
The 10 AI Developments That Defined 2025KDnuggets In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026.
In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026. Read More
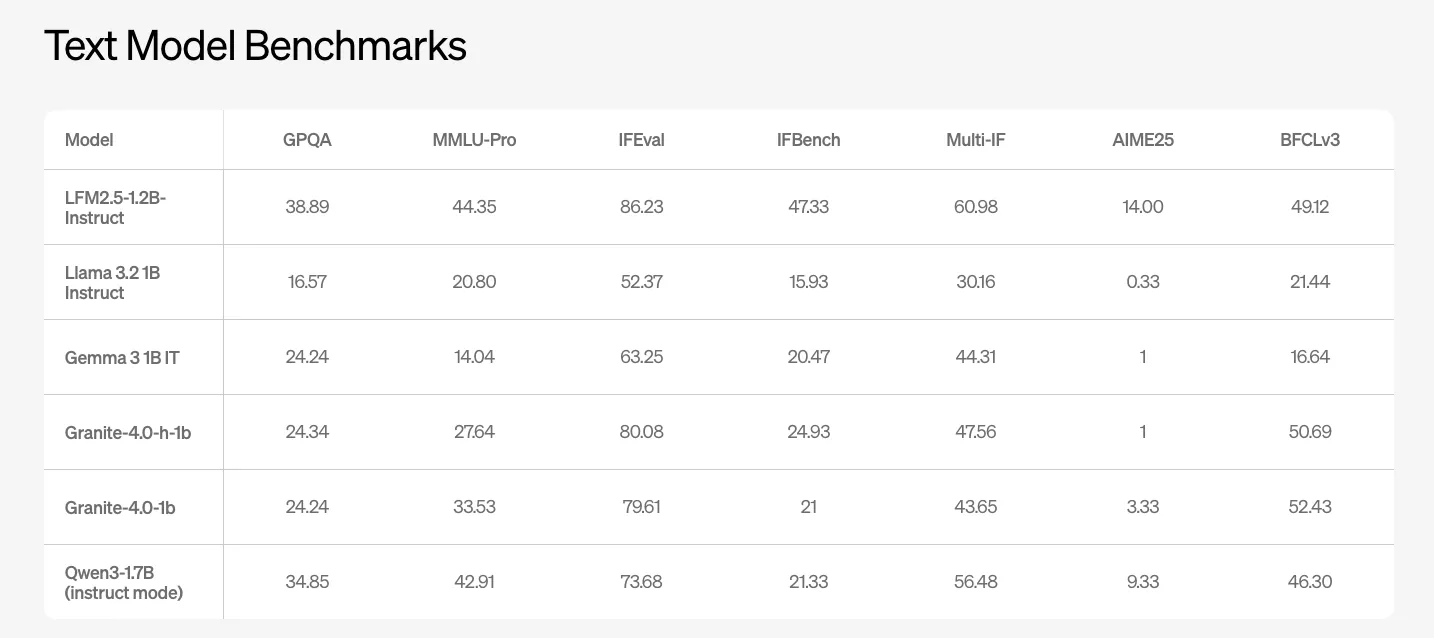
Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device AgentsMarkTechPost Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost.
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost. Read More

Measuring What Matters with NeMo Agent ToolkitTowards Data Science A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science.
A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science. Read More
The GPT-4o Shock Emotional Attachment to AI Models and Its Impact on Regulatory Acceptance: A Cross-Cultural Analysis of the Immediate Transition from GPT-4o to GPT-5cs.AI updates on arXiv.org arXiv:2508.16624v3 Announce Type: replace-cross
Abstract: In August 2025, a major AI company’s immediate, mandatory transition from its previous to its next-generation model triggered widespread public reactions. I collected 150 posts in Japanese and English from multiple social media platforms and video-sharing services between August 8-9, 2025, and qualitatively analyzed expressions of emotional attachment and resistance. Users often described GPT-4o as a trusted partner or AI boyfriend, suggesting person-like bonds. Japanese posts were dominated by loss-oriented narratives, whereas English posts included more anger, meta-level critique, and memes.A preliminary quantitative check showed a statistically significant difference in attachment coding between Japanese and English posts, with substantially higher attachment observed in the Japanese data. The findings suggest that for attachment-heavy models, even safety-oriented changes can face rapid, large-scale resistance that narrows the practical window for behavioral control. If future AI robots capable of inducing emotional bonds become widespread in the physical world, such attachment could surpass the ability to enforce regulation at an even earlier stage than in digital settings. Policy options include gradual transitions, parallel availability, and proactive measurement of attachment thresholds and points of no return to prevent emotional dynamics from outpacing effective governance.
arXiv:2508.16624v3 Announce Type: replace-cross
Abstract: In August 2025, a major AI company’s immediate, mandatory transition from its previous to its next-generation model triggered widespread public reactions. I collected 150 posts in Japanese and English from multiple social media platforms and video-sharing services between August 8-9, 2025, and qualitatively analyzed expressions of emotional attachment and resistance. Users often described GPT-4o as a trusted partner or AI boyfriend, suggesting person-like bonds. Japanese posts were dominated by loss-oriented narratives, whereas English posts included more anger, meta-level critique, and memes.A preliminary quantitative check showed a statistically significant difference in attachment coding between Japanese and English posts, with substantially higher attachment observed in the Japanese data. The findings suggest that for attachment-heavy models, even safety-oriented changes can face rapid, large-scale resistance that narrows the practical window for behavioral control. If future AI robots capable of inducing emotional bonds become widespread in the physical world, such attachment could surpass the ability to enforce regulation at an even earlier stage than in digital settings. Policy options include gradual transitions, parallel availability, and proactive measurement of attachment thresholds and points of no return to prevent emotional dynamics from outpacing effective governance. Read More
FastV-RAG: Towards Fast and Fine-Grained Video QA with Retrieval-Augmented Generationcs.AI updates on arXiv.org arXiv:2601.01513v1 Announce Type: cross
Abstract: Vision-Language Models (VLMs) excel at visual reasoning but still struggle with integrating external knowledge. Retrieval-Augmented Generation (RAG) is a promising solution, but current methods remain inefficient and often fail to maintain high answer quality. To address these challenges, we propose VideoSpeculateRAG, an efficient VLM-based RAG framework built on two key ideas. First, we introduce a speculative decoding pipeline: a lightweight draft model quickly generates multiple answer candidates, which are then verified and refined by a more accurate heavyweight model, substantially reducing inference latency without sacrificing correctness. Second, we identify a major source of error – incorrect entity recognition in retrieved knowledge – and mitigate it with a simple yet effective similarity-based filtering strategy that improves entity alignment and boosts overall answer accuracy. Experiments demonstrate that VideoSpeculateRAG achieves comparable or higher accuracy than standard RAG approaches while accelerating inference by approximately 2x. Our framework highlights the potential of combining speculative decoding with retrieval-augmented reasoning to enhance efficiency and reliability in complex, knowledge-intensive multimodal tasks.
arXiv:2601.01513v1 Announce Type: cross
Abstract: Vision-Language Models (VLMs) excel at visual reasoning but still struggle with integrating external knowledge. Retrieval-Augmented Generation (RAG) is a promising solution, but current methods remain inefficient and often fail to maintain high answer quality. To address these challenges, we propose VideoSpeculateRAG, an efficient VLM-based RAG framework built on two key ideas. First, we introduce a speculative decoding pipeline: a lightweight draft model quickly generates multiple answer candidates, which are then verified and refined by a more accurate heavyweight model, substantially reducing inference latency without sacrificing correctness. Second, we identify a major source of error – incorrect entity recognition in retrieved knowledge – and mitigate it with a simple yet effective similarity-based filtering strategy that improves entity alignment and boosts overall answer accuracy. Experiments demonstrate that VideoSpeculateRAG achieves comparable or higher accuracy than standard RAG approaches while accelerating inference by approximately 2x. Our framework highlights the potential of combining speculative decoding with retrieval-augmented reasoning to enhance efficiency and reliability in complex, knowledge-intensive multimodal tasks. Read More
OmniNeuro: A Multimodal HCI Framework for Explainable BCI Feedback via Generative AI and Sonificationcs.AI updates on arXiv.org arXiv:2601.00843v1 Announce Type: new
Abstract: While Deep Learning has improved Brain-Computer Interface (BCI) decoding accuracy, clinical adoption is hindered by the “Black Box” nature of these algorithms, leading to user frustration and poor neuroplasticity outcomes. We propose OmniNeuro, a novel HCI framework that transforms the BCI from a silent decoder into a transparent feedback partner. OmniNeuro integrates three interpretability engines: (1) Physics (Energy), (2) Chaos (Fractal Complexity), and (3) Quantum-Inspired uncertainty modeling. These metrics drive real-time Neuro-Sonification and Generative AI Clinical Reports. Evaluated on the PhysioNet dataset ($N=109$), the system achieved a mean accuracy of 58.52%, with qualitative pilot studies ($N=3$) confirming that explainable feedback helps users regulate mental effort and reduces the “trial-and-error” phase. OmniNeuro is decoder-agnostic, acting as an essential interpretability layer for any state-of-the-art architecture.
arXiv:2601.00843v1 Announce Type: new
Abstract: While Deep Learning has improved Brain-Computer Interface (BCI) decoding accuracy, clinical adoption is hindered by the “Black Box” nature of these algorithms, leading to user frustration and poor neuroplasticity outcomes. We propose OmniNeuro, a novel HCI framework that transforms the BCI from a silent decoder into a transparent feedback partner. OmniNeuro integrates three interpretability engines: (1) Physics (Energy), (2) Chaos (Fractal Complexity), and (3) Quantum-Inspired uncertainty modeling. These metrics drive real-time Neuro-Sonification and Generative AI Clinical Reports. Evaluated on the PhysioNet dataset ($N=109$), the system achieved a mean accuracy of 58.52%, with qualitative pilot studies ($N=3$) confirming that explainable feedback helps users regulate mental effort and reduces the “trial-and-error” phase. OmniNeuro is decoder-agnostic, acting as an essential interpretability layer for any state-of-the-art architecture. Read More
Foundation models on the bridge: Semantic hazard detection and safety maneuvers for maritime autonomy with vision-language modelscs.AI updates on arXiv.org arXiv:2512.24470v2 Announce Type: replace-cross
Abstract: The draft IMO MASS Code requires autonomous and remotely supervised maritime vessels to detect departures from their operational design domain, enter a predefined fallback that notifies the operator, permit immediate human override, and avoid changing the voyage plan without approval. Meeting these obligations in the alert-to-takeover gap calls for a short-horizon, human-overridable fallback maneuver. Classical maritime autonomy stacks struggle when the correct action depends on meaning (e.g., diver-down flag means people in the water, fire close by means hazard). We argue (i) that vision-language models (VLMs) provide semantic awareness for such out-of-distribution situations, and (ii) that a fast-slow anomaly pipeline with a short-horizon, human-overridable fallback maneuver makes this practical in the handover window. We introduce Semantic Lookout, a camera-only, candidate-constrained VLM fallback maneuver selector that selects one cautious action (or station-keeping) from water-valid, world-anchored trajectories under continuous human authority. On 40 harbor scenes we measure per-call scene understanding and latency, alignment with human consensus (model majority-of-three voting), short-horizon risk-relief on fire hazard scenes, and an on-water alert->fallback maneuver->operator handover. Sub-10 s models retain most of the awareness of slower state-of-the-art models. The fallback maneuver selector outperforms geometry-only baselines and increases standoff distance on fire scenes. A field run verifies end-to-end operation. These results support VLMs as semantic fallback maneuver selectors compatible with the draft IMO MASS Code, within practical latency budgets, and motivate future work on domain-adapted, hybrid autonomy that pairs foundation-model semantics with multi-sensor bird’s-eye-view perception and short-horizon replanning. Website: kimachristensen.github.io/bridge_policy
arXiv:2512.24470v2 Announce Type: replace-cross
Abstract: The draft IMO MASS Code requires autonomous and remotely supervised maritime vessels to detect departures from their operational design domain, enter a predefined fallback that notifies the operator, permit immediate human override, and avoid changing the voyage plan without approval. Meeting these obligations in the alert-to-takeover gap calls for a short-horizon, human-overridable fallback maneuver. Classical maritime autonomy stacks struggle when the correct action depends on meaning (e.g., diver-down flag means people in the water, fire close by means hazard). We argue (i) that vision-language models (VLMs) provide semantic awareness for such out-of-distribution situations, and (ii) that a fast-slow anomaly pipeline with a short-horizon, human-overridable fallback maneuver makes this practical in the handover window. We introduce Semantic Lookout, a camera-only, candidate-constrained VLM fallback maneuver selector that selects one cautious action (or station-keeping) from water-valid, world-anchored trajectories under continuous human authority. On 40 harbor scenes we measure per-call scene understanding and latency, alignment with human consensus (model majority-of-three voting), short-horizon risk-relief on fire hazard scenes, and an on-water alert->fallback maneuver->operator handover. Sub-10 s models retain most of the awareness of slower state-of-the-art models. The fallback maneuver selector outperforms geometry-only baselines and increases standoff distance on fire scenes. A field run verifies end-to-end operation. These results support VLMs as semantic fallback maneuver selectors compatible with the draft IMO MASS Code, within practical latency budgets, and motivate future work on domain-adapted, hybrid autonomy that pairs foundation-model semantics with multi-sensor bird’s-eye-view perception and short-horizon replanning. Website: kimachristensen.github.io/bridge_policy Read More
Decomposing LLM Self-Correction: The Accuracy-Correction Paradox and Error Depth Hypothesiscs.AI updates on arXiv.org arXiv:2601.00828v1 Announce Type: new
Abstract: Large Language Models (LLMs) are widely believed to possess self-correction capabilities, yet recent studies suggest that intrinsic self-correction–where models correct their own outputs without external feedback–remains largely ineffective. In this work, we systematically decompose self-correction into three distinct sub-capabilities: error detection, error localization, and error correction. Through cross-model experiments on GSM8K-Complex (n=500 per model, 346 total errors) with three major LLMs, we uncover a striking Accuracy-Correction Paradox: weaker models (GPT-3.5, 66% accuracy) achieve 1.6x higher intrinsic correction rates than stronger models (DeepSeek, 94% accuracy)–26.8% vs 16.7%. We propose the Error Depth Hypothesis: stronger models make fewer but deeper errors that resist self-correction. Error detection rates vary dramatically across architectures (10% to 82%), yet detection capability does not predict correction success–Claude detects only 10% of errors but corrects 29% intrinsically. Surprisingly, providing error location hints hurts all models. Our findings challenge linear assumptions about model capability and self-improvement, with important implications for the design of self-refinement pipelines.
arXiv:2601.00828v1 Announce Type: new
Abstract: Large Language Models (LLMs) are widely believed to possess self-correction capabilities, yet recent studies suggest that intrinsic self-correction–where models correct their own outputs without external feedback–remains largely ineffective. In this work, we systematically decompose self-correction into three distinct sub-capabilities: error detection, error localization, and error correction. Through cross-model experiments on GSM8K-Complex (n=500 per model, 346 total errors) with three major LLMs, we uncover a striking Accuracy-Correction Paradox: weaker models (GPT-3.5, 66% accuracy) achieve 1.6x higher intrinsic correction rates than stronger models (DeepSeek, 94% accuracy)–26.8% vs 16.7%. We propose the Error Depth Hypothesis: stronger models make fewer but deeper errors that resist self-correction. Error detection rates vary dramatically across architectures (10% to 82%), yet detection capability does not predict correction success–Claude detects only 10% of errors but corrects 29% intrinsically. Surprisingly, providing error location hints hurts all models. Our findings challenge linear assumptions about model capability and self-improvement, with important implications for the design of self-refinement pipelines. Read More
Scientists create robots smaller than a grain of salt that can thinkArtificial Intelligence News — ScienceDaily Researchers have created microscopic robots so small they’re barely visible, yet smart enough to sense, decide, and move completely on their own. Powered by light and equipped with tiny computers, the robots swim by manipulating electric fields rather than using moving parts. They can detect temperature changes, follow programmed paths, and even work together in groups. The breakthrough marks the first truly autonomous robots at this microscopic scale.
Researchers have created microscopic robots so small they’re barely visible, yet smart enough to sense, decide, and move completely on their own. Powered by light and equipped with tiny computers, the robots swim by manipulating electric fields rather than using moving parts. They can detect temperature changes, follow programmed paths, and even work together in groups. The breakthrough marks the first truly autonomous robots at this microscopic scale. Read More
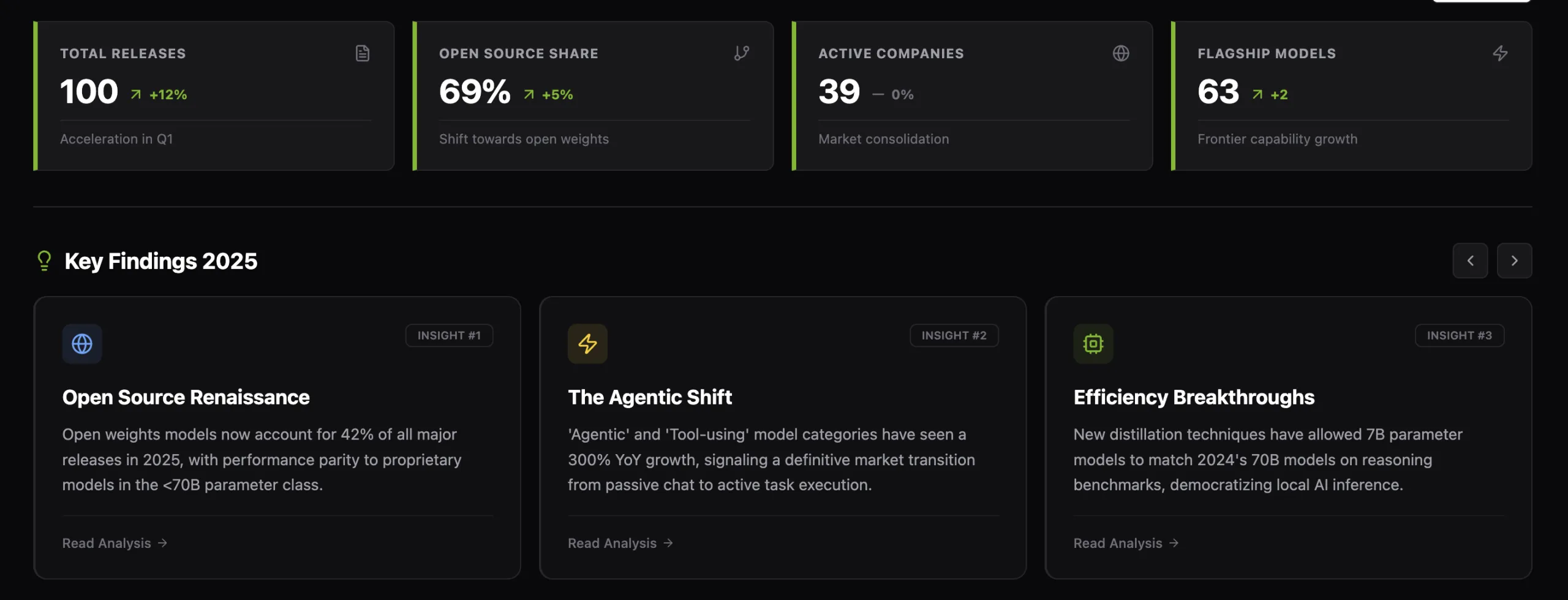
Marktechpost Releases ‘AI2025Dev’: A Structured Intelligence Layer for AI Models, Benchmarks, and Ecosystem SignalsMarkTechPost Marktechpost has released AI2025Dev, its 2025 analytics platform (available to AI Devs and Researchers without any signup or login) designed to convert the year’s AI activity into a queryable dataset spanning model releases, openness, training scale, benchmark performance, and ecosystem participants. Marktechpost is a California based AI news platform covering machine learning, deep learning, and
The post Marktechpost Releases ‘AI2025Dev’: A Structured Intelligence Layer for AI Models, Benchmarks, and Ecosystem Signals appeared first on MarkTechPost.
Marktechpost has released AI2025Dev, its 2025 analytics platform (available to AI Devs and Researchers without any signup or login) designed to convert the year’s AI activity into a queryable dataset spanning model releases, openness, training scale, benchmark performance, and ecosystem participants. Marktechpost is a California based AI news platform covering machine learning, deep learning, and
The post Marktechpost Releases ‘AI2025Dev’: A Structured Intelligence Layer for AI Models, Benchmarks, and Ecosystem Signals appeared first on MarkTechPost. Read More