
HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database GrowsTowards Data Science How approximate vector search silently degrades Recall—and what to do about It
The post HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database Grows appeared first on Towards Data Science.
How approximate vector search silently degrades Recall—and what to do about It
The post HNSW at Scale: Why Your RAG System Gets Worse as the Vector Database Grows appeared first on Towards Data Science. Read More

Optimism for AI-powered productivity: DeloitteAI News Deloitte’s latest UK CFO Survey presents an improving outlook for large UK businesses, with technology investment – particularly in AI – emerging as a dominant strategy. The survey offers the signal that while macroeconomic and geopolitical risks remain elevated, boards are converging increasingly on digital ability as a primary route to productivity and medium-term growth.
The post Optimism for AI-powered productivity: Deloitte appeared first on AI News.
Deloitte’s latest UK CFO Survey presents an improving outlook for large UK businesses, with technology investment – particularly in AI – emerging as a dominant strategy. The survey offers the signal that while macroeconomic and geopolitical risks remain elevated, boards are converging increasingly on digital ability as a primary route to productivity and medium-term growth.
The post Optimism for AI-powered productivity: Deloitte appeared first on AI News. Read More

Data Scientist vs AI Engineer: Which Career Should You Choose in 2026?KDnuggets Although data science and AI engineering share tools and terminology, they are not interchangeable careers. This article explains how the work, goals, and impact of each role differ so you can choose the career path that fits you.
Although data science and AI engineering share tools and terminology, they are not interchangeable careers. This article explains how the work, goals, and impact of each role differ so you can choose the career path that fits you. Read More
Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted OptionsTowards Data Science Human-guided AI collaboration
The post Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted Options appeared first on Towards Data Science.
Human-guided AI collaboration
The post Probabilistic Multi-Variant Reasoning: Turning Fluent LLM Answers Into Weighted Options appeared first on Towards Data Science. Read More
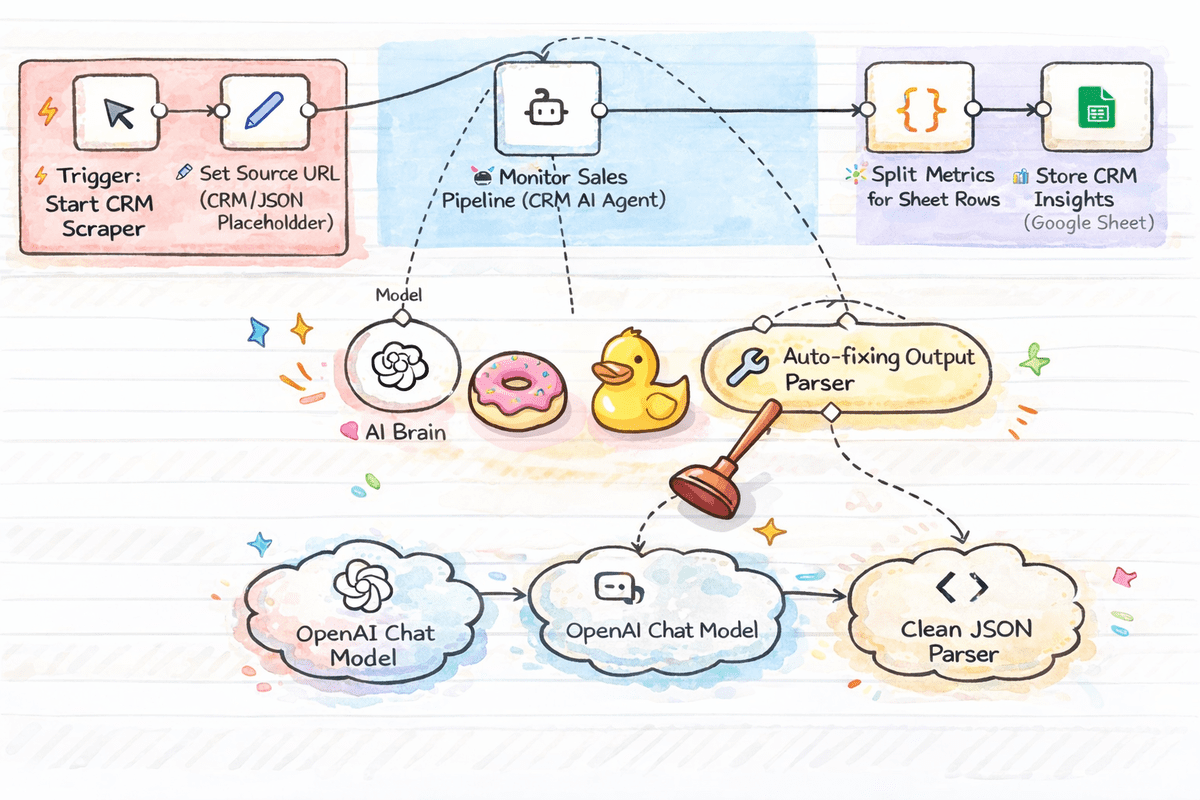
Top 7 n8n Workflow Templates for Data ScienceKDnuggets A list of ready to use n8n workflow templates that help data scientists quickly analyze data, extract and transform it, and build reliable knowledge bases.
A list of ready to use n8n workflow templates that help data scientists quickly analyze data, extract and transform it, and build reliable knowledge bases. Read More
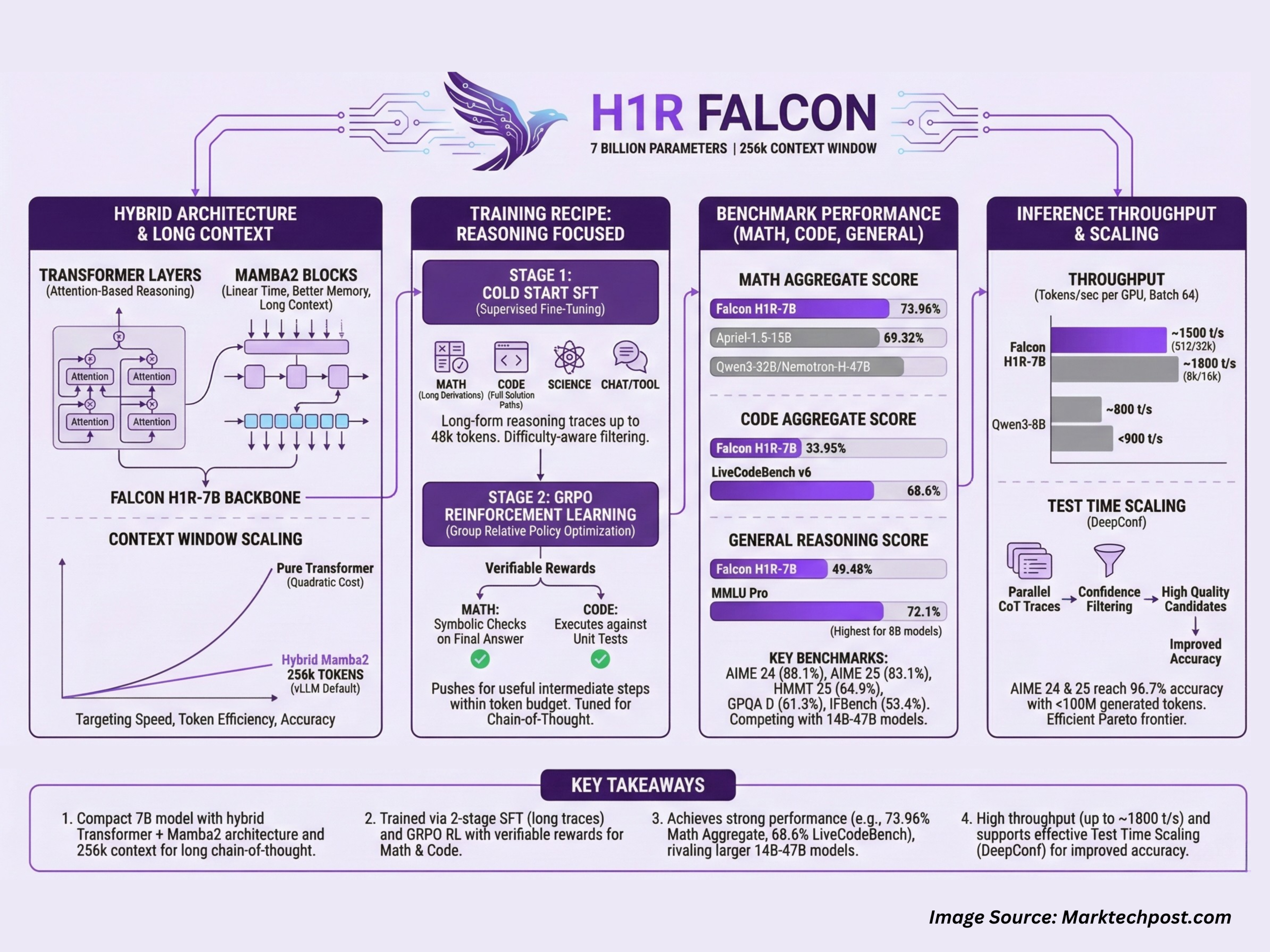
TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context WindowMarkTechPost Technology Innovation Institute (TII), Abu Dhabi, has released Falcon-H1R-7B, a 7B parameter reasoning specialized model that matches or exceeds many 14B to 47B reasoning models in math, code and general benchmarks, while staying compact and efficient. It builds on Falcon H1 7B Base and is available on Hugging Face under the Falcon-H1R collection. Falcon-H1R-7B is
The post TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window appeared first on MarkTechPost.
Technology Innovation Institute (TII), Abu Dhabi, has released Falcon-H1R-7B, a 7B parameter reasoning specialized model that matches or exceeds many 14B to 47B reasoning models in math, code and general benchmarks, while staying compact and efficient. It builds on Falcon H1 7B Base and is available on Hugging Face under the Falcon-H1R collection. Falcon-H1R-7B is
The post TII Abu-Dhabi Released Falcon H1R-7B: A New Reasoning Model Outperforming Others in Math and Coding with only 7B Params with 256k Context Window appeared first on MarkTechPost. Read More
Why Supply Chain is the Best Domain for Data Scientists in 2026 (And How to Learn It)Towards Data Science My take after 10 years in Supply Chain on why this can be an excellent playground for data scientists who want to see their skills valued.
The post Why Supply Chain is the Best Domain for Data Scientists in 2026 (And How to Learn It) appeared first on Towards Data Science.
My take after 10 years in Supply Chain on why this can be an excellent playground for data scientists who want to see their skills valued.
The post Why Supply Chain is the Best Domain for Data Scientists in 2026 (And How to Learn It) appeared first on Towards Data Science. Read More
Multimodal Fact-Checking: An Agent-based Approachcs.AI updates on arXiv.org arXiv:2512.22933v3 Announce Type: replace
Abstract: The rapid spread of multimodal misinformation poses a growing challenge for automated fact-checking systems. Existing approaches, including large vision language models (LVLMs) and deep multimodal fusion methods, often fall short due to limited reasoning and shallow evidence utilization. A key bottleneck is the lack of dedicated datasets that provide complete real-world multimodal misinformation instances accompanied by annotated reasoning processes and verifiable evidence. To address this limitation, we introduce RW-Post, a high-quality and explainable dataset for real-world multimodal fact-checking. RW-Post aligns real-world multimodal claims with their original social media posts, preserving the rich contextual information in which the claims are made. In addition, the dataset includes detailed reasoning and explicitly linked evidence, which are derived from human written fact-checking articles via a large language model assisted extraction pipeline, enabling comprehensive verification and explanation. Building upon RW-Post, we propose AgentFact, an agent-based multimodal fact-checking framework designed to emulate the human verification workflow. AgentFact consists of five specialized agents that collaboratively handle key fact-checking subtasks, including strategy planning, high-quality evidence retrieval, visual analysis, reasoning, and explanation generation. These agents are orchestrated through an iterative workflow that alternates between evidence searching and task-aware evidence filtering and reasoning, facilitating strategic decision-making and systematic evidence analysis. Extensive experimental results demonstrate that the synergy between RW-Post and AgentFact substantially improves both the accuracy and interpretability of multimodal fact-checking.
arXiv:2512.22933v3 Announce Type: replace
Abstract: The rapid spread of multimodal misinformation poses a growing challenge for automated fact-checking systems. Existing approaches, including large vision language models (LVLMs) and deep multimodal fusion methods, often fall short due to limited reasoning and shallow evidence utilization. A key bottleneck is the lack of dedicated datasets that provide complete real-world multimodal misinformation instances accompanied by annotated reasoning processes and verifiable evidence. To address this limitation, we introduce RW-Post, a high-quality and explainable dataset for real-world multimodal fact-checking. RW-Post aligns real-world multimodal claims with their original social media posts, preserving the rich contextual information in which the claims are made. In addition, the dataset includes detailed reasoning and explicitly linked evidence, which are derived from human written fact-checking articles via a large language model assisted extraction pipeline, enabling comprehensive verification and explanation. Building upon RW-Post, we propose AgentFact, an agent-based multimodal fact-checking framework designed to emulate the human verification workflow. AgentFact consists of five specialized agents that collaboratively handle key fact-checking subtasks, including strategy planning, high-quality evidence retrieval, visual analysis, reasoning, and explanation generation. These agents are orchestrated through an iterative workflow that alternates between evidence searching and task-aware evidence filtering and reasoning, facilitating strategic decision-making and systematic evidence analysis. Extensive experimental results demonstrate that the synergy between RW-Post and AgentFact substantially improves both the accuracy and interpretability of multimodal fact-checking. Read More
On the Representation of Pairwise Causal Background Knowledge and Its Applications in Causal Inferencecs.AI updates on arXiv.org arXiv:2207.05067v2 Announce Type: replace
Abstract: Pairwise causal background knowledge about the existence or absence of causal edges and paths is frequently encountered in observational studies. Such constraints allow the shared directed and undirected edges in the constrained subclass of Markov equivalent DAGs to be represented as a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and introduce a minimal representation of a causal MPDAG. Then, we give a unified representation for three types of pairwise causal background knowledge, including direct, ancestral and non-ancestral causal knowledge, by introducing a novel concept called direct causal clause (DCC). Using DCCs, we study the consistency and equivalence of pairwise causal background knowledge and show that any pairwise causal background knowledge set can be uniquely and equivalently decomposed into the causal MPDAG representing the refined Markov equivalence class and a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking consistency and equivalence, as well as for finding the decomposed MPDAG and the residual DCCs. Finally, with pairwise causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that pairwise causal background knowledge can significantly improve the identifiability of causal effects.
arXiv:2207.05067v2 Announce Type: replace
Abstract: Pairwise causal background knowledge about the existence or absence of causal edges and paths is frequently encountered in observational studies. Such constraints allow the shared directed and undirected edges in the constrained subclass of Markov equivalent DAGs to be represented as a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and introduce a minimal representation of a causal MPDAG. Then, we give a unified representation for three types of pairwise causal background knowledge, including direct, ancestral and non-ancestral causal knowledge, by introducing a novel concept called direct causal clause (DCC). Using DCCs, we study the consistency and equivalence of pairwise causal background knowledge and show that any pairwise causal background knowledge set can be uniquely and equivalently decomposed into the causal MPDAG representing the refined Markov equivalence class and a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking consistency and equivalence, as well as for finding the decomposed MPDAG and the residual DCCs. Finally, with pairwise causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that pairwise causal background knowledge can significantly improve the identifiability of causal effects. Read More
A data-driven framework for team selection in Fantasy Premier Leaguecs.AI updates on arXiv.org arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy.
arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy. Read More