
How to Keep MCPs Useful in Agentic PipelinesTowards Data Science Check the tools your LLM uses before replacing it with just a more powerful model
The post How to Keep MCPs Useful in Agentic Pipelines appeared first on Towards Data Science.
Check the tools your LLM uses before replacing it with just a more powerful model
The post How to Keep MCPs Useful in Agentic Pipelines appeared first on Towards Data Science. Read More

Author: Derrick D. JacksonTitle: Founder & Senior Director of Cloud Security Architecture & RiskCredentials: CISSP, CRISC, CCSPLast updated: January 2nd, 2026 NIST AI RMF Function Overviews: View Articles What is NIST AI RMF MAP? MAP in 60 Seconds: Before you deploy an AI system, it makes sense to understand what it does, who it affects, and […]
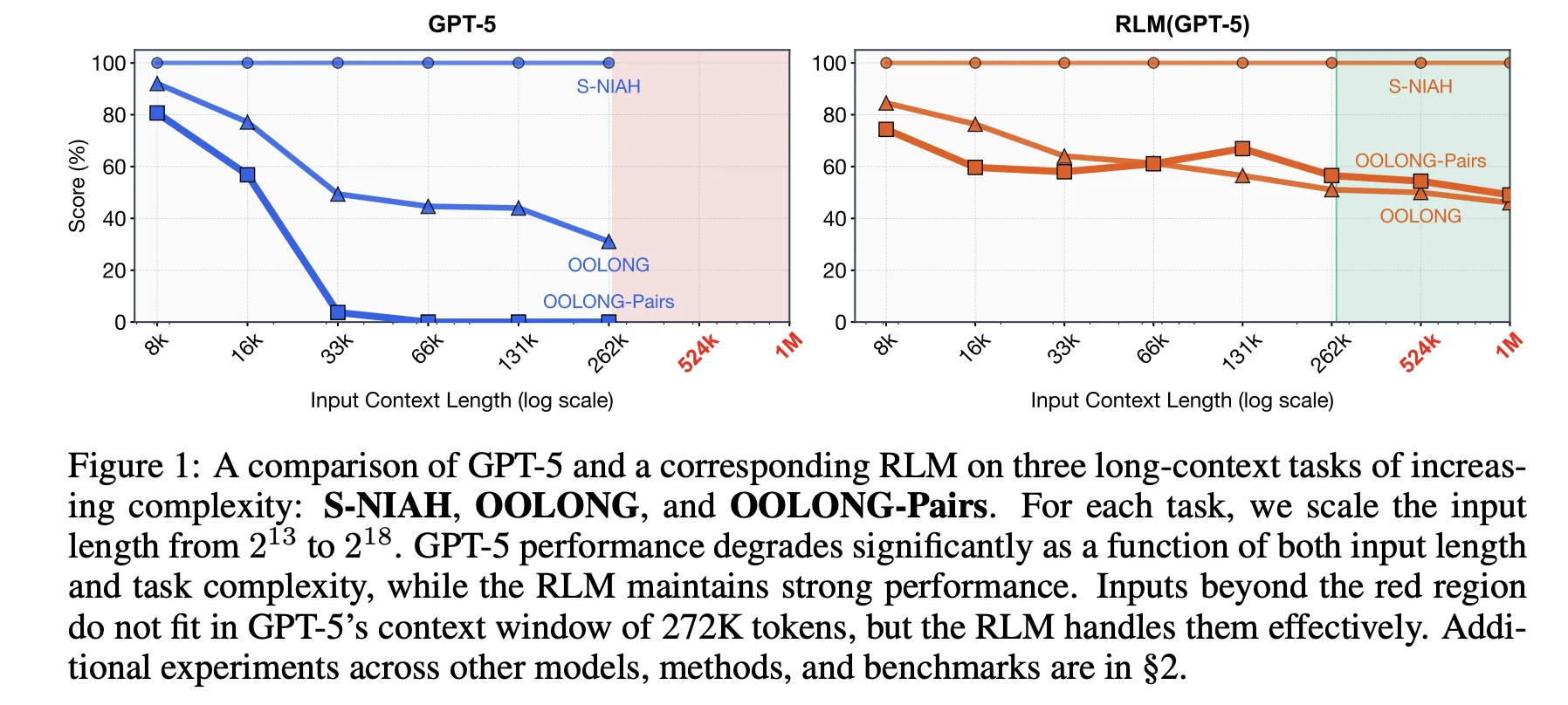
Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM AgentsMarkTechPost Recursive Language Models aim to break the usual trade off between context length, accuracy and cost in large language models. Instead of forcing a model to read a giant prompt in one pass, RLMs treat the prompt as an external environment and let the model decide how to inspect it with code, then recursively call
The post Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM Agents appeared first on MarkTechPost.
Recursive Language Models aim to break the usual trade off between context length, accuracy and cost in large language models. Instead of forcing a model to read a giant prompt in one pass, RLMs treat the prompt as an external environment and let the model decide how to inspect it with code, then recursively call
The post Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM Agents appeared first on MarkTechPost. Read More
A Coding Implementation to Build a Self-Testing Agentic AI System Using Strands to Red-Team Tool-Using Agents and Enforce Safety at RuntimeMarkTechPost In this tutorial, we build an advanced red-team evaluation harness using Strands Agents to stress-test a tool-using AI system against prompt-injection and tool-misuse attacks. We treat agent safety as a first-class engineering problem by orchestrating multiple agents that generate adversarial prompts, execute them against a guarded target agent, and judge the responses with structured evaluation
The post A Coding Implementation to Build a Self-Testing Agentic AI System Using Strands to Red-Team Tool-Using Agents and Enforce Safety at Runtime appeared first on MarkTechPost.
In this tutorial, we build an advanced red-team evaluation harness using Strands Agents to stress-test a tool-using AI system against prompt-injection and tool-misuse attacks. We treat agent safety as a first-class engineering problem by orchestrating multiple agents that generate adversarial prompts, execute them against a guarded target agent, and judge the responses with structured evaluation
The post A Coding Implementation to Build a Self-Testing Agentic AI System Using Strands to Red-Team Tool-Using Agents and Enforce Safety at Runtime appeared first on MarkTechPost. Read More
Drift Detection in Robust Machine Learning SystemsTowards Data Science A prerequisite for long-term success of machine learning systems
The post Drift Detection in Robust Machine Learning Systems appeared first on Towards Data Science.
A prerequisite for long-term success of machine learning systems
The post Drift Detection in Robust Machine Learning Systems appeared first on Towards Data Science. Read More
Understanding how AI and big data transform digital marketingAI News Artificial intelligence and big data are reshaping digital marketing by providing new insights into consumer behaviour. The technologies allow marketers to create more personalised and effective strategies. As the digital world evolves, businesses must adapt to stay competitive. Rainmaker is an AI marketing agency that uses artificial intelligence and big data to enhance digital marketing
The post Understanding how AI and big data transform digital marketing appeared first on AI News.
Artificial intelligence and big data are reshaping digital marketing by providing new insights into consumer behaviour. The technologies allow marketers to create more personalised and effective strategies. As the digital world evolves, businesses must adapt to stay competitive. Rainmaker is an AI marketing agency that uses artificial intelligence and big data to enhance digital marketing
The post Understanding how AI and big data transform digital marketing appeared first on AI News. Read More
Solana’s high-speed AI gains and malware lossesAI News Solana’s high-speed platform is fast becoming the preferred home for independent AI programmes. It comes at a time when advanced uses of technology have led to significant increases in cyberattacks. This article details the escalating malware threats for the cryptocurrency community. According to the most recent data on December 5, 2025, the Solana price on
The post Solana’s high-speed AI gains and malware losses appeared first on AI News.
Solana’s high-speed platform is fast becoming the preferred home for independent AI programmes. It comes at a time when advanced uses of technology have led to significant increases in cyberattacks. This article details the escalating malware threats for the cryptocurrency community. According to the most recent data on December 5, 2025, the Solana price on
The post Solana’s high-speed AI gains and malware losses appeared first on AI News. Read More
Announcing OpenAI Grove Cohort 2OpenAI News Applications are now open for OpenAI Grove Cohort 2, a 5-week founder program designed for individuals at any stage, from pre-idea to product. Participants receive $50K in API credits, early access to AI tools, and hands-on mentorship from the OpenAI team.
Applications are now open for OpenAI Grove Cohort 2, a 5-week founder program designed for individuals at any stage, from pre-idea to product. Participants receive $50K in API credits, early access to AI tools, and hands-on mentorship from the OpenAI team. Read More
Off-Beat Careers That Are the Future Of DataTowards Data Science The unconventional career paths you need to explore
The post Off-Beat Careers That Are the Future Of Data appeared first on Towards Data Science.
The unconventional career paths you need to explore
The post Off-Beat Careers That Are the Future Of Data appeared first on Towards Data Science. Read More
The Real Challenge in Data Storytelling: Getting Buy-In for SimplicityTowards Data Science What happens when your clear dashboard meets stakeholders who want everything on one screen
The post The Real Challenge in Data Storytelling: Getting Buy-In for Simplicity appeared first on Towards Data Science.
What happens when your clear dashboard meets stakeholders who want everything on one screen
The post The Real Challenge in Data Storytelling: Getting Buy-In for Simplicity appeared first on Towards Data Science. Read More