
Hugging Face Transformers in Action: Learning How To Leverage AI for NLPTowards Data Science A practical guide to Hugging Face Transformers and to how you can analyze your resumé sentiment in seconds with AI
The post Hugging Face Transformers in Action: Learning How To Leverage AI for NLP appeared first on Towards Data Science.
A practical guide to Hugging Face Transformers and to how you can analyze your resumé sentiment in seconds with AI
The post Hugging Face Transformers in Action: Learning How To Leverage AI for NLP appeared first on Towards Data Science. Read More
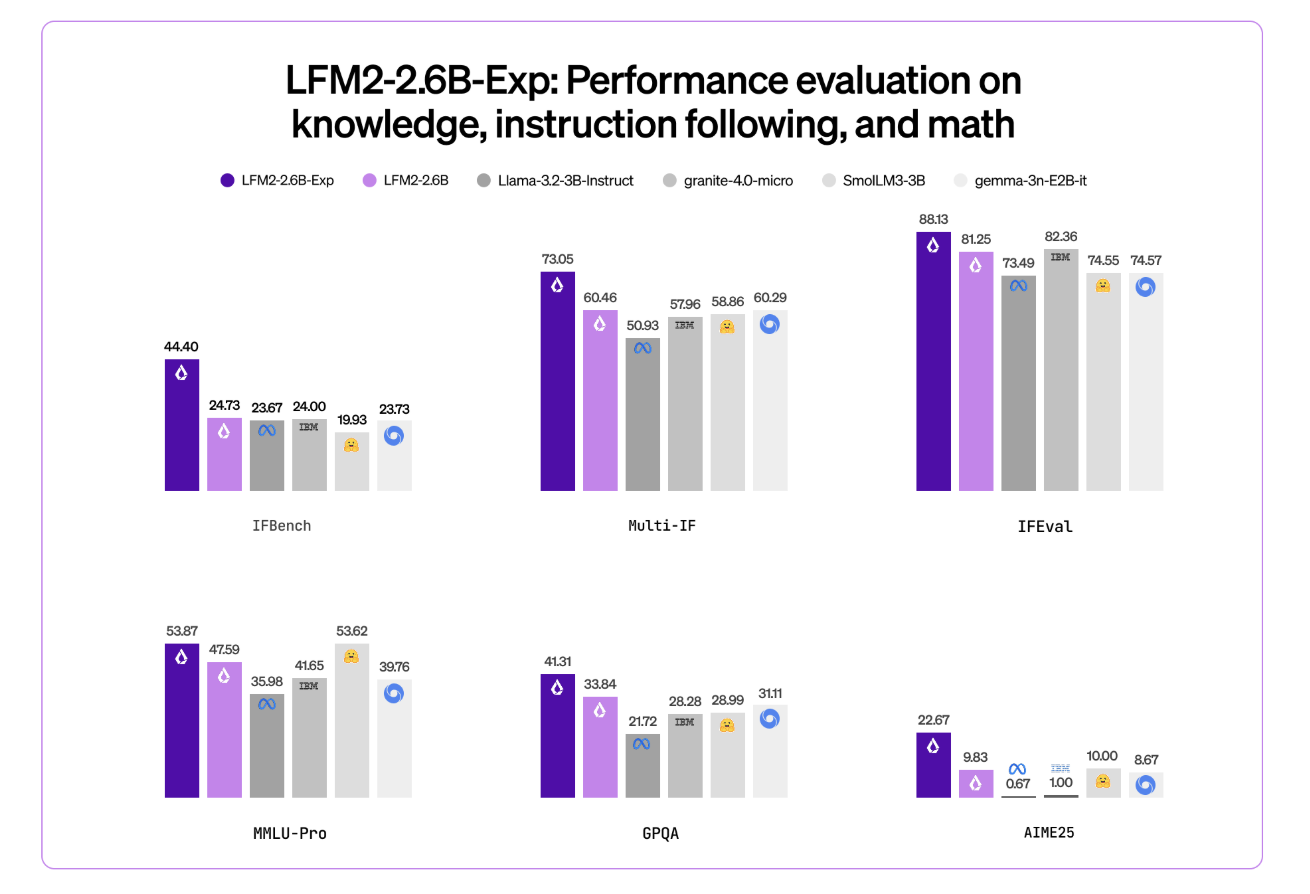
Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model BehaviorMarkTechPost Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment. Where LFM2-2.6B-Exp Fits
The post Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior appeared first on MarkTechPost.
Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment. Where LFM2-2.6B-Exp Fits
The post Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior appeared first on MarkTechPost. Read More
Breaking the Hardware Barrier: Software FP8 for Older GPUsTowards Data Science Deep learning workloads are increasingly memory-bound, with GPU cores sitting idle while waiting for data transfers. FP8 precision solves this on newer hardware, but what about the millions of RTX 30 and 20 series GPUs already deployed? Feather demonstrates that software-based FP8 emulation through bitwise packing can achieve near-theoretical 4x bandwidth improvements (3.3x measured), making efficient deep learning accessible without expensive hardware upgrades
The post Breaking the Hardware Barrier: Software FP8 for Older GPUs appeared first on Towards Data Science.
Deep learning workloads are increasingly memory-bound, with GPU cores sitting idle while waiting for data transfers. FP8 precision solves this on newer hardware, but what about the millions of RTX 30 and 20 series GPUs already deployed? Feather demonstrates that software-based FP8 emulation through bitwise packing can achieve near-theoretical 4x bandwidth improvements (3.3x measured), making efficient deep learning accessible without expensive hardware upgrades
The post Breaking the Hardware Barrier: Software FP8 for Older GPUs appeared first on Towards Data Science. Read More
Exploring TabPFN: A Foundation Model Built for Tabular DataTowards Data Science Understanding the architecture, training pipeline and implementing TabPFN in practice
The post Exploring TabPFN: A Foundation Model Built for Tabular Data appeared first on Towards Data Science.
Understanding the architecture, training pipeline and implementing TabPFN in practice
The post Exploring TabPFN: A Foundation Model Built for Tabular Data appeared first on Towards Data Science. Read More
How IntelliNode Automates Complex Workflows with Vibe AgentsTowards Data Science Many AI systems focus on isolated tasks or simple prompt engineering. This approach allowed us to build interesting applications from a single prompt, but we are starting to hit a limit. Simple prompting falls short when we tackle complex AI tasks that require multiple stages or enterprise systems that must factor in information gradually. The
The post How IntelliNode Automates Complex Workflows with Vibe Agents appeared first on Towards Data Science.
Many AI systems focus on isolated tasks or simple prompt engineering. This approach allowed us to build interesting applications from a single prompt, but we are starting to hit a limit. Simple prompting falls short when we tackle complex AI tasks that require multiple stages or enterprise systems that must factor in information gradually. The
The post How IntelliNode Automates Complex Workflows with Vibe Agents appeared first on Towards Data Science. Read More

Train a Model Faster with torch.compile and Gradient AccumulationMachineLearningMastery.com This article is divided into two parts; they are: • Using `torch.
This article is divided into two parts; they are: • Using `torch. Read More

Training a Model on Multiple GPUs with Data ParallelismMachineLearningMastery.com This article is divided into two parts; they are: • Data Parallelism • Distributed Data Parallelism If you have multiple GPUs, you can combine them to operate as a single GPU with greater memory capacity.
This article is divided into two parts; they are: • Data Parallelism • Distributed Data Parallelism If you have multiple GPUs, you can combine them to operate as a single GPU with greater memory capacity. Read More
A Coding Guide to Build an Autonomous Multi-Agent Logistics System with Route Planning, Dynamic Auctions, and Real-Time Visualization Using Graph-Based SimulationMarkTechPost In this tutorial, we build an advanced, fully autonomous logistics simulation in which multiple smart delivery trucks operate within a dynamic city-wide road network. We design the system so that each truck behaves as an agent capable of bidding on delivery orders, planning optimal routes, managing battery levels, seeking charging stations, and maximizing profit through
The post A Coding Guide to Build an Autonomous Multi-Agent Logistics System with Route Planning, Dynamic Auctions, and Real-Time Visualization Using Graph-Based Simulation appeared first on MarkTechPost.
In this tutorial, we build an advanced, fully autonomous logistics simulation in which multiple smart delivery trucks operate within a dynamic city-wide road network. We design the system so that each truck behaves as an agent capable of bidding on delivery orders, planning optimal routes, managing battery levels, seeking charging stations, and maximizing profit through
The post A Coding Guide to Build an Autonomous Multi-Agent Logistics System with Route Planning, Dynamic Auctions, and Real-Time Visualization Using Graph-Based Simulation appeared first on MarkTechPost. Read More
Agentic AI for Scaling Diagnosis and Care in Neurodegenerative Diseasecs.AI updates on arXiv.org arXiv:2502.06842v4 Announce Type: replace-cross
Abstract: United States healthcare systems are struggling to meet the growing demand for neurological care, particularly in Alzheimer’s disease and related dementias (ADRD). Generative AI built on language models (LLMs) now enables agentic AI systems that can enhance clinician capabilities to approach specialist-level assessment and decision-making in ADRD care at scale. This article presents a comprehensive six-phase roadmap for responsible design and integration of such systems into ADRD care: (1) high-quality standardized data collection across modalities; (2) decision support; (3) clinical integration enhancing workflows; (4) rigorous validation and monitoring protocols; (5) continuous learning through clinical feedback; and (6) robust ethics and risk management frameworks. This human centered approach optimizes clinicians’ capabilities in comprehensive data collection, interpretation of complex clinical information, and timely application of relevant medical knowledge while prioritizing patient safety, healthcare equity, and transparency. Though focused on ADRD, these principles offer broad applicability across medical specialties facing similar systemic challenges.
arXiv:2502.06842v4 Announce Type: replace-cross
Abstract: United States healthcare systems are struggling to meet the growing demand for neurological care, particularly in Alzheimer’s disease and related dementias (ADRD). Generative AI built on language models (LLMs) now enables agentic AI systems that can enhance clinician capabilities to approach specialist-level assessment and decision-making in ADRD care at scale. This article presents a comprehensive six-phase roadmap for responsible design and integration of such systems into ADRD care: (1) high-quality standardized data collection across modalities; (2) decision support; (3) clinical integration enhancing workflows; (4) rigorous validation and monitoring protocols; (5) continuous learning through clinical feedback; and (6) robust ethics and risk management frameworks. This human centered approach optimizes clinicians’ capabilities in comprehensive data collection, interpretation of complex clinical information, and timely application of relevant medical knowledge while prioritizing patient safety, healthcare equity, and transparency. Though focused on ADRD, these principles offer broad applicability across medical specialties facing similar systemic challenges. Read More
Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learningcs.AI updates on arXiv.org arXiv:2512.20605v2 Announce Type: replace-cross
Abstract: Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term “internal RL”, enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
arXiv:2512.20605v2 Announce Type: replace-cross
Abstract: Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term “internal RL”, enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models. Read More