
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thoughtcs.AI updates on arXiv.org arXiv:2601.08108v1 Announce Type: cross
Abstract: Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
arXiv:2601.08108v1 Announce Type: cross
Abstract: Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency. Read More
Enhancing Large Language Models for Time-Series Forecasting via Vector-Injected In-Context Learningcs.AI updates on arXiv.org arXiv:2601.07903v2 Announce Type: cross
Abstract: The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach.
arXiv:2601.07903v2 Announce Type: cross
Abstract: The World Wide Web needs reliable predictive capabilities to respond to changes in user behavior and usage patterns. Time series forecasting (TSF) is a key means to achieve this goal. In recent years, the large language models (LLMs) for TSF (LLM4TSF) have achieved good performance. However, there is a significant difference between pretraining corpora and time series data, making it hard to guarantee forecasting quality when directly applying LLMs to TSF; fine-tuning LLMs can mitigate this issue, but often incurs substantial computational overhead. Thus, LLM4TSF faces a dual challenge of prediction performance and compute overhead. To address this, we aim to explore a method for improving the forecasting performance of LLM4TSF while freezing all LLM parameters to reduce computational overhead. Inspired by in-context learning (ICL), we propose LVICL. LVICL uses our vector-injected ICL to inject example information into a frozen LLM, eliciting its in-context learning ability and thereby enhancing its performance on the example-related task (i.e., TSF). Specifically, we first use the LLM together with a learnable context vector adapter to extract a context vector from multiple examples adaptively. This vector contains compressed, example-related information. Subsequently, during the forward pass, we inject this vector into every layer of the LLM to improve forecasting performance. Compared with conventional ICL that adds examples into the prompt, our vector-injected ICL does not increase prompt length; moreover, adaptively deriving a context vector from examples suppresses components harmful to forecasting, thereby improving model performance. Extensive experiments demonstrate the effectiveness of our approach. Read More
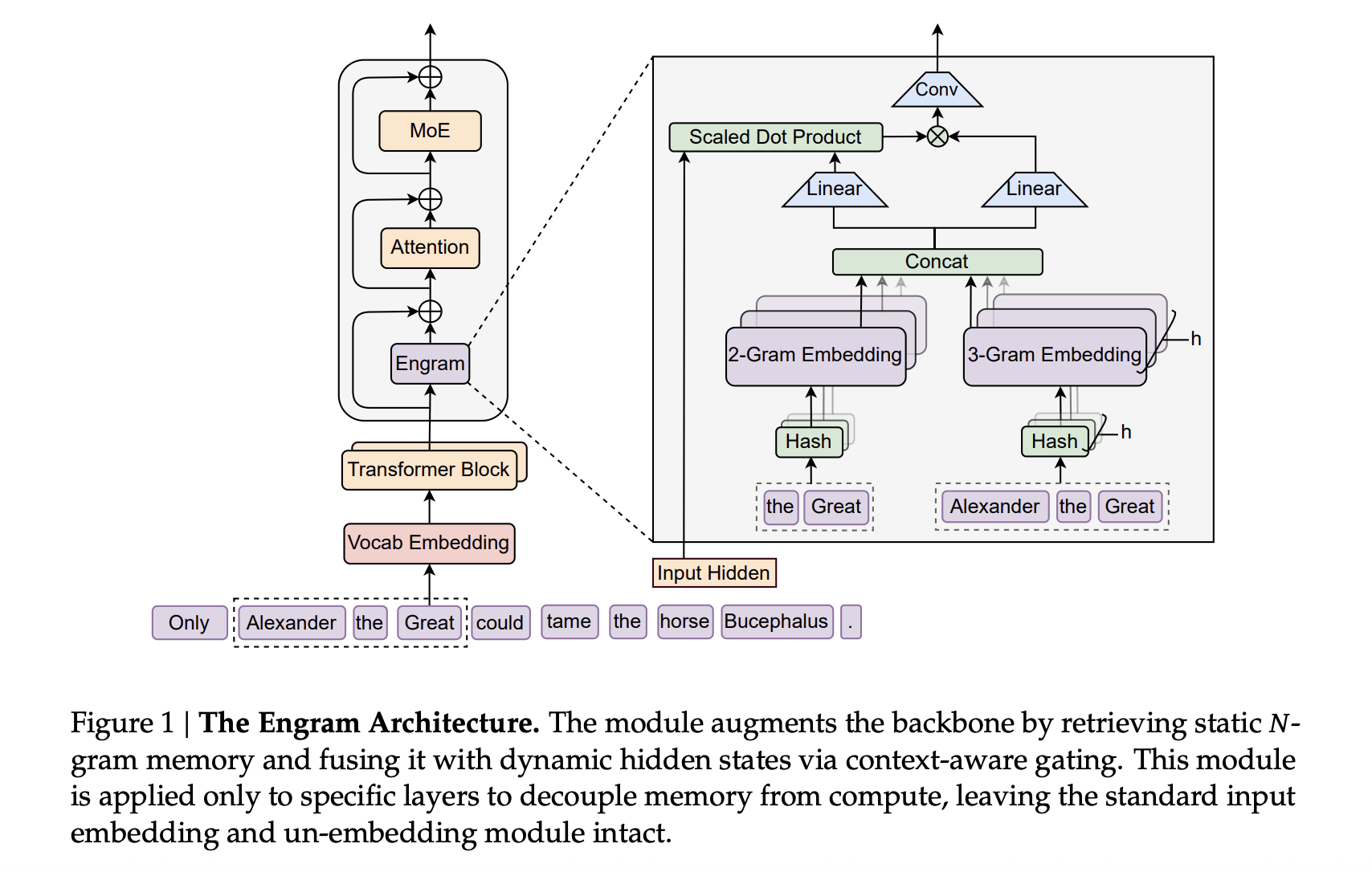
DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMsMarkTechPost Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost.
Transformers use attention and Mixture-of-Experts to scale computation, but they still lack a native way to perform knowledge lookup. They re-compute the same local patterns again and again, which wastes depth and FLOPs. DeepSeek’s new Engram module targets exactly this gap by adding a conditional memory axis that works alongside MoE rather than replacing it.
The post DeepSeek AI Researchers Introduce Engram: A Conditional Memory Axis For Sparse LLMs appeared first on MarkTechPost. Read More

Transform AI development with new Amazon SageMaker AI model customization and large-scale training capabilitiesArtificial Intelligence This post explores how new serverless model customization capabilities, elastic training, checkpointless training, and serverless MLflow work together to accelerate your AI development from months to days.
This post explores how new serverless model customization capabilities, elastic training, checkpointless training, and serverless MLflow work together to accelerate your AI development from months to days. Read More
How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent WorkflowsMarkTechPost In this tutorial, we build a clean, advanced demonstration of modern MCP design by focusing on three core ideas: stateless communication, strict SDK-level validation, and asynchronous, long-running operations. We implement a minimal MCP-like protocol using structured envelopes, signed requests, and Pydantic-validated tools to show how agents and services can interact safely without relying on persistent
The post How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent Workflows appeared first on MarkTechPost.
In this tutorial, we build a clean, advanced demonstration of modern MCP design by focusing on three core ideas: stateless communication, strict SDK-level validation, and asynchronous, long-running operations. We implement a minimal MCP-like protocol using structured envelopes, signed requests, and Pydantic-validated tools to show how agents and services can interact safely without relying on persistent
The post How to Build a Stateless, Secure, and Asynchronous MCP-Style Protocol for Scalable Agent Workflows appeared first on MarkTechPost. Read More
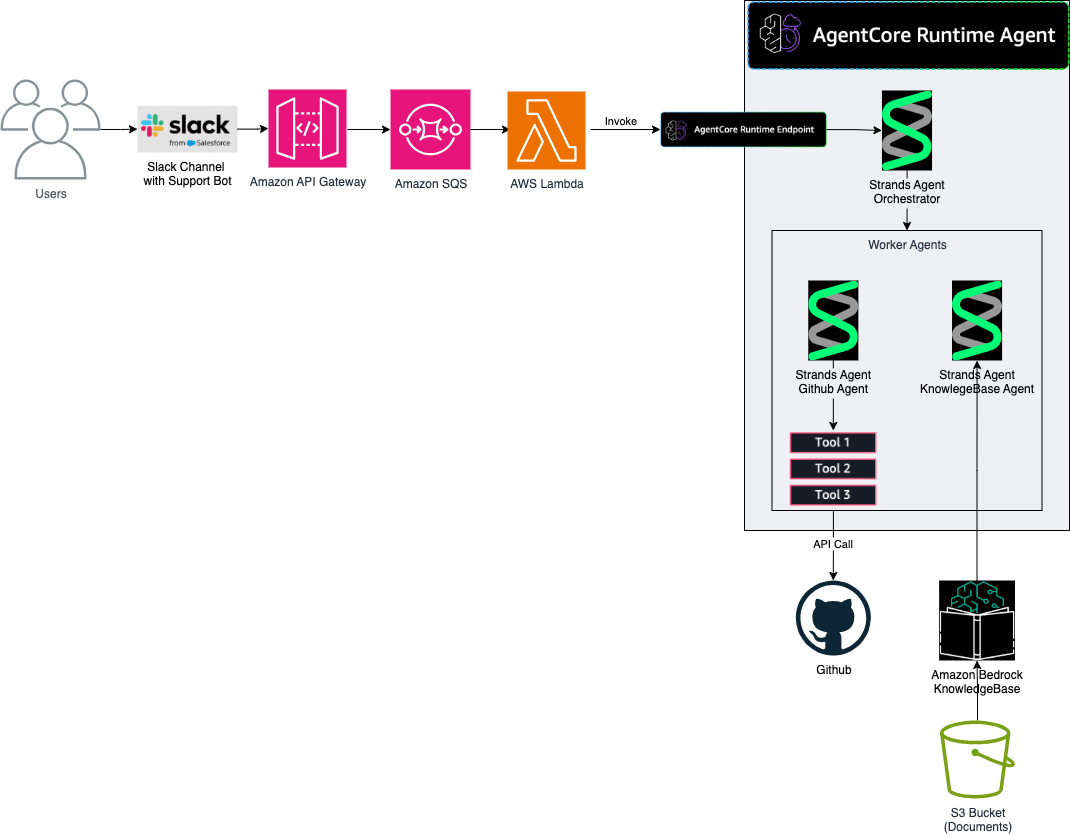
How AutoScout24 built a Bot Factory to standardize AI agent development with Amazon BedrockArtificial Intelligence In this post, we explore the architecture that AutoScout24 used to build their standardized AI development framework, enabling rapid deployment of secure and scalable AI agents.
In this post, we explore the architecture that AutoScout24 used to build their standardized AI development framework, enabling rapid deployment of secure and scalable AI agents. Read More

Generative AI tool helps 3D print personal items that sustain daily useMIT News – Machine learning “MechStyle” allows users to personalize 3D models, while ensuring they’re physically viable after fabrication, producing unique personal items and assistive technology.
“MechStyle” allows users to personalize 3D models, while ensuring they’re physically viable after fabrication, producing unique personal items and assistive technology. Read More
What Is a Knowledge Graph — and Why It MattersTowards Data Science How structured knowledge became healthcare’s quiet advantage
The post What Is a Knowledge Graph — and Why It Matters appeared first on Towards Data Science.
How structured knowledge became healthcare’s quiet advantage
The post What Is a Knowledge Graph — and Why It Matters appeared first on Towards Data Science. Read More

Avoiding Overfitting, Class Imbalance, & Feature Scaling Issues: The Machine Learning Practitioner’s NotebookKDnuggets Machine learning practitioners encounter three persistent challenges that can undermine model performance: overfitting, class imbalance, and feature scaling issues.
Machine learning practitioners encounter three persistent challenges that can undermine model performance: overfitting, class imbalance, and feature scaling issues. Read More
OpenAI partners with Cerebras OpenAI News OpenAI partners with Cerebras to add 750MW of high-speed AI compute, reducing inference latency and making ChatGPT faster for real-time AI workloads.
OpenAI partners with Cerebras to add 750MW of high-speed AI compute, reducing inference latency and making ChatGPT faster for real-time AI workloads. Read More