that made detection transformers fast, flexible, and formidable.
The post RF-DETR Under the Hood: The Insights of a Real-Time Transformer Detection appeared first on Towards Data Science. Read More
Symbolically Scaffolded Play: Designing Role-Sensitive Prompts for Generative NPC Dialoguecs.AI updates on arXiv.org arXiv:2510.25820v1 Announce Type: new
Abstract: Large Language Models (LLMs) promise to transform interactive games by enabling non-player characters (NPCs) to sustain unscripted dialogue. Yet it remains unclear whether constrained prompts actually improve player experience. We investigate this question through The Interview, a voice-based detective game powered by GPT-4o. A within-subjects usability study ($N=10$) compared high-constraint (HCP) and low-constraint (LCP) prompts, revealing no reliable experiential differences beyond sensitivity to technical breakdowns. Guided by these findings, we redesigned the HCP into a hybrid JSON+RAG scaffold and conducted a synthetic evaluation with an LLM judge, positioned as an early-stage complement to usability testing. Results uncovered a novel pattern: scaffolding effects were role-dependent: the Interviewer (quest-giver NPC) gained stability, while suspect NPCs lost improvisational believability. These findings overturn the assumption that tighter constraints inherently enhance play. Extending fuzzy-symbolic scaffolding, we introduce textit{Symbolically Scaffolded Play}, a framework in which symbolic structures are expressed as fuzzy, numerical boundaries that stabilize coherence where needed while preserving improvisation where surprise sustains engagement.
arXiv:2510.25820v1 Announce Type: new
Abstract: Large Language Models (LLMs) promise to transform interactive games by enabling non-player characters (NPCs) to sustain unscripted dialogue. Yet it remains unclear whether constrained prompts actually improve player experience. We investigate this question through The Interview, a voice-based detective game powered by GPT-4o. A within-subjects usability study ($N=10$) compared high-constraint (HCP) and low-constraint (LCP) prompts, revealing no reliable experiential differences beyond sensitivity to technical breakdowns. Guided by these findings, we redesigned the HCP into a hybrid JSON+RAG scaffold and conducted a synthetic evaluation with an LLM judge, positioned as an early-stage complement to usability testing. Results uncovered a novel pattern: scaffolding effects were role-dependent: the Interviewer (quest-giver NPC) gained stability, while suspect NPCs lost improvisational believability. These findings overturn the assumption that tighter constraints inherently enhance play. Extending fuzzy-symbolic scaffolding, we introduce textit{Symbolically Scaffolded Play}, a framework in which symbolic structures are expressed as fuzzy, numerical boundaries that stabilize coherence where needed while preserving improvisation where surprise sustains engagement. Read More
The Machine Learning Projects Employers Want to SeeTowards Data Science What machine learning projects will actually get you interviews and jobs
The post The Machine Learning Projects Employers Want to See appeared first on Towards Data Science.
What machine learning projects will actually get you interviews and jobs
The post The Machine Learning Projects Employers Want to See appeared first on Towards Data Science. Read More
What’s In My Human Feedback? Learning Interpretable Descriptions of Preference Datacs.AI updates on arXiv.org arXiv:2510.26202v1 Announce Type: cross
Abstract: Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What’s In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data.
arXiv:2510.26202v1 Announce Type: cross
Abstract: Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What’s In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data. Read More
Bridging the Gap Between Molecule and Textual Descriptions via Substructure-aware Alignmentcs.AI updates on arXiv.org arXiv:2510.26157v1 Announce Type: cross
Abstract: Molecule and text representation learning has gained increasing interest due to its potential for enhancing the understanding of chemical information. However, existing models often struggle to capture subtle differences between molecules and their descriptions, as they lack the ability to learn fine-grained alignments between molecular substructures and chemical phrases. To address this limitation, we introduce MolBridge, a novel molecule-text learning framework based on substructure-aware alignments. Specifically, we augment the original molecule-description pairs with additional alignment signals derived from molecular substructures and chemical phrases. To effectively learn from these enriched alignments, MolBridge employs substructure-aware contrastive learning, coupled with a self-refinement mechanism that filters out noisy alignment signals. Experimental results show that MolBridge effectively captures fine-grained correspondences and outperforms state-of-the-art baselines on a wide range of molecular benchmarks, highlighting the significance of substructure-aware alignment in molecule-text learning.
arXiv:2510.26157v1 Announce Type: cross
Abstract: Molecule and text representation learning has gained increasing interest due to its potential for enhancing the understanding of chemical information. However, existing models often struggle to capture subtle differences between molecules and their descriptions, as they lack the ability to learn fine-grained alignments between molecular substructures and chemical phrases. To address this limitation, we introduce MolBridge, a novel molecule-text learning framework based on substructure-aware alignments. Specifically, we augment the original molecule-description pairs with additional alignment signals derived from molecular substructures and chemical phrases. To effectively learn from these enriched alignments, MolBridge employs substructure-aware contrastive learning, coupled with a self-refinement mechanism that filters out noisy alignment signals. Experimental results show that MolBridge effectively captures fine-grained correspondences and outperforms state-of-the-art baselines on a wide range of molecular benchmarks, highlighting the significance of substructure-aware alignment in molecule-text learning. Read More
Nirvana: A Specialized Generalist Model With Task-Aware Memory Mechanismcs.AI updates on arXiv.org arXiv:2510.26083v1 Announce Type: cross
Abstract: Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task’s requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana’s performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs’ backbone, and can also generate accurate preliminary clinical reports accordingly.
arXiv:2510.26083v1 Announce Type: cross
Abstract: Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task’s requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana’s performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs’ backbone, and can also generate accurate preliminary clinical reports accordingly. Read More
PORTool: Tool-Use LLM Training with Rewarded Treecs.AI updates on arXiv.org arXiv:2510.26020v1 Announce Type: cross
Abstract: Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps.
arXiv:2510.26020v1 Announce Type: cross
Abstract: Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps. Read More
Approximating Human Preferences Using a Multi-Judge Learned Systemcs.AI updates on arXiv.org arXiv:2510.25884v1 Announce Type: new
Abstract: Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP).
arXiv:2510.25884v1 Announce Type: new
Abstract: Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP). Read More
A General Incentives-Based Framework for Fairness in Multi-agent Resource Allocationcs.AI updates on arXiv.org arXiv:2510.26740v1 Announce Type: cross
Abstract: We introduce the General Incentives-based Framework for Fairness (GIFF), a novel approach for fair multi-agent resource allocation that infers fair decision-making from standard value functions. In resource-constrained settings, agents optimizing for efficiency often create inequitable outcomes. Our approach leverages the action-value (Q-)function to balance efficiency and fairness without requiring additional training. Specifically, our method computes a local fairness gain for each action and introduces a counterfactual advantage correction term to discourage over-allocation to already well-off agents. This approach is formalized within a centralized control setting, where an arbitrator uses the GIFF-modified Q-values to solve an allocation problem.
Empirical evaluations across diverse domains, including dynamic ridesharing, homelessness prevention, and a complex job allocation task-demonstrate that our framework consistently outperforms strong baselines and can discover far-sighted, equitable policies. The framework’s effectiveness is supported by a theoretical foundation; we prove its fairness surrogate is a principled lower bound on the true fairness improvement and that its trade-off parameter offers monotonic tuning. Our findings establish GIFF as a robust and principled framework for leveraging standard reinforcement learning components to achieve more equitable outcomes in complex multi-agent systems.
arXiv:2510.26740v1 Announce Type: cross
Abstract: We introduce the General Incentives-based Framework for Fairness (GIFF), a novel approach for fair multi-agent resource allocation that infers fair decision-making from standard value functions. In resource-constrained settings, agents optimizing for efficiency often create inequitable outcomes. Our approach leverages the action-value (Q-)function to balance efficiency and fairness without requiring additional training. Specifically, our method computes a local fairness gain for each action and introduces a counterfactual advantage correction term to discourage over-allocation to already well-off agents. This approach is formalized within a centralized control setting, where an arbitrator uses the GIFF-modified Q-values to solve an allocation problem.
Empirical evaluations across diverse domains, including dynamic ridesharing, homelessness prevention, and a complex job allocation task-demonstrate that our framework consistently outperforms strong baselines and can discover far-sighted, equitable policies. The framework’s effectiveness is supported by a theoretical foundation; we prove its fairness surrogate is a principled lower bound on the true fairness improvement and that its trade-off parameter offers monotonic tuning. Our findings establish GIFF as a robust and principled framework for leveraging standard reinforcement learning components to achieve more equitable outcomes in complex multi-agent systems. Read More